Processing of Large Document Collections: Exercise 3.
Solution for Exercise 3.1
In this exercise, we study a boosting algorithm called AdaBoost. On slide 19 (23 March 2006, on the weak learner) it is mentioned that "a term is chosen that minimizes either epsilon(t) or 1 - epsilon(t)", where epsilon(t) is calculated like on slide 18. Thus, a term with an error 0.8, for instance, can be chosen, if there is no term with error smaller than 0.2 in the terms. What happens later in the process (updating of weights, in the final classifier) if a chosen term has a large error? Why is it useful to choose this kind of term?
Schapire, Singer, and Singhal, Boosting and Rocchio Applied to Text Filtering Proceedings of SIGIR-98, the 21st ACM International Conference on Research and Development in Information Retrieval.
The algorithm of AdaBoost runs as described in Figure 1. The gist of the of the story is: Given a set of labeled documents, the algorithm constructs a classifier by adding simple classifiers to it incrementally. A simple classifier, i.e., a weak hypothesis hs, can be as simple as "if term t occurs in the document d, then d is relevant (+1), and otherwise, it is irrelevant (-1)". The algorithm maintains a distribution D of weights (probability of misclassifying a document) over the training collection. The distribution always adds up to 1. Since the distribution reflects the probability of misclassifying a randomly drawn document, the documents that produce most errors with weak learners produce higher weights.

In Figure 1, the selection of a simple classifier (weak learner) is done in Step 1. A classifier, as said, can be a simple test for the occurrence of a term. A term can be a single word, a phrase or an n-gram. Then, for each term, the weak learner calculates the error rate as a sum of false alarms and misses which are weighted with respect to the distribution D. For example,
e( t ) = SUM (t occurs in i, i is not relevant ) Ds(i) + SUM (t does not occur in i, i is relevant) Ds(i)
In the above formula, the first SUM calculates the distribution weight Ds(i) for document i on round s, given that the term t occurs in document i and that i is not relevant. Because the classifier is simple, it will consider all documents with term t relevant, and now that document i is not relevant, the classifier sets off a false alarm. The weights of the missed documents are summed up in the second SUM in a similar fashion: a document does not have the term t although it is relevant.
Usually, we want to use the terms that produce classification errors the least. But in classification, in addition to recognizing class C, we also want to recognize the class NOT_C. Were we classifying news, for instance, our classifier would try to recognize Sports-related news reports based on the features they have AND also based on features they don't have. If none or only a minority of the Sports news reports contain words like "regime" or "election", they differentiate Sports reports from other news reports. These words are negative evidence of the sports category. In addition to low-error terms, we want high-error terms. Basically, this is similar to Information Gain in the previous exercise.
Thus, we are looking for terms that minimize either e(t) or 1 - e(t). [Paradoxically, it would be theoretically possible to build a classifier from words that do not occur in class C. In this kind of unlikely case, the class of Sports would be defined by not having terms "regime", "election", ... . A cubist void. ]
Suppose the term "election" has error rate of 0.8 when filtering sports news. All other terms with error rates higher than that or lower than 0.2 have already been processed, so we form a hypothesis hsbased on the term "election" as follows: if term t (= "election") occurs in a document, assign it to relevants (+1), non-relevants (-1) otherwise.
Step 2. (Figure 1.) computes the error-rate of the chosen hypothesis. It is merely a sum of those document weights that were misclassified. For example, where the decision given by the hypothesis is not the same as the document label, hs( di ) != yi .
The alpha becomes negative with error-rates greater than 0.5. Here we compute the values of alpha, exp(-alpha) and exp(alpha) for various error-rates. The further we get away from the error 0.5, the greater the absolute value of alpha will be.
e alpha(e) exp(-alpha(e)) exp(alpha(e)) ---------------------------------------------------- 0.0001 4.61 0.01 99.99 0.10 1.10 0.33 3.00 0.20 0.69 0.50 2.00 0.30 0.42 0.65 1.53 0.40 0.20 0.82 1.22 0.50 0.00 1.00 1.00 0.60 -0.20 1.22 0.82 0.70 -0.42 1.53 0.65 0.80 -0.69 2.00 0.50 0.90 -1.10 3.00 0.33 0.9999 -4.61 99.99 0.01
Out of curiosity, we plot the same functions. The exponents are always positive and depending on the sign, they're less than one when the error value is less than 0.5.
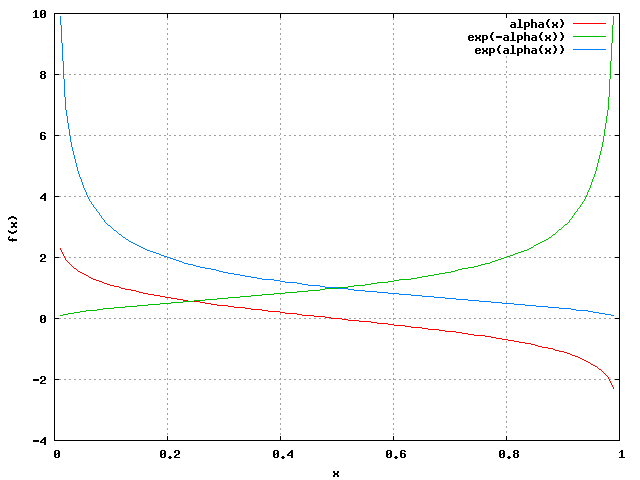
If the alpha is negative, it will decrease the score of a document if correctly classified. The multiplication hs(di) * yi is positive when they the decision and the label are the same, negative when they differ. If the classifier makes an error, we use exp( alpha ), and exp( -alpha ) otherwise. Thus, if the alpha is positive (if error-rate is less than 0.5), the correctly classified document weight will be multiplied by the value of exp(-alpha(e)) < 1, so that the weight decreases.
The term "election" had error-rate of 0.8, which makes it fairly accurate. We calculate an alpha for it: alpha(0.8) = 0.5 * ln( 0.2/0.8 ) = 0.5 * ln ( 0.25 ) = 0.5 * ( -1.39 ) = -0.69.
Then we go through the training corpus classifying it with our "election" classifier. Each document weight is updated. Suppose we made a misclassification: exp( -(-0.69) ) = 2.00. Thus the weight of the misclassified document increases. If we classify correctly, the multiplier is only exp( - 0.69 ) = 0.5, so the weight decreases.
Why do we stress the misclassified documents? Because we are minimizing errors.
Solution for Exercise 3.2
Exercises 2 and 3 are based on the article Kupiec, Pedersen, Chen: A trainable document summarizer. Proceedings of the 18th ACM-SIGIR Conference, p. 68-73, 1995. Also Chapter 5 (p.55-60) in Advances in automatic text categorization, eds. Mani, Maybury. The MIT Press, 1999. [Local copy (PDF)]
This paper was also discussed in the lectures.
Data for the following exercises
- A set of sentences: in the same file both a training set and a test set.
- The thematic words for the training set. The thematic words in the test set. (You don't really need these sets, but you might want to check them to see which words are considered important in the scoring.)
In this exercise we study the method described in the paper more detailly. To simplify the approach, only three of the features are selected. They are described (and interpreted) below:
Coding of the information: s the sentence belongs to the set S n the sentence does not belong to S H the sentence belongs to HighScores L the sentence does not belong to HighScores * separates paragraphs
As an example, we are provided with F1: Sentence Length Cut-off Feature calculations and a hint about the Bayes' rule:
P1(0) = 8/66 = 0.12 (8 sentences of 66 sentences have <= 7 words)
P1(1) = 58/66 = 0.88 (58 sentences of 66 sentences have > 7 words)
P1(0 | s belongs to S) = 2/16 = 0.12 (2 summary sentences are short)
P1(1 | s belongs to S) = 14/16 = 0.88 (14 summary sentences are long)
P(s' belongs to S | 0,i,0) using the Bayes' rule:
P(s belongs to S | F1,F2,F3) = P(F1 | s belongs to S) *
P(F2 | s belongs to S) *
P(F3 | s belongs to S) *
P(s belongs to S) /
P(F1)P(F2)P(F3)
F2: Sentences in a paragraph are distinguished according to whether they are paragraph-initial (i), paragraph-final (f), or paragraph-medial (m).
F2(s) = i if sentence s is the first sentence in a paragraph
F2(s) = f if there are at least two sentences in a paragraph, and
s is the last one
F2(s) = m if there are at least three sentences in a paragraph, and
s is neither the first nor the last sentence
Now the probabilities for each value:
P(i): 18/66 = 0.27 P(f): 33/66 = 0.50 P(m): 15/66 = 0.23 P(i| s belongs to S): 9/16 = 0.56 P(f| s belongs to S): 2/16 = 0.13 P(m| s belongs to S): 5/16 = 0.31
F3: The most frequent content words are defined as thematic words. A set of thematic words have been selected for both the training set (13 words) and the test set (9 words). Each sentence is scored as a function of frequency (= sum of the frequencies of the thematic words contained in the sentence). A set of highest scoring sentences are selected to a set HighScores.
F3(s) = 0 if sentence s belongs to HighScores F3(s) = 1 if sentence s does not belong to HighScores
There are 66 sentences in the training set and 37 sentences in the test set.The possible values for F3 with corresponding propabilities are thus:
P3(0) = 9/66 = 0.14 P3(1) = 57/66 = 0.86 P3(0 | s belongs to S) = 1/9 = 0.11 P3(1 | s belongs to S) = 8/9 = 0.89
The probabilities of each sentences belonging to the summary is as follows: (of course it suffices to calculate the probability once for each combination F1 F2 F3)
P(s1 in S|1,i,0) = ( 0.88 * 0.56 * 0.11 * 0.24 ) / ( 0.88 * 0.27 * 0.14 ) = 0.39 P(s2 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86) = 0.15 P(s3 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86) = 0.15 P(s4 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86) = 0.15 P(s5 in S|1,f,1) = ( 0.88 * 0.125 * 0.89 * 0.24 ) / ( 0.88 * 0.23 * 0.86 ) = 0.14 P(s6 in S|1,i,1) = ( 0.88 * 0.56 * 0.89 * 0.24 ) / ( 0.88 * 0.27 * 0.86 ) = 0.51 P(s7 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86) = 0.15 P(s8 in S|0,m,1) = ( 0.12 * 0.31 * 0.89 * 0.24 ) / ( 0.12 * 0.5 * 0.86) = 0.15 P(s9 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 *0.86) = 0.15 P(s10 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s11 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s12 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s13 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s14 in S|1,f,1) = ( 0.88 * 0.125 * 0.89 * 0.24 ) / ( 0.88 * 0.23 * 0.86 ) = 0.14 P(s15 in S|1,i,1) = ( 0.88 * 0.56 * 0.89 * 0.24 ) / ( 0.88 * 0.27 * 0.86 ) = 0.51 P(s16 in S|1,f,1) = ( 0.88 * 0.125 * 0.89 * 0.24 ) / ( 0.88 * 0.23 * 0.86 ) = 0.14 P(s17 in S|1,i,1) = ( 0.88 * 0.56 * 0.89 * 0.24 ) / ( 0.88 * 0.27 * 0.86 ) = 0.51 P(s18 in S|1,f,0) = ( 0.88 * 0.125 * 0.11 * 0.24 ) / ( 0.88 * 0.23 * 0.14 ) = 0.11 P(s19 in S|1,i,1) = ( 0.88 * 0.56 * 0.89 * 0.24 ) / ( 0.88 * 0.27 * 0.86 ) = 0.51 P(s20 in S|1,m,0) = ( 0.88 * 0.31 * 0.11 * 0.24 ) / ( 0.88 * 0.5 * 0.14 ) = 0.12 P(s21 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s22 in S|1,f,0) = ( 0.88 * 0.125 * 0.11 * 0.24 ) / ( 0.88 * 0.23 * 0.14 ) = 0.11 P(s23 in S|1,i,1) = ( 0.88 * 0.56 * 0.89 * 0.24 ) / ( 0.88 * 0.27 * 0.86 ) = 0.51 P(s24 in S|1,m,0) = ( 0.88 * 0.31 * 0.11 * 0.24 ) / ( 0.88 * 0.5 * 0.14 ) = 0.12 P(s25 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s26 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s27 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s28 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s29 in S|1,f,1) = ( 0.88 * 0.125 * 0.89 * 0.24 ) / ( 0.88 * 0.23 * 0.86 ) = 0.14 P(s30 in S|1,i,1) = ( 0.88 * 0.56 * 0.89 * 0.24 ) / ( 0.88 * 0.27 * 0.86 ) = 0.51 P(s31 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s32 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s33 in S|1,m,1) = ( 0.88 * 0.31 * 0.89 * 0.24 ) / ( 0.88 * 0.5 * 0.86 ) = 0.15 P(s34 in S|1,f,1) = ( 0.88 * 0.125 * 0.89 * 0.24 ) / ( 0.88 * 0.23 * 0.86 ) = 0.14 P(s35 in S|1,i,1) = ( 0.88 * 0.56 * 0.89 * 0.24 ) / ( 0.88 * 0.27 * 0.86 ) = 0.51 P(s36 in S|1,m,0) = ( 0.88 * 0.31 * 0.11 * 0.24 ) / ( 0.88 * 0.5 * 0.14 ) = 0.12 P(s37 in S|1,f,1) = ( 0.88 * 0.125 * 0.89 * 0.24 ) / ( 0.88 * 0.23 * 0.86 ) = 0.14
In the order of occurrence, the six sentences with the highest scoring are:
s6 (1,i,1 [s])
Another group of schemes aims to use satellites to offer
high-capacity Internet access anywhere in the world.
s15 (1,i,1 [s])
The magic of competition works just as well in developing
countries as in developed ones.
s17 (1,i,1 [n])
Asia-Pacific stands out as the realm of new operators.
s19 (1,i,1 [n])
These new entrants have had an unexpected effect.
s23 (1,i,1 [n])
As for the new entrants, they have one huge advantage and face
one huge threat.
s30 (1,i,1 [s])
The threat is the power of the incumbent monopoly over prices.
s35 (1,i,1 [s])
So the new entrants usually nestle in under the lee of the
giant, making a tidy living, but ensuring that their hefty
rival does so too.
Solution for Exercise 3.3
Evaluate the results you got in the exercise 1.
Compare your set of summary sentences to the set of sentences marked-up with 's' in the test set. Calculate precision and recall.
Select from your result set 7 (or 8) best scoring sentences (instead of 6). Do the precision and recall change?
What is your own subjective evaluation of the quality of the summary?
Relevants = 7
6 best:
3
recall = --- = 0.429
7
3
precision = --- = 0.500
6
7 best:
4
recall = --- = 0.571
7
4
precision = --- = 0.571
7
Last modified 28 Apr 2006.