Tämä materiaali on lisensoitu Creative Commons BY-NC-SA-lisenssillä, joten voit käyttää ja levittää sitä vapaasti, kunhan alkuperäisten tekijöiden nimiä ei poisteta. Jos teet muutoksia materiaaliin ja haluat levittää muunneltua versiota, se täytyy lisensoida samanlaisella vapaalla lisenssillä. Materiaalien käyttö kaupalliseen tarkoitukseen on ilman erillistä lupaa kielletty.
Web-palvelinohjelmointi
Materiaali
Tehtävät
Lukijalle
Tämä materiaali on tarkoitettu Helsingin yliopiston tietojenkäsittelytieteen laitoksen syksyn 2013 kurssille Web-palvelinohjelmointi. Materiaaliin on vaikuttanut vahvasti Helsingin yliopistossa aiemmin järjestetyt kurssit Web-palvelinohjelmointi (syksy 2012) sekä Web-sovellusohjelmointi (kevät 2012), sekä niistä saatu palaute. Materiaalin kirjoittaja on Arto Vihavainen ja sen syntyyn ovat vaikuttaneet useat tahot, joista tärkeimmät ovat Matti Luukkainen ja Mikael Nousiainen.
Materiaali päivittyy kurssin edetessä ja sisältää myös kurssiin liittyvät tehtävät. Tehtävien lisäksi materiaali sisältää kysymysmerkillä merkittyjä pohdi-kohtia, joissa pääsee pohtimaan juuri tutuksi tullutta asiaa esimerkin kautta. Lampuilla merkityt kohdat taas sisältävät mm. arvokkaita vinkkejä erilaisista työkaluista.
Lue materiaalia siten, että teet samalla itse kaikki lukemasi esimerkit. Esimerkkeihin kannattaa tehdä pieniä muutoksia ja tarkkailla, miten muutokset vaikuttavat ohjelman toimintaan. Äkkiseltään voisi luulla, että esimerkkien tekeminen ja muokkaaminen hidastaa opiskelua. Tämä ei kuitenkaan pidä ollenkaan paikkansa. Oppiminen perustuu oleellisesti aktiiviseen tekemiseen ja rutiinin kasvattamiseen. Esimerkkien ja erityisesti omien kokeilujen tekeminen on parhaita tapoja sisäistää luettua tekstiä. Esimerkkejä tehdessä kannattaa kirjoittaa ne itse. Koodin copy-paste ei ole oppimisen kannalta yhtä tehokasta kuin itse kirjoittaminen.
Pyri tekemään tai ainakin yrittämään tehtäviä sitä mukaa kuin luet tekstiä. Jos et osaa heti tehdä jotain tehtävää, älä masennu, sillä saat ohjausaikoina neuvoja tehtävien tekemiseen.
Tekstiä ei ole tarkoitettu vain kertaalleen luettavaksi. Joudut varmasti myöhemmin palaamaan aiemmin lukemiisi kohtiin tai aiemmin tekemiisi tehtäviin. Tämä teksti ei sisällä kaikkea oleellista web-palvelinohjelmointiin liittyvää. Itse asiassa ei ole olemassa mitään kirjaa josta löytyisi kaikki oleellinen. Eli joudut joka tapauksessa ohjelmoijan urallasi etsimään tietoa myös omatoimisesti. Harjoitukset sisältävät jo jonkun verran ohjeita, mistä suunnista ja miten hyödyllistä tietoa on mahdollista löytää.
Jos (ja kun) materiaalista löytyy esimerkiksi kirjoitusvirheitä, raportoikaa niistä esimerkiksi IRCNetissä olevalla kurssikanavalla #wadup. Tähän mennessä apua ovat tarjonneet muun muassa nimimerkit Zeukkari, BiQ, vaakapallo, danu, smu, hubbard, Juusoh, gleant, Pro|, Boogina, arrayn, kazenokage, deiga ja Drasa. Kiitos heille! Materiaaliin liittyvistä ehdotuksista ja ajatuksista tulee kiittää myös muun muassa Kasper Hirvikoskea ja Hansi Keijosta; erityinen kiitos kuuluu myös TMC:n isälle, Martin Pärtelille, joka on mahdollistanut TMC:n käytön kurssilla.
Web-sovelluksista yleisesti
Web-sovellukset koostuvat selain- ja palvelinpuolesta. Käyttäjän koneella toimii selainohjelmisto (esim. Google chrome), jonka kautta käyttäjä tekee pyyntöjä verkossa sijaitsevalle palvelimelle. Kun palvelin vastaanottaa pyynnön, se käsittelee pyynnön ja rakentaa pyynnölle sopivan vastauksen. Vastaus voi sisältää esimerkiksi web-sivun tai tietyssä muodossa olevaa dataa.
Selainohjelmointiin ja käyttöliittymäpuoleen keskityttäessä painotetaan rakenteen, ulkoasun, ja toiminnallisuuden erottamista toisistaan. Karkeasti voidaan sanoa, että sivun rakenne määritellään HTML-tiedostoilla, ulkoasu CSS-tiedostoilla, ja toiminnallisuus JavaScript-tiedostoilla.
Palvelinpuolen toiminnallisuutta toteutettaessa keskitytään tyypillisesti selainohjelmiston tarvitsevan "APIn" suunnitteluun ja toteutukseen, datan tallentamiseen ja käsittelyyn, sekä sellaisten laskentaoperaatioiden toteuttamiseen, joita selainohjelmistossa ei kannata tai voi tehdä.
Web-sovelluksista puhuttaessa on hyvä erottaa staattiset ja dynaamiset sivut toisistaan. Staattiset sivut ovat sivuja, joiden sisältö on ennalta määrätty, ja jotka palvelin palauttaa suoraan käyttäjälle niitä pyydettäessä. Dynaamiset sivut ovat taas sivuja, joihin palvelin lisää dataa tarvittaessa. Esimerkiksi osoitteessa http://telkku.com/ toimiva web-sovellus luo näytettävän televisio-ohjelmiston dynaamisesti palvelinpuolella: uuden sivun luominen käsin aina uuden ohjelmatiedon saapuessa olisi erittäin raskasta ja tehotonta. Sivuston tarjoama hakupalvelu mahdollistaa rajattoman määrän erilaisia sivustoja; kukaan ei kirjoittaisi näitä käsin.
Työpöytäsovelluksia ja web-sovelluksia verrattaessa työpöytäsovellukset tarjoavat enemmän interaktiivisuutta ja nopeutta web-sovelluksiin verraten. Web-sovellukset toisaalta mahdollistavat saumattomat ohjelmistojen päivitykset, helposti jaettavan ja ylläpidettävän datan ja dokumenttien jakamisen, sekä kevyet käyttöliittymät. Olemme todistamassa muutosta, missä web-sovellukset hiljalleen syrjäyttävät perinteiset työpöytäsovellukset. Tälläkin hetkellä Google tarjoaa kaikille ilmaista toimistotyökalupakettia, elokuvien ja tv-ohjelmien katsominen selainohjelmistossa on helppoa esimerkiksi Yle Areenan tai Netflixin avulla, ja selaimessa pelattavat pelit ovat ohittaneet perinteiset tietokonepelit käyttäjämäärissä jo muutamia vuosia sitten.
Web-sovellusten kehittäminen
Ohjelmistojen kehittämistä verrataan usein naiivisti talojen tai rakennusten rakentamiseen. Taloa suunnitellessa arkkitehdillä on selkeä tehtävä ja etenemissuunnitelma: kerää vaatimukset, tutki vaihtoehtoja, ja luo pohjapiirrustus. Kun arkkitehti on luonut pohjapiirrustuksen, se annetaan urakoitsijalle, jonka pohjalta urakoitsijan palkkaamat työntekijät -- rakennusmiehet -- rakentavat rakennuksen vaadituilla materiaaleilla.
Ohjelmistoja suunniteltaessa arkkitehti osallistuu sekä ohjelmiston suunnitteluun että kehitykseen, eli rakentamiseen. Koska ohjelmistoista halutaan mahdollisimman nopeasti konkreettista palautetta, arkkitehti aloittaa ohjelmiston suunnittelun perustarpeista: muutamasta huoneesta, joihin palautetta antavat ihmiset muuttavat. Kun alkuperäinen suunnitelma on lähes valmis, rakennukseen muuttaa lisää ihmisiä, jotka tarvitsevat rakennukselta uusia toiminnallisuuksia. Ensisijaisina vaatimuksina ovat uudet huoneet, pesula, disko ja luonnollisesti oleskelutila, jossa on tilaa biljardipöydälle.
Tällöin arkkitehti soveltaa alkuperäistä suunnitelmaansa mukauttamaan uudet ihmiset ja kehitystyö jatkuu. Kehitystyön jatkuessa alkuperäiset asukkaat alkavat valittamaan rakennusmelusta ja uhkaavat poismuutolla jos asioihin ei saada muutosta, aiheuttaen hiusten harvenemista arkkitehdille. Toisaalta, sana uudesta biljardipöydästä kiertää, ja yhä enemmän ihmisiä muuttaa rakennukseen, ja rakennukselta vaaditaan taas uusia huoneita sekä cartingrata ja curlinghalli.
Hyvän suunnittelun perusta on mahdollisuuksien huomiointi. Huomioinnilla ei tarkoiteta sitä, että rakennetaan heti aluksi iso järjestelmä -- käytännössä järjestelmän valmistuessa sille ei olisi käyttäjiä sillä kaikki olisivat siirtyneet toiseen aiemmin tarpeellisia ominaisuuksia tarjonneeseen järjestelmään. Jos alkuperäinen suunnitelma tekee järjestelmän laajentamisesta vaikeaa, käyttäjät saattavat vaihtaa palvelua hitauden takia.
Kaikkien osapuolten toiveet tyydyttävän ohjelmiston rakentaminen on haastavaa. Jokaista ohjelmistoa joudutaan laajentamaan, rajaamaan ja muokkaamaan. Asiakkaalla tai asiakkailla on käytännössä aina uusia toivomuksia ohjelmiston elinkaaren varrella.
Arkkitehtuurin tulee mahdollistaa sopivan kokoisesta palasta aloittaminen sekä rakennettavan sovelluksen laajentaminen, myös toisten kehittäjien toimesta. Käytännössä hyvin harvat ohjelmistot ovat vain yhden ihmisen käsialaa, ja laajempaa sovellusta kehitettäessä olemassaolevien ohjelmistokomponenttien hyödyntäminen on oleellista. Ohjelmistoalalla aloittelevan on hyvin vaikea valita sopivia komponentteja olemassaolevasta viidakosta sillä yhtä oikeaa ratkaisua ei yleensä ole.
Oleelllisinta ohjelmistokehityksessä on kommunikointi niin koodin kautta kuin muita väyliä käyttäen. Avoimeen lähdekoodiin ja online-versionhallintatyökaluihin (esim. GitHub) perustuvat projektit saavat ihmiset eri puolilta maailmaa tekemään työtä yhteisten kiinnostuksenkohteiden takia. Sovittujen käytänteiden (esim. nimeämiskäytänteet, versionhallinta, testaus, dokumentointi ym.) noudattaminen on oleellista sillä heikko suunnittelu ja ylläpidettävyys, esimerkiksi muuttujien huono nimentä, aiheuttavat lähinnä kylmiä väreitä ja ajavat innokkaat ihmiset pois.
Työkaluja valittaessa tarkoituksena on välttää nurkkaan ajautumista: työkaluista tulee pystyä myös pääsemään eroon. On paljon hyödyllisempää miettiä päivä ja käyttää muutama päivä prototyypin tekemiseen, koska prototyyppiä voidaan parantaa kuukausia, kuin miettiä kuukausi ja sitouttaa itsensä kuukauden aikana luotuun suunnitelmaan. Mitä nopeammin toiminnallisuutta on olemassa, sitä nopeammin siitä saa palautetta. Toisaalta, mitä vähemmän aikaa yksittäisen toiminnallisuuden toteuttamiseen käytetään -- KISS -- sitä helpommin siitä voi tarpeen vaatiessa hankkiutua eroon.
Kurssilla käytettävät työvälineet
Tällä kurssilla käytämme ohjelmointiympäristönä NetBeansia, ohjelmistoprojektien ja komponenttien riippuvuuksien hallintaan Mavenia, sekä luonnollisesti komentotulkkia. Harjoitustehtävät palautetaan TestMyCode-palvelimelle NetBeansiin ladattavan TMC-liitännäisen avulla.
Seuraavassa katsotaan miten TMC-liitännäinen hankitaan NetBeansiin.
Ohjelmointiympäristö: NetBeans
Ohjelmointiympäristöt tarjoavat kokoelman hyödyllisiä apuvälineitä usein toistuviin tapahtumiin, kuten ohjelmointiprojektien luomiseen, projektin paketointiin ym. Ohjelmointiympäristön tai tuottavuutta yhtä paljon helpottavan työkalun käyttäminen on suositeltavaa. Vaikka ohjelmointiympäristön käyttö voi aluksi tuntua vaikealta, pääset myöhemmin nostamaan käyttämäsi ajan korkoina.
Esimerkeissä ja tehtävissä oletetaan että käytössäsi on NetBeansin versio 7.3.1 (tai uudempi) ja TMC.
TMC
TMC on NetBeans-liitännäinen, jonka avulla kurssin tehtävät voidaan ladata suoraan ohjelmointiympäristöön. Joidenkin tehtävien mukana tulee kurssihenkilökunnan kirjoittamia opiskelijaa ohjaavia testejä, jotka testaavat toteutusta ja auttavat ohjelmointiprosessissa eteenpäin. Saat eniten kurssista irti jos pyrit tekemään tehtäviä useampana päivänä, sekä hyödynnät ohjausaikoja, jolloin kurssihenkilökunta on läsnä tukemassa etenemistäsi. Ohjausajat löytyvät kurssisivulta.
NetBeansin ja TMCn asennus
Seuraavaksi laitetaan TMC ja NetBeans kuntoon sekä palautetaan ensimmäinen tehtävä TMC-palvelimelle.
TMC-käyttäjätunnuksen luominen
TMC on ohjelmointiympäristöön tarjottavan toiminnallisuuden lisäksi tehtävien palautukseen ja kurssin hallinnointiin käytettävä järjestelmä (voit siis palauttaa tehtävät myös TMC:n web-sivun kautta, vaikka se ei olekaan suositeltavaa). TMC:n web-sivu löytyy osoitteesta http://tmc.mooc.fi/hy. Kun avaat sivun, näet seuraavanlaiset yläosan.
Valitse ylälaidasta Sign up ja kirjaudu järjestelmään. Käytä käyttäjätunnuksena (username) opiskelijanumeroasi, ja anna järjestelmään käyttämäsi sähköpostiosoite. Opiskelijanumeron käyttö on erityisen tärkeää: näin tehtävistä saamasi pisteet voidaan liittää sinuun kurssin arvostelussa. Huom! Älä käytä salasanana mitään olemassaolevaa salasanaasi!
Kun käyttäjätunnuksesi on luotu ja kirjautuminen onnistuu, jatka eteenpäin.
NetBeans
Huom! Oletamme että käytössäsi on NetBeansin versio 7.3.1 tai uudempi. NetBeans-sovelluskehitysympäristön ladattua osoitteesta http://netbeans.org/. NetBeansin versiota ladattaessa kannattaa valita versio kaikilla mausteilla, eli vaihtoehto "All".
Huom! Jos NetBeans kysyy haluatko käyttää vanhoja asetuksia sitä käynnistettäessä, kannattaa valita ei.
TMCn asentaminen
TMC lataa kurssin tehtävät suoraan ohjelmointiympäristöön ja tarjoaa mahdollisuuden tehtävien lähettämiseen ja tarkistamiseen suoraan ohjelmointiympäristöstä.
TMC-liitännäisen saa lisättyä NetBeansin pluginvaihtoehdoksi näkyviin valitsemalla Tools -> Plugins. Valitse avautuvasta ikkunasta Settings-välilehti, ja klikkaa uuden liitännäispaikan lisäämiseen tarkoitettua Add-nappia.
Anna avautuvaan ikkunaan nimeksi TMC, ja osoitteeksi http://update.testmycode.net/tmc-netbeans_hy/updates.xml. Valitse lopulta OK.
Mene tämän jälkeen Available Plugins -välilehdelle ja etsi sieltä vaihtoehto Test My Code NetBeans Plugin, klikata sen vasemmalla puolella olevaa laatikkoa, ja painaa Install. Tämä asentaa TMC:n käyttöösi.
Kun TMC on asentunut, se pyytää käynnistämään NetBeansin uudestaan. Käynnistä NetBeans uudestaan. Tämän jälkeen NetBeansin valikossa on myös vaihtoehto TMC. Käy vielä asettamassa TMCn asetukset. Valitse TMC -> Settings, ja täytä avautuvaan ikkunaan tietosi. Käyttäjätunnus on opiskelijanumerosi, salasanasi TMC:hen liittyvä salasanasi. Valitse kurssiksi s2013-wepa.
Varmista että myös alaosassa olevat vaihtoehdot ovat valittuina ja paina OK (kurssin kehittämisen kannalta on erittäin tärkeää, että viimeinen vaihtoehto "Send snapshots of your progress for study" on valittu). Tämän jälkeen NetBeans kysyy sinulta ladataanko saatavilla olevat tehtävät. Valitse "Download".
NetBeans lataa tehtävät, jonka jälkeen ne ovat näkyvissä NetBeans-projekteina. Pieni musta pallo projektin ikonissa tarkoittaa että tehtävää ei ole vielä yritetty. Jos pallo on vihreä, on tehtävästä kerätty kaikki pisteet.
Ensimmäisen tehtävän palautus
Kun avaat projektin, siihen liittyvät toiminnallisuudet aktivoituvat. Alla olevassa kuvassa hiiren näyttämä nappi suorittaa tehtävään liittyvät paikalliset testit. Ensimmäiseen tehtävään ei liity muuta tekemistä kuin sen testaaminen ja lähettäminen. Paina nappia.
Kun painat nappia, TMC suorittaa tehtävään liittyvät testit, joiden pitäisi mennä läpi. Kun tehtävään liittyvät testit menevät läpi, näet ikkunan joka kysyy "lähetetäänkö tehtävä palvelimelle?". Kun valitset kyllä, TMC lähettää tehtävän tehtäväpalvelimelle tarkastettavaksi.
Tämän jälkeen TMC suorittaa vielä tehtävään liittyvät testit palvelimella. Kun kaikki on OK, TMC ilmoittaa tehtävästä kerätyt pisteet. Huh! Onneksi olkoon! Olet kerännyt ensimmäiset pisteesi.
Vinkki!
Jos et näe tehtävän W1E01.EasyPoints kuvaketta sinertävänä pallona, hae käyttöösi Java EE Base-Plugin NetBeansissa.
Ohjelmistoprojektien hallinta ja Maven
Jokaisessa ohjelmistoprojektissa tulee vastaan erilaisia lähdekoodiin liittyviä tavoitteita, joita kehittäjien tulee pystyä toteuttamaan. Lähdekoodia tulee pystyä paketoimaan tuotantopalvelimelle siirettäväksi paketiksi (esim -.jar ja -.war -tiedostot), lähdekoodiin liittyviä testejä tulee pystyä ajamaan erillisellä palvelimella ja lähdekoodista tulee pystyä generoimaan erilaisia raportteja sekä luonnollisesti dokumentaatiota.
Työkalut kuten Apache Ant auttavat projektiin liittyvän lähdekoodin hallinnoinnissa ja kääntämisessä. Ant on käytännössä 2000-luvun alun vastine perinteisille Makefile-tiedostoille. Nykyaikaisempi Apache Maven auttaa käännösprosessin lisäksi projektiin liittyvien kirjastoriippuvuuksien automaattisessa hallinnassa.
Apache Maven on projektinhallintatyökalu, jota voi käyttää ohjelmakoodikäännösten lisäksi lähes koko projektin elinkaaren hallintaan uuden projektin aloittamisesta lähtien. Maven tarjoaa ohjelmiston elinkaaren hallintaan joukon valmiiksi konfiguroituja vaiheita (phase), joita voidaan suorittaa komentoriviltä. Usein käytettäviä vaiheita ovat mm. test, joka suorittaa projektiin liittyvät testit sekä package, joka paketoi lähdekoodin projektityypistä riippuen sopivaan pakettiin. Oikeastaan Maven on sovelluskehys liitännäisten suoritukseen ja yksinkertaisimmatkin Mavenin tarjoamat toiminnot ovat toteutettu liitännäisinä.
Jokaisella Maven-projektilla on elinkaari, joka sisältää vaiheet lähtien projektin validoinnista, kääntämisestä ja testaamisesta aina tuotantoon siirtämiseen asti. Tarkempi listaus projektin erilaisista vaiheista löytyy Mavenin dokumentaatiosta. Kukin vaihe koostuu yhdestä tai useammasta tavoitteesta (goal), jotka suoritetaan vaiheen sisällä. Vaiheet riippuvat myös edellisistä vaiheista; esimerkiksi vaihetta test suoritettaessa Maven suorittaa ensin projektin validoinnin ja kääntämisen.
Mavenin liitännäisarkkitehtuuri mahdollistaa hyvin monipuolisen toiminnallisuuden. Esimerkiksi raportointia ja staattista koodianalyysiä varten löytyy omat liitännäiset, samoin kuin mahdollisen (web-)palvelimen käynnistämiselle projektin testausta varten. Liitännäisistä löytyy (ei kattava) lista osoitteessa http://maven.apache.org/plugins/index.html.
Maven automatisoi uusien projektien luomisen archetype-liitännäisellä. Archetype-liitännäisen avulla ohjelmistokehittäjät voivat tarjota toisilleen valmiita projektirunkoja ja esimerkiksi määritellä yrityksen teknologiavalinnat paketiksi, jonka pohjalta uuden sovelluksen kehittäminen on nopeaa.
Yksi Mavenin tärkeimmistä ominaisuuksista on tarvittavien kirjastojen eli riippuvuuksien automaattinen lataaminen. Mavenin avulla projektiin voi määritellä riippuvuuden esimerkiksi yksikkötestauskirjastoihin ja käytetyn web-sovelluskehyksen kirjastoihin. Tällöin Maven lataa riippuvuudet automaattisesti ja kirjastoja ei tarvitse pitää esimerkiksi paikallisessa versionhallintajärjestelmässä.
Mavenin projektirakenne
Mavenin archetype-pluginia käyttäen uuden projektin luonti tapahtuu helposti. Luodaan uusi projekti, jota tarkastelemme seuraavaksi. Uuden projektin luominen onnistuu komentoriviltä esimerkiksi seuraavan komennon avulla.
Käytännössä komennossa mvn archetype:generate kutsutaan Mavenin archetype-liitännäiseen liittyvää tavoitetta generate ja annetaan sille kaksi parametria. Parametrilla -DgroupId kerrotaan katto-organisaation tai ryhmän tunnus, parametrilla -DartifactId kerrotaan luotavan sovelluksen nimi.
Komento hakee archetype-pluginista valmit projektipohjat, ja kysyy ensin mitä pohjaa haluat käyttää. Tämän jälkeen Maven kyselee muita tietoja luotavasta projektista. Koska haluamme vain tutustua tässä Mavenin projektirakenteeseen, vastaillaan kysymyksiin enter-painalluksilla. Tällöin Maven käyttää oletusvastauksia.
Kun projekti on luotu, sillä on seuraavanlainen kansiorakenne. Kansiorakenteen saa kätevästi esille tree-komennon avulla.
$ tree
.
└── sovelluksen-nimi
├── pom.xml
└── src
├── main
│ └── java
│ └── fi
│ └── organisaatio
│ └── App.java
└── test
└── java
└── fi
└── organisaatio
└── AppTest.java
10 directories, 3 files
Sovelluksen ja testien lähdekoodit ovat eritelty erillisiin kansioihin. Projektin alla olevassa kansiossa src on projektiin liittyvät lähdekoodit. Kansion src alla on kansiot main ja test, joissa toisessa on projektiin liittyvää koodia, ja toisessa projektiin liittyvät testit. Maven-projektin konfiguraatiotiedosto pom.xml on projektin juuressa.
Projektin luominen valmiista archetype-projekstista onnistuu myös NetBeansissa. Valitsemalle File -> New Project pääsee projektivalikkoon, josta löytyy kategoria Maven.
Kun vaihtoehto "Project from Archetype" valitaan käyttäjä pääsee selaamaan saatavilla olevia vaihtoehtoja. Alla olevassa esimerkissä on etsitty archetypejä avainsanalla "spring".
Archetypen valinnan jälkeen projektille annetaan nimi ja aloitetaan sovelluksen kehittäminen. Tutustutaan kuitenkin vielä muutamaan asiaan tarkemmin...
Pikainen XML-kertaus
XML (Extensible Markup Language) on laitteistoriippumaton tapa tiedon tallentamiseen siten, että tallennusmuodossa välittyy myös tiedon rakenne. XML-dokumentteja käytetään mm. grafiikan (SVG), tekstidokumenttien (OOXML) ja erilaisten asetustiedostojen tallentamiseen.
Tiedoston pom.xml osa pom tulee sanoista Project Object Model. XML-muotoinen pom-tiedosto sisältää projektiin liittyvän rakenteen, asetukset, kirjastoriippuvuudet ja tarvittaessa määritellyt tavoitteet. Yksinkertaisimmillaan pom.xml -tiedosto sisältää kuvauksen organisaatiosta, projektin nimestä, versiosta ja lähdekoodin pakkausmuodosta. Edellisessä osiossa komentorivillä luodun projektin pom.xml -sisältö näyttää seuraavalta.
Alussa on xml-tiedoston otsake, joka määrittelee käytetyn XML-skeeman. Tämän jälkeen määritellään projektin tiedot (groupId = ryhmä, artifactId = projekti, version = projektin versio, packaging = pakkausmuoto). Tämän jälkeen tulee sovelluksen nimi (usein sama kuin projekti), sekä projektiin liittyvä osoite. Näitä seuraa projektiin liittyvät asetukset, yllä olevassa tiedostossa on määritelty että projekti käyttää UTF-8 -merkistökoodausta.
Dependencies-osiossa määritellään kirjastot, joita projekti tarvitsee. Esimerkissä projektille on määritelty riippuvuus yksikkötestauksessa käytettävään JUnit-sovelluskirjastoon, jonka Maven lataa automaattisesti. Riippuvuuden scope-osiolla voidaan määritellä vaihe, johon riippuvuus liittyy. Yllä olevassa esimerkissä JUnit-kirjastoa on käytössä vain test-vaiheessa. Käytännössä siis JUnit on käytössä vain testausta varten, mutta se ei tule olemaan mukana asiakkaalle lähetettävässä valmiissa sovelluksessa.
Riippuvuuksien hallinta
Projektikonfiguraatiossa (pom.xml) olevassa dependencies-osiossa määritellään projektin riippuvuudet. Riippuvuuksia ei ole pakko olla yhtäkään, tai niitä voi olla useita. Käytettävät kirjastot riippuvat usein myös muista kirjastoista. Maven (versiosta 2 lähtien) lataa automaattisesti myös käytettävien kirjastojen tarvitsemat riippuvuudet: esimerkiksi JUnit-kirjaston uusin versio tarvitsee avukseen hamcrest-nimisen kirjaston (kts. "This artifact depends on..." osoitteessa http://mvnrepository.com/artifact/junit/junit/4.11). Voimme kuitenkin määritellä riippuvuudeksi JUnit-kirjaston ja antaa Mavenin hoitaa loput.
Silloin tällöin riippuvuudet saattavat mennä ristiin. Esimerkiksi kirjasto A voi riippua kirjaston C versiosta 1.1, kun taas kirjasto B voi riippua kirjaston C versiosta 1.2. Tällä hetkellä Maven päättelee käytettävän kirjaston riippuvuuksien järjestyksen perusteella. Esimerkiksi alla olevassa konfiguraatiossa kirjastosta C käytettäisiin versiota 1.1 koska riippuvuus kirjastoon A on ennen riippuvuutta kirjastoon B.
Riippuvuuksia voi sulkea pois exclusions-tagin avulla. Alla kirjaston A riippuvuutta kirjasto C ei ladattaisi ollenkaan, jolloin kirjaston B määrittelemä riippuvuus pääsee käyttöön.
Riippuvuudet ladataan valmiiksi määritellyistä kirjastovarastoista eli repositorioista. Käytännössä Mavenilla on muutamia oletuspaikkoja kirjastojen hakemiseen, mutta niitä voi myös konfiguroida lisää. Esimerkiksi harjoitustehtävissä olevissa konfiguraatioissa on määritelty TMC:n käyttämä repository TMC:hen liittyvien kirjastojen lataamiseen seuraavasti.
Kirjoittaessamme pom.xml-tiedoston sisältävässä kansiossa komennon mvn, näemme viestin, joka valittaa komennon puuttumisesta. Viestin konkreettinen sisältö riippuu mavenin versiosta, esimerkiksi mavenin versiossa 2 oleellinen sisältö on seuraavanlainen. Kolmosversiossa viesti on vaikealukuisempi...
$ mvn
...
You must specify at least one goal or lifecycle phase to perform build steps.
The following list illustrates some commonly used build commands:
mvn clean
Deletes any build output (e.g. class files or JARs).
mvn test
Runs the unit tests for the project.
mvn install
Copies the project artifacts into your local repository.
mvn deploy
Copies the project artifacts into the remote repository.
mvn site
Creates project documentation (e.g. reports or Javadoc).
Please see
http://maven.apache.org/guides/introduction/introduction-to-the-lifecycle.html
for a complete description of available lifecycle phases.
...
Projektiin liittyvät testit suoritetaan käyttämällä mavenin vaihetta test. Käytännössä kukin vaihe liittyy johonkin tiettyyn pluginiin, esimerkiksi test-vaiheessa suoritetaan surefire-pluginin tavoite test. Lisätietoja vaiheiden oletusplugineista löytyy täältä.
Suoritetaan testit antamalla projektikansiossa komento mvn test (saman voi tehdä myös NetBeansissa valitsemalla projektin oikealla hiiren napilla ja painamalla "Test").
$ mvn test
// tulostusta...
[INFO] ------------------------------------------------------------------------
[INFO] Building sovelluksen-nimi 1.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
// tulostusta...
-------------------------------------------------------
T E S T S
-------------------------------------------------------
Running fi.organisaatio.AppTest
Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.016 sec
Results :
Tests run: 1, Failures: 0, Errors: 0, Skipped: 0
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
// tulostusta
Käytännössä projektiin liittyvät testitiedostot, joita komentorivin kauttaluomassamme esimerkkiprojektissa on vain 1, suoritetaan. Jos testeissä on ongelmia, mavenista pääsee käsiksi niihin liittyviin raportteihin.
Projektin konfiguraation muokkaus on helppoa kun tietää mitä tekee. Esimerkiksi yksikkötestauskirjaston JUnit version vaihtaminen vanhasta versiosta 3.8.1 versioon 4.11 onnistuu helposti. Käytännössä vain version-tägin sisältö tulee vaihtaa:
Jos testit suoritetaan nyt uudestaan komennolla mvn test, huomataan että Maven lataa JUnit-version 4.11 käyttöösi. Koska JUnit on yhteensopiva taaksepäin, testit menevät läpi.
Jos NetBeans-projektin kuvakkeessa on keltainen kolmio sekä lähdekoodikansioissa mahdollinen punainen pallo, saat lisätietoa ongelmasta viemällä hiiren projektin nimen päälle.
Yllä olevassa kuvassa näemme tekstin "Some dependency artifacts are not in the local repository.", eli osaa riippuvuuksista ei ole ladattu paikalliselle koneelle. Valitse tällöin oikealla hiirennäppäimellä Dependencies ja "Download Declared Dependencies". Nyt NetBeans pyytää Mavenia lataamaan riippuvuudet.
Riippuvuudet ladataan käyttäjän kotihakemiston alla olevaan kansioon ".m2".
New Dependencies
Tutustu tehtävässä tulevaan pom.xml -pohjaan. Mukana on TMC:n vaatimia asetuksia, esimerkiksi TMCn oman pluginvaraston osoite. Tässä tehtävässä sinun tulee lisätä tehtäväpohjan pom.xml-tiedostoon seuraavanlainen riippuvuus.
Kun olet lisännyt riippuvuuden, suorita projektiin liittyvät testit. Jos testit menevät läpi, palauta tehtävä.
Paketointi
Projektin paketointi tapahtuu vaiheessa packaging, joka suoritetaan komennolla package.
mvn package
Koska vaihe package tulee testien jälkeen, Maven ensin kääntää ja testaa sovelluksen. Tämän jälkeen projekti paketoidaan projektijuuressa olevaan target-kansioon. Sovelluksesta luodun pakkauksen nimi tulee sisältämään sovelluksen nimen ja version, eli lopulliseksi paketin nimeksi tulee sovelluksen-nimi-1.0-SNAPSHOT.jar. Katsoessamme projektin kansiorakennetta, huomaamme että target-kansiossa on muutakin. Esimerkiksi target/surefire-reports-kansiossa on tarkemmat kuvaukset suoritetuista testeistä.
"I just had to take the hypertext idea and connect it to the TCP and DNS ideas and – ta-da! – the World Wide Web." -- Tim Berners-Lee
Internetin mahdollistavat (1) tapa yksilöidä palveluja ja palvelujen tarjoamia resursseja (DNS, Domain Name Services ja URI, Uniform Resource Identifier), (2) protokolla viestien lähetykseen verkon yli (HTTP, HyperText Transfer Protocol) ja (3) yhteinen dokumenttien esityskieli (HTML, HyperText Markup Language).
URI ja DNS
"The most important thing that was new was the idea of URI-or URL, that any piece of information anywhere should have an identifier, which will allow you to get hold of it." -- Tim Berners-Lee
Verkossa sijaitseva sivusto tunnistetaan sille annetun yksilöivän osoitteen perusteella. Osoite (URI eli Uniform Resource Identifier, terminä käyttöön jäänyt URL Uniform Resource Locator) koostuu resurssin nimestä ja sijainnista, joiden perusteella haluttu palvelin ja resurssi voidaan löytää verkossa olevien koneiden massasta.
Periaatteessa palvelimelle tehtävää kyselyä voidaan ajatella metodikutsuna, jonka tulee palauttaa arvo tai heittää poikkeus.
Kun käyttäjä kirjoittaa web-selaimen osoitekenttään URIn ja painaa enteriä, web-selain tekee kyselyn annettuun osoitteeseen. Koska tekstimuotoiset osoitteet ovat käytännössä vain ihmisiä varten, kääntää selain ensiksi halutun osoitteen numeeriseksi IP-osoitteeksi. Jos IP-osoite on jo tiedossa esimerkiksi aiemmin osoitteeseen tehdyn kyselyjen takia, selain voi ottaa yhteyden IP-osoitteeseen. Jos taas IP-osoite ei ole tiedossa, tulee selaimen ensin tehdä kysely DNS-palvelimelle (Domain Name System), jonka tehtävänä on muuntaa tekstuaaliset osoitteet IP-osoitteiksi (esim. http://www.cs.helsinki.fi -> 128.214.166.78).
Ilman DNS-palvelimia ihmisten tulisi muistaa IP-osoitteet ulkoa, joka käytännössä tarkoittaisi ettei nykyinen internet toimisi.
IP-osoitteet yksilöivät tietokoneet ja mahdollistavat koneiden löytämisen verkon yli. Käytännössä yhteys IP-osoitteen määrittelemään koneeseen avataan sovellustason HTTP-protokollan avulla kuljetustason TCP-protokollan yli. TCP-protokollan tehtävänä on varmistaa, että viestit pääsevät perille. Lisää tietoa konkreettisesta tietoliikenteestä kurssilla Tietoliikenteen perusteet.
Kun palvelin vastaanottaa tiettyyn resurssiin liittyvän pyynnön, tekee se resurssiin mahdollisesti liittyviä toimintoja ja palauttaa lopulta vastauksen. Kun selain saa vastauksen, tarkistaa se vastaukseen liittyvän statuskoodin ja siihen liittyvät tiedot. Tämän jälkeen selain päättelee, mitä vastauksella tehdään, ja esimerkiksi renderöi vastaukseen liittyvän web-sivun käyttäjälle.
protokolla: kyselyssä käytettävä protokolla, esimerkiksi HTTP, FTP tai SSH.
isäntäkone: kone tai palvelin johon luodaan yhteys. Voi olla joko IP-osoite tai tekstuaalinen kuvaus (esim www.cs.helsinki.fi).
portti: portti isäntäkoneella johon yhteys luodaan. HTTP-palvelimien oletusportti on 80. Jos palvelin käyttää eri porttinumeroa kuin 80, tulee se merkitä osoitteeseen. Portti käytännössä määrittelee prosessin, johon yritetään ottaa yhteyttä.
polku: periaatteessa polku resurssiin palvelimella. Käytännössä (nykyään) palvelun osoite, johon palvelin osaa osoittaa. Usein palvelut toimivat erillisessä koneessa sisäverkossa, ja ulkoverkkoon näkyvä kone vain toimii ohjaajana eli proxynä oikeaan palveluun.
kohdedokumentti: haettava resurssi, jos kohdedokumenttia ei ole määritelty palvelin päättelee oletusdokumentin. Usein index.html
kyselyparametrit: koostuu avain-arvo -pareista, joiden avulla palvelimelle pystyy toteuttamaan lisätoiminnallisuutta. Kuhunkin avaimeen liittyvä arvo esitetään = -merkillä, avain-arvo -parit erotetaan toisistaan &-merkillä.
ankkuri: kertoo mihin kohtaan dokumentissa tulee mennä.
HTTP (HyperText Transfer Protocol) on TCP/IP -protokollapinon sovellustason protokolla, jota web-palvelimet ja selaimet käyttävät kommunikointiin. HTTP-protokolla perustuu asiakas-palvelin malliin, jossa jokaista pyyntöä kohden on yksi vastaus (request-response paradigm). Käytännössä HTTP-asiakasohjelma (jatkossa selain) lähettää HTTP-viestin HTTP-palvelimelle (jatkossa palvelin), joka palauttaa HTTP-vastauksen. HTTP-protokollan versio 1.1 on määritelty RFC 2616-spesifikaatiossa.
Asiakas-palvelin malli
Asiakas-palvelin -mallissa (Client-Server model) asiakkaat käyttävät palvelimen tarjoamia palveluja. Kommunikointi asiakkaan ja palvelimen välillä tapahtuu usein verkon yli siten, että asiakasohjelmisto ja palvelinohjelmisto sijaitsevat erillisissä fyysisissä sijainneissa (eri tietokoneilla). Palvelinohjelmisto tarjoaa yhden tai useamman palvelun, joita asiakasohjelmisto käyttää.
Käytännössä asiakasohjelmisto tarjoaa käyttöliittymän ohjelmiston käyttäjälle. Asiakasohjelmiston käyttäjän ei tarvitse tietää, että kaikki käytetty tieto ei ole hänen koneella. Käyttäjän tehdessä toiminnon asiakasohjelmisto pyytää tarpeen vaatiessa palvelimelta käyttäjän tarpeeseen liittyvää lisätietoa. Tyypillistä mallille on se, että palvelin tarjoaa vain asiakkaan pyytämät tiedot ja verkossa liikkuvan tiedon määrä pidetään vähäisenä.
Asiakas-palvelin -malli mahdollistaa hajautetut ohjelmistot: asiakasohjelmistoa käyttävät loppukäyttäjät voivat sijaita eri puolilla maapalloa palvelinohjelmiston sijaitessa tietyssä paikassa.
Chuck Norris
Selaa osoitteeseen http://www.imdb.com. Kirjoita sivuston ylälaidassa olevaan kenttään "Chuck Norris" ja paina Enter. Mitkä seuraavista askeleista tapahtuivat asiakasohjelmistossa, mitkä palvelinohjelmistossa, mitkä muualla? Voit olettaa että asiakasohjelmistolla tarkoitetaan käyttämääsi web-selainta.
Näppäimistön avulla kirjoittamasi osoitetekstin näyttäminen.
Osoitetta http://www.imdb.com vastaavan IP-osoitteen etsiminen.
Sivun http://www.imdb.com näyttäminen.
Chuck Norriksen etsiminen.
Haasteena perinteisessä asiakas-palvelin mallissa on se, että palvelin sijaitsee yleensä tietyssä keskitetyssä sijainnissa. Keskitetyillä palveluilla on mahdollisuus ylikuormittua asiakasmäärän kasvaessa. Kapasiteettia rajoittavat muun muassa palvelimen fyysinen kapasiteetti (rauta), palvelimeen yhteydessä olevan verkon laatu ja nopeus, sekä tarjotun palvelun tyyppi. Esimerkiksi tietokantatransaktiota vaativat pyynnöt vievät huomattavasti enemmän aikaa kuin yksinkertaiset lukuoperaatiot.
Knock-knock! Who's there?
Lähes kaikki sovellusten verkkoliikenne sovellustason protokollasta riippumatta käyttää TCP-yhteyksiä ja -portteja kommunikointiin. TCP-yhteyksiä käytetään Javassa Socket- ja ServerSocket-luokkien avulla.
Tutustutaan pikaisesta Socket-ohjelmointiin.
Eräs suosittu viestiprotokolla (eli säännöstö, joka kertoo kuinka kommunikoinnin tulee kulkea) alkaa sanoilla Knock knock!. Toinen osapuoli vastaa tähän Who's there?. Ensimmäinen osapuoli vastaa jotain, esim. Art, jonka jälkeen toisen osapuolen tulee vastata Art who?. Tähän ensimmäinen osapuoli vastaa viestillä joka päättyy "Bye.".
Server: Knock knock!
Client: Who's there?
Server: Robin
Client: Robin who?
Server: Robin your house! Bye.
Tehtäväpohjan mukana tulee projekti, johon palvelinpuolen toiminnallisuus on toteutettu valmiiksi luokassa KnockKnockServer. Palvelinohjelmisto kuuntelee vastaanottoa portissa 12345.
Tehtävänäsi on toteuttaa valmiiksi toteutettua palvelinkomponenttia varten asiakaspuolen toiminnallisuus, eli sovellus, joka tekee kyselyjä palvelimelle. Asiakaspuolen toiminnallisuutta varten on jo olemassa allaoleva runko, joka tulee myös mukana tehtäväpohjan luokassa KnockKnockClient.
Täydennä asiakasohjelmisto annettujen askelten mukaan siten, että sitä voi käyttää kommunikointiin viestiprotokollapalvelimen kanssa.
// Luodaan yhteys palvelimelle
Socket socket = new Socket("localhost", port);
Scanner serverMessageScanner = new Scanner(socket.getInputStream());
PrintWriter clientMessageWriter = new PrintWriter(
socket.getOutputStream(), true);
Scanner userInputScanner = new Scanner(System.in);
// Luetaan viestejä palvelimelta
while (serverMessageScanner.hasNextLine()) {
// 1. lue viesti palvelimelta
// 2. tulosta palvelimen viesti standarditulostusvirtaan näkyville
// 3. jos palvelimen viesti loppuu merkkijonon "Bye.", poistu toistolausekkeesta
// 4. pyydä käyttäjältä palvelimelle lähetettävää viestiä
// 5. kirjoita lähetettävä viesti palvelimelle. Huom! Käytä println-metodia.
}
Kirjoita asiakasohjelmiston lähdekoodi KnockKnockClient-luokan start-metodiin kommenteissa annettujen ohjeiden mukaisesti. Kun olet saanut ohjelmiston valmiiksi, suorita ohjelma, jotta voit kokeilla sitä. Tehtäväpohjan mukana on ohjelman käynnistävä main-metodin sisältävä luokka valmiina. Tulostuksen pitäisi olla esimerkiksi seuraavanlainen (käyttäjän syöttämät tekstit on merkitty punaisella):
Server: Knock knock!
Type a message to be sent to the server: Who's there?
Server: Lettuce
Type a message to be sent to the server: Lettuce who?
Server: Lettuce in! it's cold out here! Bye.
Jos asiakasohjelmisto lähettää virheellisiä viestejä, reagoi palvelin siihen seuraavasti:
Server: Knock knock!
Type a message to be sent to the server: What?
Server: You are supposed to ask: "Who's there?"
Type a message to be sent to the server: Who's there?
Server: Lettuce
Type a message to be sent to the server: huh
Server: You are supposed to ask: "Lettuce who?"
Type a message to be sent to the server: Lettuce who?
Server: Lettuce in! it's cold out here! Bye.
Kun ohjelma toimii mielestäsi vaaditulla tavalla, suorita ohjelman testit. Kun testit menevät läpi, lähetä tehtävä TMC-palautusautomaattiin.
Vink! Jos ohjelman käynnistäminen ei onnistu, tarkista oletko käynnistänyt sovelluksen jo kertaalleen. Jos KnockKnock-palvelin on päällä, se varaa portin, eikä muut sovellukset (eli KnockKnock-palvelin, jota yrität käynnistää) saa varattua porttia itselleen. Sama pätee kaikille sovelluksille: vain yksi sovellus voi varata portin kerrallaan.
Näet NetBeansin oikeassa alalaidassa olevasta alueesta päällä olevat sovellukset, ja voit sulkea niitä klikkaamalla aluetta.
Web-palvelimet toimivat periaatteessa kuten yllä toteutettu sovellus, mutta ne käyttävät kommunikointiin HTTP-protokollaa. Yllä olleessa tehtävässä toteutettiin osa selainta vastaavasta toiminnallisuudesta, palvelimen toiminnallisuus oli jo valmiina.
Käytännössä web-selaimetkin ottavat yhteyden haluttuun osoitteeseen liittyvään porttiin, kirjoittavat sinne, ja lukevat sieltä palautettavaa tietoa.
Jos tämän viikon tehtäviltä jää aikaa, yritä toteuttaa oma kyselyt tulostava palvelin. Palvelimen tulee tulostaa tiettyyn porttiin (vaikkapa portti 12345) tehtyjen kyselyjen sisällöt.
HTTP-protokollan yli lähetettävät viestit ovat tekstimuotoisia. Viestit koostuvat riveistä jotka muodostavat otsakkeen, sekä riveistä jotka muodostavat viestin rungon. Viestin runkoa ei ole pakko olla olemassa. Viestin loppuminen ilmoitetaan kahdella peräkkäisellä rivinvaihdolla.
Palvelimelle lähetettävän viestin, eli kyselyn, ensimmäisellä rivillä on pyyntötapa, halutun resurssin polku ja HTTP-protokollan versionumero.
PYYNTÖTAPA /POLKU_HALUTTUUN_RESURSSIIN HTTP/versio
otsake-1: arvo
otsake-2: arvo
valinnainen viestin runko
Pyyntötapa ilmaisee HTTP-protokollassa käytettävän pyynnön tavan (esim. GET tai POST), polku haluttuun resurssiin kertoo haettavan resurssin sijainnin palvelimella (esim. /index.html), ja HTTP-versio kertoo käytettävän version (esim. HTTP/1.0). Alla esimerkki hyvin yksinkertaisesta -- joskin yleisestä -- pyynnöstä. Huomaa että pyyntöä tehdessä yhteys palvelimeen on jo muodostettu, eli palvelimen osoitetta ei merkitä erikseen.
GET /index.html HTTP/1.0
Yksittäisen koneen dedikointi web-palvelimeksi jättää usein huomattavan osan koneen kapasiteetista käyttämättä. Nykyään yleisesti käytössä oleva HTTP/1.1 -protokolla mahdollistaa useamman palvelimen pitämisen samalla koneella virtuaalipalvelintekniikan avulla, jolloin yksittäiset palvelinkoneet voivat sisältää useita palvelimia. Käytännössä IP-osoitetta kuunteleva kone voi joko itsessään sisältää useita ohjelmistoilla emuloituja palvelimia, tai se voi toimia reitittimenä ja ohjata pyynnön tietylle esimerkiksi yrityksen sisäverkossa sijaitsevalle koneelle. Kun yksittäinen IP-osoite voi sisältää useampia palvelimia, pelkkä polku haluttuun resurssiin ei riitä oikean resurssin löytämiseen: resurssi voisi olla millä tahansa koneeseen liittyvällä virtuaalipalvelimella. HTTP/1.1 -protokollassa on pyynnöissä pakko olla mukana käytetyn palvelimen osoitteen kertova Host-otsake.
GET /index.html HTTP/1.1
Host: www.munpalvelin.net
Palvelimelle tehtyyn pyyntöön saadaan aina jonkinlainen vastaus. Jos tekstimuotoiseen osoitteeseen ei ole liitetty IP-osoitetta DNS-palvelimilla, selain ilmoittaa ettei palvelinta löydy. Jos palvelin löytyy, ja pyyntö saadaan tehtyä palvelimelle asti, tulee palvelimen myös vastata jollain tavalla.
Palvelimelta saatavan vastauksen sisältö on seuraavanlainen. Ensimmäisellä rivillä HTTP-protokollan versio, viestiin liittyvä statuskoodi, sekä statuskoodin selvennys. Tämän jälkeen on joukko otsakkeita, tyhjä rivi, ja mahdollinen vastausrunko. Vastausrunko ei ole pakollinen.
HTTP/versio statuskoodi selvennys
otsake-1: arvo
otsake-2: arvo
valinnainen vastauksen runko
Esimerkiksi:
HTTP/1.1 200 OK
Date: Mon, 02 Sep 2013 03:12:45 GMT
Server: Apache/2.2.14 (Ubuntu)
Vary: Accept-Encoding
Content-Length: 973
Connection: close
Content-Type: text/html;charset=UTF-8
.. runko ..
Google Dev Tools
Google chromen DevTools-apuvälineet löytää Tools-valikosta tai painamalla F12 (Linux). Apuvälineillä voi esimerkiksi tarkastella verkkoliikennettä ja lähetettyjä ja vastaanotettuja paketteja. Alla olevassa kuvassa on avattu tietojenkäsittelytieteen laitoksen sivuilta uutinen, ja tutkittu siihen liittyviä otsaketietoja.
Statuskoodit
Statuskoodit (status code) kuvaavat palvelimella tapahtunutta toimintaa kolmella numerolla. Statuskoodien avulla palvelin kertoo mahdollisista ongelmista tai tarvittavista lisätoimenpiteistä. Yleisin statuskoodi on 200, joka kertoo kaiken onnistuneen oikein. HTTP/1.1 sisältää viisi kategoriaa vastausviesteihin.
1**: informaatioviestit (esim 100 "Continue")
2**: onnistuneet tapahtumat (esim 200 "OK")
3**: asiakasohjelmistolta tarvitaan lisätoimintoja (esim 301 "Moved Permanently" tai 304 "Not Modified" eli hae välimuistista)
4**: virhe pyynnössä tai erikoistilanne (esim 401 "Not Authorized" ja 404 "Not Found")
5**: virhe palvelimella (esim 500 "Internal Server Error")
Linux-ympäristöissä on käytössä telnet-työkalu, jota voi käyttää yksinkertaisena asiakasohjelmistona pyyntöjen simulointiin. Telnet-yhteyden tietyn koneen tiettyyn porttiin saa luotua komennolla telnet isäntäkone portti. Esimerkiksi TKTL:n www-palvelimelle saa yhteyden seuraavasti:
$ telnet cs.helsinki.fi 80
Tätä seuraa telnetin infoa yhteyden muodostamisesta, jonka jälkeen pääsee kirjoittamaan pyynnön.
Trying 128.214.166.78...
Connected to cs.helsinki.fi.
Escape character is '^]'.
Yritetään pyytää HTTP/1.1 -protokollalla juuridokumenttia. Huom! HTTP/1.1 -protokollassa tulee pyyntöön lisätä aina Host-otsake. Jos yhteys katkaistaan ennen kuin olet saanut kirjoitettua viestisi loppuun, ota apuusi tekstieditori ja copy-paste. Muistathan myös että viesti lopetetaan aina kahdella rivinvaihdolla.
GET / HTTP/1.1
Host: cs.helsinki.fi
Palvelin lähettää meille vastauksen, jossa on statuskoodi ja otsakkeita sekä dokumentin runko.
HTTP/1.1 302 Found
Date: Mon, 02 Sep 2013 18:31:30 GMT
Server: Apache/2.2.14 (Ubuntu)
Location: http://www.cs.helsinki.fi/
Vary: Accept-Encoding
Content-Length: 290
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>302 Found</title>
</head><body>
<h1>Found</h1>
<p>The document has moved <a href="http://www.cs.helsinki.fi/">here</a>.</p>
<hr>
<address>Apache/2.2.14 (Ubuntu) Server at cs.helsinki.fi Port 80</address>
</body></html>
Juuripolkua palvelimelta cs.helsinki.fi haettaessa palvelin vastaa että dokumentti on löytynyt (302 Found), mutta se sijaitsee muualla (Location: http://www.cs.helsinki.fi/).
Kuinka monta hyppyä?
Käytä telnetiä ja aloita osoitteesta cs.helsinki.fi, tavoitteenasi on päästä laitoksen etusivulle http://www.cs.helsinki.fi/home/. Kuinka monta uudelleenohjausta saat ennenkuin pääset etusivulle?
Jos et ehdi kirjoittamaan komentia telnet-ikkunaan, voit ensin kirjoittaa sen esimerkiksi tekstieditoriin, ja kopioida sen sieltä telnet-ikkunaan.
Pyyntötavat
HTTP-protokolla määrittelee kahdeksan erillistä pyyntötapaa (Request method), joista yleisimmin käytettyjä ovat GET ja POST. Pyyntötavat määrittelevät rajoitteita ja suosituksia viestin rakenteeseen ja niiden prosessointiin palvelinpäässä. Esimerkiksi Java Servlet API (versio 2.5) sisältää seuraavan suosituksen GET-pyyntotapaan liittyen:
The GET method should be safe, that is, without any side effects for which users are held responsible. For example, most form queries have no side effects. If a client request is intended to change stored data, the request should use some other HTTP method.
Suomeksi yksinkertaistaen: Palvelinpuolen toiminnallisuutta suunniteltaessa kannattaa pyrkiä tilanteeseen, missä GET-tyyppisillä pyynnöillä ei voida muuttaa palvelimella olevaa dataa.
GET
GET-pyyntötapaa käytetään esimerkiksi dokumenttien hakemiseen: kun kirjoitat osoitteen selaimen osoitekenttään ja painat enter, selain tekee GET-pyynnön. GET-pyynnöt eivät tarvitse otsaketietoja HTTP/1.1:n vaatiman Host-otsakkeen lisäksi. Mahdolliset kyselyparametrit lähetetään palvelimelle osana haettavaa osoitetta.
GET /sivu.html?porkkana=1 HTTP/1.1
Host: palvelimen-osoite.net
POST
Käytännön ero POST- ja GET-kyselyn välillä on se, että POST-tyyppisillä pyynnoillä kyselyparametrit liitetään pyynnön runkoon. Rungon sisältö ja koko määritellään otsakeosiossa. POST-kyselyt mahdollistavat multimedian (kuvat, videot, musiikki, ...) lähettämisen palvelimelle.
POST /sivu.html HTTP/1.1
Host: palvelimen-osoite.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 10
porkkana=1
HTML
"In '93 to '94, every browser had its own flavor of HTML. So it was very difficult to know what you could put in a Web page and reliably have most of your readership see it." -- Tim Berners-Lee
HTML on rakenteellinen kuvauskieli, jolla voidaan esittää linkkejä sisältävää tekstiä sekä tekstin rakennetta. HTML koostuu elementeistä, jotka voivat olla sisäkkäin ja peräkkäin. Elementtejä käytetään ohjeina dokumentin jäsentämiseen ja käyttäjälle näyttämiseen. HTML-dokumenteissa elementit avataan elementin nimen sisältävällä pienempi kuin -merkillä (<) alkavalla ja suurempi kuin -merkkiin (>) loppuvalla merkkijonolla (<elementin_nimi>), ja suljetaan merkkijonolla jossa elementin pienempi kuin -merkin jälkeen on vinoviiva (</elementin_nimi>).
HTML-dokumentin rakennetta voi ajatella myös puuna. Juurisolmuna on elementti <html>, jonka lapsina ovat elementit <head> ja <body>.
Jos elementin sisällä ei ole muita elementtejä tai tekstisolmuja eli tekstiä, voi elementin yleensä avata ja sulkea samalla merkkijonolla: (<elementin_nimi />).
HTML:stä on useita erilaisia standardeja, joista viimeisin on HTML5, a.k.a. HTML
<!DOCTYPE html>
<html lang="fi">
<head>
<meta charset="UTF-8">
<title>selainikkunassa näkyvä otsikko</title>
</head>
<body>
<p>Tekstiä tekstielementin sisällä, tekstielementti runkoelementin sisällä,
runkoelementti html-elementin sisällä. Elementin sisältö voidaan asettaa
useammalle riville.</p>
</body>
</html>
Ylläoleva HTML5-dokumentti sisältää dokumentin tyypin ilmaisevan aloitustägin (<!DOCTYPE html>), dokumentin aloittavan html-elementin (<html>), otsake-elementin ja sivun otsikon (<head>, jonka sisällä <title>), sekä runkoelementin (<body>).
Elementit voivat sisältää attribuutteja ja attribuuteille voi antaa arvoja. Esimerkiksi ylläolevassa esimerkissä html-elementille on määritelty erillinen attribuutti lang, joka kertoo dokumentissa käytetystä kielestä. Ylläolevan esimerkin otsakkeessa on myös metaelementti, jota käytetään lisävinkin antamiseen selaimelle: "dokumentissa käytetään UTF-8 merkistöä". Tämä kannattaa olla dokumenteissa aina.
Nykyaikaiset web-sivut sisältävät paljon muutakin kuin sarjan HTML-elementtejä. Linkitetyt resurssit, kuten kuvat ja tyylitiedostot, ovat oleellisia sivun ulkoasun ja rakenteen luomisessa. Selainpuolella suoritettavat skriptitiedostot, erityisesti Javascript, ovat luoneet huomattavan määrän syvyyttä nykyaikaiseen web-kokemukseen. Tällä kurssilla emme syvenny selainpuolen toiminnallisuuteen, mutta viimeksi syksyllä 2012 järjestetyn kurssin Web-selainohjelmointi materiaalista saattaa olla hyötyä aihealueeseen tutustumisessa.
Lomakkeet
Lomakkeita käytetään tiedon lähettämiseen web-palveluille. HTML-elementti lomakkeelle on<form>. Lomake-elementille voidaan antaa attribuutteina toiminto (action), jolle voidaan määrittelee osoite mihin lomakkeen sisältö lähetetään, ja lomakkeen lähetystapa (method). Lomakkeen lähetystapa (GET tai POST) kertoo lähetetäänkö lomakkeen tiedon kyselyparametreina osana osoitetta (GET) vai pyynnön yhteydessä erillisenä datana (POST). Käytetään lähetystapaa POST.
<form action="kohdeosoite" method="POST">
Jos attribuuttia action ei ole määritelty, lähetetään lomake oletuksena nykyiseen osoitteeseen. Attribuutin method oletusarvo on GET.
Lomakekentät
Lomake-elementin alle voi asettaa useita erilaisia kenttiä. Jos kentän arvon haluaa lähettää eteenpäin, tulee kentällä olla attribuutti nimi (name), jonka arvoa käytetään kenttään asetetun tiedon avaimena.
tekstikenttä:
<input type="text" />
salasanakenttä:
<input type="password" />
tekstialue:
Toisin kuin monet muut lomakkeen kenttäelementit, tekstialue tulee sulkea erillisellä elementillä.
<textarea name="tekstialue"></textarea>
valintaruutu:
Porkkanaa
Naurista
Kaalia
Selaimesta riippuen valintaruudun tiedot lähetetään lomakkeen mukana vain kentän ollessa valittuna.
valintanappi:
Porkkanaa
Naurista
Kaalia
Valintanappia käytettäessä vain yksi saman name-attribuutin omistava radio-tyyppinen input-elementti voi olla valittuna. Lomaketta lähetettäessä valitun elementin attribuutin value arvo lähetetään name attribuutin arvona.
Lähetysnappia painettaessa lomakkeen tiedot lähetetään kohdeosoitteeseen valitulla lähetystavalla.
<input type="submit" value="Lähetä" />
Lomakkeen lähettäminen
Kun lomake lähetetään selain ohjaa käyttäjän kohdeosoitteeseen siten, että lähetettävän lomakkeen tiedot ovat mukana selaimen tekemässä pyynnössä. Jos lomakkeen lähetystapa on GET, on lomakkeen tiedot osana osoitetta. Lähetystavassa POST arvot tulevat osana pyynnön runkoa.
Alla on lomake jolla voi visualisoida tietojen lähettämistä. Lomakkeiden toimintona on http://t-avihavai.users.cs.helsinki.fi/lets/See), jossa on pyynnössä saatujen tiedojen tulostava web-palvelu.
HTML-elementit muodostavat DOM-puun, joka sisältää kaikki HTML-sivun elementit ja niiden ominaisuudet. Tämän kurssin puitteissa DOM-puu jää hyvin pieneen sivurooliin, ja tärkeintä omalta kannaltamme on seuraavat asiat:
Lomakekentillä olevat nimi-attribuutit (name) ja niihin liittyvät arvot (eli kenttien sisällöt) lähetetään lomakkeen attribuutin action määrittelemään osoitteeseen. GET-tyyppiset pyynnön lisäävät attribuutit osaksi osoitetta, POST-tyyppisissä pyynnöissä attribuutit kulkevat osana pyyntöä.
Kun lomakkeessa painetaan submit-nappia, lomake lähetetään GET-tyyppisenä pyyntönä osoitteeseen http://t-avihavai.users.cs.helsinki.fi/lets/See. Lomakkeesta lähtevät tiedot liittyvät lomakkeen kenttiin. Yllä olevassa lomakkeessa on tasan yksi lomakekenttä, jonka nimi on viesti. Kentät tunnistetaan lomaketta lähetettäessä niiden name-attribuutin mukaan. Koska lomakkeen lähetystyyppi on GET (method="GET"), liitetään lomakkeen kentät osaksi osoitetta.
Esimerkiksi, jos lomakkeen viesti-kenttään kirjoitetaan teksti Hei, ja lomake lähetetään, kysely tehdään osoitteeseen http://t-avihavai.users.cs.helsinki.fi/lets/See?viesti=Hei. Huomaa että lomakkeen sisältämät tiedot on jo osana osoitetta.
HTML-dokumentin muodostamaa puuta läpikäydessä elementit voidaan tunnistaa sekä niiden nimen, että niiden tunnuksen perusteella. Tunnus, eli id, on erillinen elementit yksilöivä attribuutti. Esimerkiksi ylläolevassa lomakkeessa olevaan viestikenttään voi liittää tunnuksen seuraavasti:
Nyt lomakkeessa oleva viestikenttä voidaan tunnistaa myös sen tunnuksen perusteella. Tunnusten käyttämisen tarve selkenee kurssilla Web-selainohjelmointi, nyt vain todetaan että niitä tarvitaan. Jos haluat lisää tietoa aiheeseen liittyen, W3Schools tarjoaa hyvän pohjustuksen DOM-puiden läpikäyntiin ja muokkaamiseen.
First Html Form
Tehtäväpohjassa tulee mukana web-projekti, jonka rakenne on seuraavanlainen:
Projektille on jo konfiguroitu osoite /view jota kuuntelee luokka RequestParametersServlet. Luokka tulostaa pyynnössä mukana tulevat parametrit käyttäjän näkyville.
Tehtävänäsi on toteuttaa webapp-kansiossa (NetBeansin projektinäkymässä kansio Web Pages) olevaan index.jsp-sivuun seuraavannäköinen lomake:
Lomakkeen Nimi-kentän id sekä name attribuuttien arvon tulee olla name. Osoite-kentällä id ja name attribuuttien arvon tulee olla address. Jokaisen lipputyypin nimi tulee olla ticket. Vihreää lippua kuvaavan valinnan id:n tulee olla ticket-green ja arvon green. Vastaavasti keltaista lippua kuvaavan valinnan id:n tulee olla ticket-yellow ja arvon yellow, ja punaista lippua kuvaavan valinnan id:n tulee olla ticket-red ja arvon red.
Käytä lomakkeen action-attribuutin arvona merkkijonoa "${pageContext.request.contextPath}/view". Merkkijonon ${pageContext.request.contextPath} merkitys selviää myöhemmin. Lomakkeen metodilla ei ole väliä tässä tehtävässä.
Kun olet saanut lomakkeen valmiiksi, suorita siihen liittyvät testit. Kun testit menevät läpi, lähetä tehtävä TMC:lle.
NetBeans ei oletusasetuksillaan suostu käynnistämään web-palvelinta valittaessa Run project, jos projektiin liittyvät testit eivät mene läpi. Voit muuttaa projektin oletusasetuksia valitsemalla projektin nimen oikealla hiirennapilla -> Properties -> Actions. Valitse Action Run project, ja lisää sille ominaisuus skipTests=true. Tämän jälkeen palvelin käynnistyy vaikka testit eivät mene läpi.
Voit myös käynnistää web-pohjaiset projektit komentoriviltä Jetty-palvelimen avulla. Komento mvn jetty:start käynnistää palvelimen projektin target-kansiossa olevilla tiedostoilla.
Hello Web!
Tutustutaan tässä osiossa web-sovellusten rakenteeseen, sekä yksinkertaisten web-sovellusten toteuttamiseen servleteillä. Osa kappaleessa olevista esimerkeistä on tarkoitettu sillaksi HTTPn ja palvelimilla toimivien ohjelmistojen välillä.
Servletit
Servletit ovat Javan teknologia dynaamisen palvelinpuolen web-toiminnallisuuden toteuttamiseen. Nimi Servlet tulee siitä, että servletit palvelevat (serve) käyttäjän tekemiä pyyntöjä: ne vastaanottavat pyyntöjä sekä myös vastaavat niihin.
Käytännössä Servlettejä toteutettaessa ohjelmoija perii javan valmiin HttpServlet-luokan, ja korvaa yhden tai useamman sen tarjoamista metodeista. Yläluokka HttpServlet tarjoaa metodeja yleisimpien HTTP-protokollan pyyntöjen käsittelyyn. Esimerkiksi metodilla doGet käsitellään GET-tyyppinen pyyntö, kun taas metodilla doPost käsitellään POST-tyyppinen pyyntö.
Jokaisella pyyntöä käsittelevällä metodilla on parametrina kaksi rajapintaluokkaa: HttpServletRequest sisältää käyttäjän palvelimelle tekemän pyynnön tiedot ja HttpServletResponse sisältää käyttäjälle palvelimelta lähetettävän vastauksen. Rajapintaluokkien konkreettinen toteutus on käytettävän palvelimen toteuttajien vastuulla, Java tarjoaa vain rajapintamäärittelyt. Palvelinohjelmiston toteuttaja, me, taas käyttää rajapintoja esimerkiksi pyynnön tietojen tarkasteluun ja vastauksen määrittelyyn.
Palvelimella toimiva web-sovellus voi koostua yhdestä tai useammasta Servletistä. Muutamissa esimerkeissä esiintyvä lets-sovellus sijaitsee osoitteessa http://t-avihavai.users.cs.helsinki.fi/lets/. Sovellukseen liittyy useampia Servlettejä, joista jokainen kuuntelee yhtä tai useampaa osoitetta. Esimerkiksi osoitteeseen http://t-avihavai.users.cs.helsinki.fi/lets/See on konfiguroitu Servlet, jonka tehtävänä on pyyntöön liittyvien otsakkeiden ja parametrien tulostaminen.
Uudempi Servlet 3.0-spesifikaatio on osittain poistanut web.xml-tiedoston käytön servlettien konfiguroinnista: osa xml-tiedostoissa tapahtuvasta konfiguraatiosta on siirtynyt annotaatioden avulla tapahtuvaksi. Käytämme tällä kurssilla kuitenkin vielä hieman vanhempaa Servlet 2.5-spesifikaatiota: tausta-ajatuksena versiosta riippumatta on se, että servletit tulee kytkeä kuuntelemaan jotain osoitetta.
Luodaan seuraavaksi oma web-sovellus askeleittain, ja tutustutaan samalla web-sovellusten rakenteeseen.
Hello World!
Sovelluksemme tavoite on huikea: haluamme saada "Hello World!"-tekstin käyttäjälle näkyviin. Aloitetaan nollasta, eli projektin luomisesta.
Uusi Maven-pohjainen web-sovellusprojekti
NetBeansissa uuden projektin luominen aloitetaan valitsemalla File -> New Project.
Tämä avaa wizard-ikkunan, jossa valitaan projektin tyyppi. Valitse kategoriasta Maven ja projektin tyypiksi Web Application.
Tämän jälkeen kysytään projektiin liittyviä perustietoja. Projektin nimeksi on asetettu hello-world, ja ryhmätunnukseksi werkko. Muita ei tarvitse vaihtaa. Voit toki päättää itse oman organisaatiosi (ryhmätunnuksesi) ja sovelluksen nimen (projektin nimen).
Tämän jälkeen NetBeans kysyy käytettävää palvelinta ja Java EE-versiota. Laitoksella (pitäisi löytyä) löytyy valmiina GlassFish-palvelin. Voimme käyttää tätä. Valitse Java EE-versioksi 5.
Huh! Projekti luotu! Nyt voisimme lähteä luomaan projektiin liittyviä lähdekooditiedostoja.
Projektin rakenne
Mennään tarkastelemaan projektin rakennetta tarkemmin: komentorivi on tähän mainio työkalu. Projekti on tallennettu aiemmin projektin perustietoja kysyvässä ikkunassa määriteltyyn sijaintiin. Huomaathan että sijainti on projektikohtainen, eli projektisi ei ole kansiossa /home/avihavai/repot/wad. Kun menemme terminaalissa projektin kansioon ja kirjoitamme komennon tree, näemme kutakuinkin seuraavanlaisen listauksen.
Projektirakenne vaikuttaa hyvin tutulta. Projektin juuressa on Mavenin konfiguraatiotiedosto pom.xml ja projektin lähdekooditiedostot ovat src-kansion alla. Projektia luotaessa Maven loi automaattisesti src-kansion alle kansion java, jonne tulee projektin lähdekooditiedostot. Projektiin liittyvät testitiedostot tulisi kansion src alle kansioon test. Tätä kansiota ei ole tässä tapauksessa automaattisesti, mutta sen voi lisätä itse.
Aiemmin tuntematon kansio on src-kansion alla oleva kansio webapp. Kansio webapp tulee sisältämään (lähes) kaikki projektin web-puoleen liittyvät tiedostot. Käydään ne seuraavaksi yksitellen läpi web.xml-tiedostosta lähtien.
web.xml
Tiedosto web.xml sijaitsee webapp-kansion sisällä olevassa WEB-INF-kansiossa. Se sisältää projektin konfiguraation palvelinta varten. Käytännössä kun Java-websovellus asennetaan mille tahansa Java-palvelimelle, palvelin etsii sovelluksen WEB-INF-kansiosta web.xml-tiedoston ja käynnistää sovelluksen tiedoston asetusten perusteella (asetukset, kohta nähtävät servletit, ...).
Asetukset sisältävät mm. käyttävien istuntojen keston sekä ensisijaisesti näytettävän sivun: kun käyttäjä selaa sovelluksen juuripolkuun (esimerkiksi aiemmassa esimerkissä ollut /lets/), käyttäjälle näytetään tiedosto index.jsp.
Tiedosto glassfish.xml ei liity yleisesti web-sovelluksiin, vaan se on NetBeansin luoma lisätiedosto sillä valitsimme aiemmin GlassFish-palvelimen. Tämä tiedosto sisältää GlassFish-palvelimeen liittyviä konfiguraatioita. Omasta näkökulmastamme se ei ole mielenkiintoinen.
kansio WEB-INF
Kansiossa WEB-INF oleviin tiedostoihin ei pääse sovelluksen päällä ollessa käsiksi selaimen kautta. Se sisältää projektiin liittyviä konfiguraatiotiedostoja sekä esimerkiksi JSP-sivuja, joita ei haluta näyttää käyttäjälle suoraan.
index.jsp
Kansiossa webapp oleva tiedosto index.jsp sisältää käyttäjälle näytettävän sivun. JSP-sivut ovat kuin HTML-sivuja, mutta niihin voi lisätä dynaamista toiminnallisuutta. NetBeans generoi JSP-sivuille valmiin pohjan, joka näyttää seuraavalta:
<%@page contentType="text/html" pageEncoding="UTF-8"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>JSP Page</title>
</head>
<body>
<h1>Hello World!</h1>
</body>
</html>
Sivulle on määritelty alkuun erillinen JSP-tägi, joka kertoo sivun sisällön olevan tyyppiä text/html, ja merkistön olevan UTF-8 -muotoista. NetBeans luo oletuksena HTML 4.01 -versioisia sivuja, mutta sivun rakennetta voi toki itse myös muuttaa. Selaimessa sivu näyttää otsikon JSP Page ja tekstin Hello World!. Esimerkki palvelimella olevasta sivusta löytyy osoitteesta http://t-avihavai.users.cs.helsinki.fi/lets/. Huomaa että selaimella sivua katsottaessa palvelin on ennen sivun lähettämistä käyttäjälle suorittanut alussa olleet komennot, ja niitä ei näy sivun lähdekoodia selaimesta katsottaessa.
HelloServlet
Koska index.jsp-sivussa lukee teksti Hello World!, sovelluksemme näyttäisi nyt jo käyttäjälle tekstin Hello World!. Haluamme kuitenkin luoda oman Servletin, joka tulostaa tekstin käyttäjälle. Luodaan HttpServlet-luokan perivä HelloServlet-luokka, joka kuuntelee osoitetta /hello.
Osoitteet, joita servletit kuuntelevat riippuvat aina osoitteesta, jossa servletin sisältämä sovellus toimii. Jos sovellus on osoitteessa http://www.werkko.com/app/ ja sovelluksella on polkua /hello kuunteleva servlet, pääsisi servlettiin osoitteessa http://www.werkko.com/app/hello.
Hyödynnetään NetBeansia Servlet-luokan luomiseen. Valitaan projektin nimi oikealla hiirennäppäimellä ja valitaan New -> Servlet. Jos Servlet-vaihtoehtoa ei ole olemassa, se löytyy Other... -vaihtoehdon avaamalla työkalulla.
Eteen aukeaa New Servlet-työkalu. Täytetään Servlet-luokan nimeksi HelloServlet, ja valitaan Servletille sopiva pakkaus (sovelluksia ei pitäisi tehdä juureen...).
NetBeans haluaa myös auttaa web.xml-tiedoston konfiguroinnissa ja kysyy mitä osoitetta juuri luotavan Servlet-luokan tulisi kuunnella. Asetetaan poluksi /hello.
Eteesi aukeaa Servlet-luokan lähdekoodi, jota voit lähteä muokkaamaan.
Tarkastellaan vielä tarkemmin juuri tapahtuneita muutoksia projektissa.
web.xml
NetBeans lisäsi web.xml-tiedostoon tiedot servletistä ja sen kuuntelemasta polusta. Nyt tiedosto näyttää seuraavalta:
Uutena on keskellä olevat elementit. Elementissä servlet esitellään Servlet-luokka, ja asetetaan sille nimi johon muualla konfiguraatiossa voidaan viitata. Elementissä servlet-mapping taas asetetaan tietyn nimiselle HelloServlet luokalle osoite, jota se kuuntelee. Juuri luotu servlettimme kuuntelee siis sovelluksen polkua /hello.
HelloServlet
Luokka HelloServlet perii Javan valmiin luokan HttpServlet ja sisältää HTTP-pyyntöjen käsittelyn. NetBeansin luoma luokka sisältää apumetodin processRequest, johon POST ja GET-tyyppiset pyynnöt ohjataan. Koko luokan sisältö näyttää seuraavalta (huomattava osa NetBeansin luomista kommenteista poistettu).
// pakkaus
package werkko.helloworld;
// tarvittavat importit
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
// peritään luokka HttpServlet
public class HelloServlet extends HttpServlet {
// metodi pyyntöjen käsittelyyn
// ei näin sitten oikeasti!
protected void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
PrintWriter out = response.getWriter();
try {
/* TODO output your page here. You may use following sample code. */
out.println("<html>");
out.println("<head>");
out.println("<title>Servlet HelloServlet</title>");
out.println("</head>");
out.println("<body>");
out.println("<h1>Servlet HelloServlet at " + request.getContextPath() + "</h1>");
out.println("</body>");
out.println("</html>");
} finally {
out.close();
}
}
// korvattu metodi doGet, pyyntö ohjataan processRequest-metodille
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
processRequest(request, response);
}
// korvattu metodi doPost, pyyntö ohjataan processRequest-metodille
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
processRequest(request, response);
}
}
Oleellista yllä on metodi processRequest, jota sekä metodit doGet ja doPost kutsuvat. Metodia processRequest ei ole tietenkään pakko käyttää: pyynnön prosessoinnin voi hoitaa myös metodeissa doGet ja doPost.
Metodi processRequest asettaa ensin vastauksen sisällön tyypiksi html:n, ja merkistöksi UTF-8:n.
Tämän jälkeen avataan kirjoitusväylä vastausta varten, ja kirjoitetaan HTML-sisältö vastaukseen. Opimme pian parempia tapoja tähän.
PrintWriter out = response.getWriter();
try {
/* TODO output your page here. You may use following sample code. */
out.println("<html>");
out.println("<head>");
out.println("<title>Servlet HelloServlet</title>");
out.println("</head>");
out.println("<body>");
out.println("<h1>Servlet HelloServlet at " + request.getContextPath() + "</h1>");
out.println("</body>");
out.println("</html>");
} finally {
out.close();
}
Hello World!
Muutetaan processRequest-metodia siten, että se tulostaa tekstin Hello World!.
Nyt sovelluksemme /hello-osoitetta kuunteleva Servlet tulostaa käyttäjälle viestin Hello World!.
Sovelluksen testaaminen
Sovellusta voi testata suoraan NetBeansissa valitsemalla oikealla hiirennäppäimellä projektin nimi ja klikkaamalla Run. Tämä käynnistää aiemmin määritellyn palvelimen (tässä GlassFish), ja lisää sovelluksen palvelimelle. Kun palvelin on päällä, NetBeans käynnistää oletuksena myös selaimen sovelluksen katseluun. Huomaa että selaimessa näytetään sovellus: Servlettiä testataksesi sinun tulee lisätä servletin kuuntelema osoite selaimella haettavaan polkuun.
Esimerkiksi, jos sovellus aukeaa osoitteessa http://localhost:8080/hello-world/, olisi HelloServlet osoitteessa http://localhost:8080/hello-world/hello.
Ylläoleva esimerkki kannattaa tehdä myös itse.
Sovelluksen paketointi ja tuotantoon siirtäminen
Maven tarjoaa toiminnot tiedoston paketointiin. Kun kirjoitamme komentoriviltä projektikansiossa komennon mvn package, Maven luo projektista .war-tiedoston, jonka voi siirtää tuotantopalvelimelle.
.../hello-world$ mvn package
...
[INFO] [war:war {execution: default-war}]
[INFO] Packaging webapp
[INFO] Assembling webapp [hello-world] in [....]
...
[INFO] Webapp assembled in [69 msecs]
[INFO] Building war: /.../hello-world/target/hello-world-1.0-SNAPSHOT.war
...
Luodun war-tiedoston voi kopioida esimerkiksi TKTL:n users-palvelimelle, jossa sitä voi ajaa tomcat-palvelimella. Jos sinulla ei ole tunnuksia TKTL:lle älä huoli, tutustumme myöhemmin kurssilla sovellusten siirtämiseen pilvialustoille.
Kone users.cs.helsinki.fi on TKTL:n opiskelijoille tarkoitettu palvelin, jossa voi ajaa omia ohjelmistoja. Users-koneella on käytössä java web-sovelluksia pyörittävä tomcat-palvelin sekä useita tietokannanhallintajärjestelmiä: MySQL, Oracle ja PostgreSQL. Users-koneelle pääsee kirjautumaan komennolla.
ssh users.cs.helsinki.fi -l <omatunnus>
Saamme käyttöömme tomcat-palvelimen komennolla wanna-tomcat. Laitoksella on käytössä tomcatin versio 6.
tunnus@users:~$ wanna-tomcat
This script will create a new tomcat environment for you in directory
/home/tunnus/tomcat. Please see http://users.cs.helsinki.fi/tomcat for more
information. Do you want to create a new tomcat installation
in /home/tunnus/tomcat (y/n)? <syötä y>
....
Tomcat environment has been setup for you. Now you can run 'start-tomcat'.
tunnus@users:~$
Käynnistetään palvelin komennolla start-tomcat.
tunnus@users:~$ start-tomcat
Using CATALINA_BASE: /home/tunnus/tomcat
Using CATALINA_HOME: /usr/share/tomcat6
Using CATALINA_TMPDIR: /home/tunnus/tomcat/temp
Using JRE_HOME: /usr/lib/jvm/java-6-sun
Using CLASSPATH: /usr/share/tomcat6/bin/bootstrap.jar
Tomcat has been started. It should be visible through URL
http://t-omatunnus.users.cs.helsinki.fi/
If you have problems, your tomcat log files are
available from /home/tunnus/tomcat/logs
Please, remember to stop (with stop-tomcat) tomcat instances with are
not used.
tunnus@users:~$
Kun menet web-selaimella osoitteeseen http://t-omatunnus.users.cs.helsinki.fi/, näet sivun jossa on otsikkona viesti "It works!".
Tomcat-palvelimen saa suljettua komennolla stop-tomcat.
Jos tomcat on päällä, pyrkii se käynnistämään sovelluksen automaattisesti. Näet tomcatin logeista tomcat/logs/catalina.out ohjelman logiin kirjoittamat viestit. Jos tomcat ei ole päällä, käynnistä se, ja selaa osoitteeseen http://t-omatunnus.users.cs.helsinki.fi/<projektinnimi>/hello.
Osoitteessa olevan palvelinohjelmiston pitäisi tulostaa HelloServlet-servletissä määritelty viesti.
Servlettien käynnistäminen ja elinkaari
Jos tiedostossa web.xml olevassa servletmäärittelyssä on määre load-on-startup, ja sen arvo on suurempi tai yhtäsuuri kuin 0, Servlet-luokasta ladataan ilmentymä palvelimelle heti web-sovelluksen käynnistyessä.
Muulloin servlet käynnistyy palvelimesta riippuen, usein esimerkiksi silloin kun Servletille määriteltyyn polkuun tehdään ensimmäinen pyyntö. Määre load-on-startup on hyödyllinen esimerkiksi silloin, jos sovelluksen tulee tehdä käynnistyessään esimerkiksi tietokantaoperaatioita. Käynnistyksen yhteydessä suoritettavien toimintojen määrittely onnistuu HttpServlet-luokasta perittävän init-metodin avulla.
Jos Servlettejä on useampia, ja niiden käynnistysjärjestyksellä on merkitystä, määrettä load-on-startup voi käyttää suoritusjärjestyksen määrittelyyn. Servletit käynnistetään load-on-startup-elementin arvojen määräämässä suoritusjärjestyksessä pienimmästä suurimpaan.
Jokaisesta Servlet-luokasta tehdään vain yksi ilmentymä. Samaa ilmentymää käytetään jokaisen Servletille tehdyn pyynnön käsittelyyn. Servlet-luokan oliomuuttujat ovat siis käytettävissä jokaisen pyynnön yhteydessä.
Jos NetBeansissa ei ole oletuspalvelinta sovelluksen testaamiseen, voit valita käyttöön esimerkiksi GlassFish -palvelimen. Huomaamme myöhemmin miten web-sovellukset voi käynnistää myös komentoriviltä esimerkiksi jetty-palvelimen avulla.
Kun käynnistät sovelluksen NetBeansissa, se avaa sovelluksen oletusselaimessa. Oletusselaimen voi vaihtaa NetBeansin asetuksista: Tools -> Options -> General -> Web browser
PageViewCounter
Luo pakkaukseen wad.pageviews.servlet luokka PageViewCounterServlet, joka perii luokan HttpServlet. Luokan PageViewCounterServlet tulee pitää kirjaa tehdyistä GET-tyyppisistä pyynnöistä, ja tulostaa tehtyjen pyyntöjen määrä käyttäjälle. Aseta Servlet kuuntelemaan sovelluksen polkua /count.
Käyttäjälle näytettävä tulostus voi olla esimerkiksi seuraavanlainen. Alla pyyntöjä on tehty yhteensä 3.
Pyyntöjä: 3
Kun olet saanut tehtävän valmiiksi, suorita siihen liittyvät testit ja lähetä se TMCn tarkastettavaksi.
Erota käyttöliittymä ja sovelluslogiikka!
Yksi klassisista neuvoista ohjelmia rakentaessa on "erota sovelluslogiikka ja käyttöliittymä". Aiemmassa Hello World!- esimerkissämme näin ei ole tehty, vaan käyttöliittymä on osa sovelluslogiikkaa. Ei näin!
Sovelluslogiikan ja käyttöliittymän erottaminen on hyvin tärkeää ohjelmistotuotannon kannalta: isompia sovelluksia rakennettaessa useamman ihmisen tulee pystyä muokkaamaan sen eri osia samanaikaisesti. Jos kaikki on samassa tiedostossa, tiedoston luettavuus kärsii huomattavasti ja muokkaukset aiheuttavat lähes taatusti versionhallintakonflikteja. Sovelluksen eri osien testaaminen vaikeutuu myös huomattavasti, jos sovelluksen eri osia ei ole erotettu.
Paljon käytetty tapa käyttöliittymäkoodin ja sovelluskoodin erottamiseksi on luoda jokaiselle näkymälle oma sivu, johon Servlet-luokka pyynnön lopulta ohjaa. JSP-sivut luodaan WEB-INF-kansion sisälle omaan kansioon, jotta sivuihin ei pääse käsiksi suoraan selaimella. Tällä kurssilla jsp-sivut sisältävän kansion nimi on jsp.
Jatketaan Hello World! -esimerkin muokkaamista ja luodaan kansioon WEB-INF kansio jsp. Tämä onnistuu NetBeansissa klikkaamalla kansiota WEB-INF oikealla hiirennäppäimellä, ja valitsemalla New -> Other -> Other -> Folder. Kansioon jsp lisätään hello.jsp-niminen jsp-sivu, jonka sisältö on seuraava:
Pyynnön ohjaaminen JSP-sivulle tapahtuu HttpServletRequest-rajapinnan tarjoaman RequestDispatcher-olion metodilla forward. Kun HttpServletRequest-rajapinnan toteuttavalta oliolta pyydetään RequestDispatcher-oliota metodilla getRequestDispatcher, sille annetaan käytettävän jsp-sivun sijainti. Lopullisessa war-tiedostossa, eli tiedostossa, joka sisältää web-sovelluksen, WEB-INF-kansio on juuressa. Käytämme siis hello.jsp:tä varten polkua /WEB-INF/jsp/hello.jsp.
RequestDispatcher dispatcher = request.getRequestDispatcher("/WEB-INF/jsp/hello.jsp");
dispatcher.forward(request, response);
// tai request.getRequestDispatcher("/WEB-INF/jsp/hello.jsp").forward(request, response);
Servlet-luokkaa muokataan siis siten, että metodi processRequest näyttää seuraavalta
Nyt Servletin kuuntelemaan osoitteeseen tuleva pyyntö ohjautuu lopulta kansiossa /WEB-INF/jsp/ olevaan tiedostoon hello.jsp.
Käytännössä siis pyyntö tapahtuu seuraavasti:
1. Käyttäjä tekee palvelimelle pyynnön
käyttäjän selaimella tekemä pyyntö
-------------------> palvelin
2. Palvelin päättelee pyynnön perusteella oikean servletin
palvelin: pyynnön polku?
-------------------> servlet
3. Servletin koodi suoritetaan
4. Vaihtoehtoinen tilanne:
4a) Jos requestdispatcher-olion avulla ei määritellä seuraavaa
kohdetta, vastaus palautetaan käyttäjälle
4b) Muuten, pyyntö ohjataan määritellyyn osoitteeseen, esimerkiksi
toiselle servletille. Servletin tai JSPn sisältämät komennot prosessoidaan
palvelimella. Lopulta vastaus lähetetään takaisin käyttäjälle
Ensiaskeleet dynaamisen tiedon lisäämiseen
Tällä hetkellä sovelluksemme on hieman kankea: sovellus ei näytä mitään palvelinpuolella luotua tietoa.
Selaimelta tulevaa pyyntöä edustavaan HttpServletRequest-olioon voi lisätä attribuutteja, jotka ovat pyynnössä mukana siihen asti kunnes palautettava sivu lähetetään takaisin selaimelle. Kun ohjaamme Servlet-luokassa pyynnön eteenpäin, on kaikki pyyntöön Servlet-luokassa lisätyt attribuutit olemassa vielä JSP-sivua näytettäessä.
JSP-sivu on tarkoitettu dynaamisen tiedon näyttämiseen. JSP:n versioon 2.0 otetun EL-kielen avulla sivulla voidaan käyttää käytännössä kaikkia HttpServletRequest oliolle attribuutiksi lisättyjä olioita. Lisätään seuraavaksi pyyntöön attribuutti "message", jonka sisältö on "ok, ehkä tässä on ideaa".
protected void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
request.setAttribute("message", "ok, ehkä tässä on ideaa");
request.getRequestDispatcher("/WEB-INF/jsp/hello.jsp").forward(request, response);
}
Nyt jsp-sivua renderöitäessä käytössä on attribuutti nimeltä message, jolla on arvo. EL-kielen avulla pyyntöön lisätyn attribuutin arvon voi näyttää sivulla seuraavasti:
Kun ylläolevaa JSP-sivua renderöidään käyttäjälle, sivun renderöijä etsii message-nimisen attribuutin ja asettaa sen sisällön sivulle. Attribuutti aloitetaan JSP-sivulla dollarilla ja aukeavalla aaltosululla ${, ja lopetetaan sulkevalla aaltosululla }.
Servletin osoitteeseen tehtävä pyyntöön luotava vastaus näyttää selaimessa seuraavalta:
Hello World!
Viesti: ok, ehkä tässä on ideaa
Sovelluksen sijainti
Sovelluksemme sijainti palvelimella riippuu palvelimesta ja sovellukselle määritellystä konfiguraatiosta. Sovellukset ovat harvemmin palvelimen juuriosoitteessa, esim. http://palvelin.net/. Yleensä niille on oma aliosoite, esimerkiksi http://palvelin.net/sovellus. Tämä johtaa tilanteeseen, jossa sivulla käytettävien linkkien tulee olla dynaamisia. Esimerkiksi lomakkeiden lähettämisen tulee tapahtua sovellukselle.
Jos HTML-lomakkeen action-kenttä sisältää osoitteen /process, lomake lähetetään käytettävän palvelimen juuriosoitteeseen. Esimerkiksi jos lomake on palvelimella http://palvelin.net/, lähetettäisiin /process-osoitteeseen ohjautuva lomake käytännössä osoitteeseen http://palvelin.net/process -- riippumatta siitä, missä sovellus oikeasti on.
Tämän takia EL-kielessä pääsee käsiksi myös pyynnön tietoihin. Käyttämällä komentoa ${pageContext.request.contextPath} jsp-sivulla, sovelluksen osoitteen saa käyttöön. Käytännössä jos lomakkeen action-kentälle antaa arvon ${pageContext.request.contextPath}/process, lomake lähetetään sovelluksen sisältämään process-osoitteeseen, riippumatta siitä missä osoitteessa lomake oikeasti on.
Erillistä sovelluslogiikkaa
Jos sovelluksemme olisi hieman isompi ja jos koodi olisi Servlet-luokassa, tulisi Servlet-luokasta helposti hyvin raskas. Toteutetaan erillinen viestejä tuottava viestipalvelu. Viestipalvelun rajapinta on seuraavanlainen:
package werkko.helloworld;
public interface MessageService {
public String getMessage();
}
Ainoa rajapinnan MessageService määrittelemä toiminnallisuus on viestin antaminen. Luodaan rajapinnalle konkreettinen toteutus. Luokka TimoSoiniMessageService toteuttaa rajapinnan MessageService ja tarjoaa poliittisia helmiä.
package werkko.helloworld;
import java.util.Random;
public class TimoSoiniMessageService implements MessageService {
private Random random = new Random();
private String[] messages = {
"Tuli iso jytky!",
"Tänään on tilipäivä!",
"Missä EU, siellä ongelma.",
"Se on rikkaiden Neuvostoliitto tämä EU.",
"Kukkahattu ja gebardihattu kuuluvat samaan ravintoketjuun. "
+ "Molemmilla on käsi sinun taskussasi.",
"Yleisen asevelvollisuuden säilyttäminen on Suomelle huomattavasti "
+ "tärkeämpi asia kuin demokratian puolustaminen jossain sellaisessa "
+ "maassa, missä ei edes ole demokratiaa.",
"Jos ei muuta, niin ainakin nuoret oppivat armeijassa kuria. Elämässä "
+ "ei vaan selviä niin, että tekee kaiken aina vaan oman pään "
+ "mukaan. Viimeistään sen huomaa siinä vaiheessa, kun menee "
+ "naimisiin.",
"Sitäkään ei saa unohtaa, että meitä pidetään virallisesta "
+ "puolueettomuudesta huolimatta länsiblokin osana. Se saattaa "
+ "johtaa vielä jossain vaiheessa vaikeuksiin.",
"Keksin itse jytkyn. Tuli iso jytky, kun pitikin.",
"Hallitusvastuu on populistin sudenkuoppa.",
"Pienelle kansalle riittää pieni valhe – suurelle kansanjoukolle "
+ "tarvitaan jo EU."
};
public String getMessage() {
return messages[random.nextInt(messages.length)];
}
}
Lisätään viestipalvelu Servlet-luokkaan ja käytetään sitä processRequest-metodissa.
// importit jne
public class HelloServlet extends HttpServlet {
private MessageService messageService = new TimoSoiniMessageService();
protected void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
request.setAttribute("message", messageService.getMessage());
request.getRequestDispatcher("/WEB-INF/jsp/hello.jsp").forward(request, response);
}
// doGet ja doPost
}
Nyt servletin kuuntelemaan osoitteeseen tehtävä pyyntö tuottaa esimerkiksi seuraavanlaisen vastauksen:
Hello World!
Viesti: Hallitusvastuu on populistin sudenkuoppa.
Juuri toteutettu poliittisia letkautuksia heittelevä Hei Maailma-sovellus on ylläpidettävyydeltään jo siedettävää luokkaa. Periaatteessa sovelluslogiikan vaihtaminen sellaiseksi, joka hakee viimeisimmän uutisen Helsingin sanomien etusivulta vaatisi vain uuden MessageService-rajapinnan toteuttavan luokan tekemistä ja sen vaihtamista HelloServlettiin.
Pyynnössä olevien parametrien käyttäminen
Pyynnön mukana voi lähettää parametreja palvelimelle. GET-tyyppisissä pyynnöissä parametrit ovat osana osoitetta. Esimerkiksi pyyntö osoitteeseen http://palvelin.net/sovellus?parametri1=arvo1¶metri2=arvo2 tekee käytännössä kyselyn osoitteessa http://palvelin.net/sovellus olevaan sovellukseen, ja antaa sovellukselle kaksi parametria. Parametrin parametri1 arvo on arvo1 ja parametri2-parametrin arvo on arvo2.
Servlettien avulla pyynnössä oleviin parametreihin pääsee käsiksi HttpServletRequest-rajapinnan tarjoaman getParameter-metodin avulla. Metodi getParameter palauttaa sekä GET- että POST-tyyppisissä pyynnöissä lähetetyt parametrit. Esimerkiksi seuraavaa Servlet-luokka ottaa pyynnöstä parametrin name ja käyttää sitä osana tervehdysviestiä.
// importit jne
public class HelloServlet extends HttpServlet {
protected void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
String name = request.getParameter("name");
request.setAttribute("message", "Hello " + name);
request.getRequestDispatcher("/WEB-INF/jsp/hello.jsp").forward(request, response);
}
// doGet ja doPost
}
Jos ylläolevan Servlet-luokan kuuntelemaan osoitteeseen tehtäisiin pyyntö, jossa parametrin name arvona on Mikke, olisi processRequest-metodin suorituksen jälkeen attribuutin message arvo Hello Mikke.
Magic 8 Ball
Toteutetaan tässä tehtävässä "Magic 8 Ball", jolta voi kysyä apua ongelmatilanteissa. Web-sovelluksen tulee toimia siten, että aloitussivulla on lomake, jossa on tekstikenttä ja erillinen submit-painike. Tekstikentän name-attribuutin arvon tulee olla "question" ja lomakkeen pyyntötavan POST. Sivu voi näyttää esimerkiksi seuraavalta:
Ask and I shall answer!
Kun kysymys on lähetetty palvelimelle, käyttäjälle näytetään sivu, jossa on sekä käyttäjän kirjoittama kysymys että palvelimen antama vastaus. Sivulta voi myös tehdä uuden kysymyksen, jolloin käyttäjä pääsee takaisin samalle sivulle. Huom! Varmista, että tälläkin sivulla olevan tekstikentän name-attribuutin arvo on "question" ja että lomakkeen pyyntötapa on POST. Sivu voi näyttää esimerkiksi seuraavalta:
Your question was: Will I succeed in this course?
My answer is: Signs point to yes
Ask again and I shall answer again!
Käytä vastauksissa wad.eightball-pakkauksessa olevaa luokkaa Answers, mikä sisältää valmiita Magic 8 Ball-vastauksia.
Vink vink! ${pageContext.request.contextPath}
LoveMeter
Huom! Tämä tehtävä on pilkottu kolmeen pienempään osaan. Vuosien tutkimuksen ja miljoonien polttamisen jälkeen Kumpulan kampuksella on viimeinkin saatu aikaan algoritmi kahden henkilön yhteensopivuuden mittaamiseen. Algoritmin perusrakenne on seuraava:
int minLength = Math.min(name1.length(), name2.length());
int result = 0;
for(int i = 0 ; i < minLength; i++) {
result += (name1.charAt(i) * name2.charAt(i));
}
result += 42;
return result % 100;
Tehtävänäsi on luoda algoritmin käyttöön web-sovellus. Tehtävän tekeminen ohjeistetaan askeleittain.
KumpulaLoveMeter
Toteuta pakkaukseen wad.lovemeter.service luokka KumpulaLoveMeter, joka toteuttaa rajapinnan LoveMeterService. Käytä yllä olevaa algoritmia soveltuvuuden laskemiseen. Testaa luokkaasi.
LoveMeterService loveMeter = new KumpulaLoveMeter();
int match = loveMeter.match("mikke", "kasper");
System.out.println("mikke and kasper match " + match + "%");
mikke and kasper match 80%
LoveServlet
Toteuta pakkaukseen wad.lovemeter.servlet luokka LoveServlet, joka perii luokan HttpServlet. Luokan LoveServlet tulee kuunnella polkua /love.
Toteuta luokan LoveServlet metodi doGet siten, että se ottaa pyynnöstä parametrit name1 ja name2, ja laskee edellisessä tehtävässä toteutetun luokan avulla parametrina annettujen nimien yhteensopivuuden. Tämän jälkeen yhteensopivuus asetetaan nimien kanssa pyynnön attribuuteiksi, ja pyyntö ohjataan eteenpäin.
Ohjaa pyyntö tehtäväpohjassa valmiina tarjottuun polusta /WEB-INF/jsp/love.jsp löytyvään jsp-sivuun.
Huom! Käytä edellisessä kohdassa toteutettua luokkaa KumpulaLoveMeteroliomuuttujana, mutta tietenkin siten, että ohjelmoit rajapintaa käyttäen luokassa LoveServlet.
Lomake tietojen lähettämiseen
Toteuta vielä kansiossa Web Pages olevalle sivulle index.jsp lomake tietojen lähettämiseen. Sivu index.jsp näytetään kun käyttäjä selaa sovelluksen juuriosoitteeseen. Lomakkeessa tulee olla kentät nimillä name1 ja name2. Määrittele kentille myös id:t (name1 ja name2 vastaavasti). Lomake tulee lähettää LoveServlet-servletin kuuntelemaan polkuun.
Lomake voi näyttää esimerkiksi seuraavalta:
Testaa vielä sovellustasi kokonaisuudessaan.
Kun olet saanut tehtävän valmiiksi, lähetä se TMCn tarkastettavaksi.
MVC
MVC (model-view-controller) on ohjelmistoarkkitehtuurityyli, jonka tavoitteena on käyttöliittymän erottaminen sovelluslogiikasta. Model on yleensä näytettävä data, view on itse näkymä, ja controller vastaanottaa käyttäjän tekemät käskyt ja muokkaa niiden pohjalta sekä dataa että näytettävää näkymää.
Miten edellä esitetty Hello Web! -esimerkki liittyy MVC-arkkitehtuuriin? Mikä rooli on jsp-sivuilla, servleteillä, ja pyynnön sisältämällä attribuuteilla?
Dynaamiset JSP-sivut: JSTL ja EL
JSP-sivut ovat käytännössä dynaamista tietoa sisältäviä HTML-sivuja, jotka prosessoidaan palvelimella ennen niiden näyttämistä käyttäjälle. Palvelimella tapahtuvan prosessoinnin yhteydessä JSP-sivu muunnetaan servletiksi, servletti käännetään, ja lopulta servletin tuottama tulostus näytetään käyttäjälle. Tämä mahdollistaa asiakkaan pyyntöön liittyvien tietojen käsittelyn JSP-sivuilla: JSP-sivut ovat servlettejä ja pääsevät täsmälleen samoihin tietoihin käsiksi kuin servletit. JSP-sivuille on myös mahdollista tuottaa sisältöä suoraan Javalla:
<%@page contentType="text/html" pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Hello World!</title>
</head>
<body>
<%
System.out.println("Poor man's logging to server logs!");
out.append("<p>Message to the page</p>");
%>
</body>
</html>
Yllä oleva JSP-sivu tuottaa seuraavanlaisen näkymän, sekä viestin Poor man's logging to server logs! palvelimen logeihin.
Message to the page
That being said, don't do it.: Java-koodin käyttäminen JSP-sivuilla on indikaattori erittäin huonosta suunnittelusta ja yleisesti ottaen johtaa hyvin vaikeasti ylläpidettäviin näkymiin. Erityisesti JSP-sivulla olevassa koodissa sijaitsevan virheen etsiminen on yhtä tuskaa: virheiden stack tracet liittyvät luonnollisesti JSP-sivusta käännetyn servletin koodiin.
On oleellista kuitenkin ymmärtää, että kaikki sivuilla näytettävä tieto luodaan palvelimella.
Java-koodin käyttäminen JSP-sivuilla on kielletty. Tarvitsemme dynaamisuutta sivuillemme: esimerkiksi listojen tulostaminen ei onnistu ilman ohjelmakoodia. Näimme aiemmin esimerkin EL-kielestä, jonka avulla sivulla voi käyttää ja näyttää pyynnössä olevia attribuutteja. EL-kieli oli alunperin osa JSTL-kieltä, joka on kokoelma tägikirjastoja JSP-sivuilla näytettävän datan prosessointiin.
EL
EL eli Expression Language on kieli, jolla pääsee käsiksi mm. pyynnössä oleviin attribuutteihin. EL-kielen lauseet ilmaistaan ${ }-merkinnällä, jonka sisällä on lauseke. Näimme aiemmin yksinkertaisen EL:n käyttöesimerkin jossa pyyntöön lisätään servletissä attribuutti, esim. request.setAttribute("viesti", "attribuutin arvo");, joka näytetään JSP-sivulla, esim. <p>${viesti}</p>.
Olioiden käsittely
EL-kielen piste-operaattorin . avulla pääsee käsiksi attribuutteina olevien olioiden get-metodeihin. Esimerkiksi lause ${auto.hinta} tekee auto-nimellä lisättyyn attribuuttiin metodikutsun getHinta(). Tutkitaan tätä hieman tarkemmin. Oletetaan että käytössämme on seuraava luokka Item.
public class Item {
private String name;
private int price;
public Item(String name, int price) {
this.name = name;
this.price = price;
}
public String getName() {
return this.name;
}
public int getPrice() {
return this.price;
}
}
Jos Item-luokan ilmentymä lisätään pyynnön attribuutiksi, voi ilmentymän get-alkuista metodia kutsua pisteoperaattorin avulla JSP-sivulta.
...
Item tmc = new Item("TMC", 330);
request.setAttribute("item", tmc);
...
Kun olio on lisätty pyynnön attribuutiksi nimellä item, voidaan siihen liittyviin get-metodeihin viitata muodossa ${item.ominaisuus}. Tämä tekisi metodikutsun getOminaisuus(). Metodia getName() voi kutsua seuraavasti:
...
<body>
<p>Ja seuraavana vuorossa on: ${item.name}</p>
</body>
...
Yllä oleva esimerkki luo seuraavanlaisen tulostuksen.
Ja seuraavana vuorossa on: TMC
Vastaavasti Item-olion metodia getPrice() voisi kutsua EL-kielen avulla lauseella ${item.price}.
Collection-tyyppisten ilmentymien käsittely
EL-kielellä on notaatio []Collection-tyyppisten olioiden (esim. listat, mapit, taulukot) käsittelyyn. Esimerkiksi, jos attribuutiksi on asetettu map-niminen hajautustaulu:
Päästään siihen käsiksi map-attribuutin kautta. Tämä oli toki tuttua. Hajautustaulun sisällä oleviin arvoihin taas päästään käsiksi attribuutin kautta, esimerkiksi map-attribuutista voidaan hakea text-avaimella olevaa arvoa komennolla ${map['text']}.
...
<body>
<p>Collection-ilmentymiin pääsee käsiksi: ${map['text']}</p>
</body>
...
Yllä olevan sivun tulostus olisi seuraavanlainen:
Collection-ilmentymiin pääsee käsiksi: tada!
Totuusarvolausekkeet ja laskuoperaatiot
EL-lauseiden sisään voi asettaa myös erilaisia vertailuja ja laskuoperaatioita. Esimerkiksi kahden tuotteen hinnan laskeminen on melko yksinkertaista:
...
Item one = new Item("Milk", 173);
Item another = new Item("Porridge", 222);
request.setAttribute("item1", one);
request.setAttribute("item2", another);
...
Laskuoperaation voi toteuttaa EL-lauseen sisällä. Esimerkiksi lause ${item1.price + item2.price} kutsuu ensin attribuutin item1getPrice()-metodia, ja lisää sen palauttaman arvon attribuutin item2getPrice()-metodin palauttamaan arvoon.
...
<body>
<p>${item1.name} and ${item2.name} cost together ${item1.price + item2.price}.</p>
</body>
...
Yllä oleva esimerkki luo seuraavanlaisen tulostuksen.
Milk and Porridge cost together 395.
Katso lisätietoa erilaisista EL-kielen mahdollisuuksista sivuilta Oraclen sivuilta.
Todellisuudessa, kukaan ei toivottavasti ohjelmoi kauppalistaa siten, että jokainen tuote lisätään erillisenä attribuuttina. Tutustutaan seuraavaksi JSTL-kieleen, jonka avulla sivuille saadaan toiminnallisuutta mm. listojen läpikäyntiin.
JSTL
JSTL eli JSP Standard Tag Library on kokoelma XML-tägikirjastoja, joiden avulla JSP-sivuille voidaan lisätä dynaamista toiminnallisuutta. Ensimmäinen JSTL-spesifikaatio (vuodelta 2002) määrittelee JSTL:n tavoitteeksi JSP-sivuja toteuttavien ihmisten elämän helpottamisen: osalla käyttöliittymäsuunnittelijoista ei ole ohjelmointitaustaa. Koska JSTL-tägit ovat XML:ää, ei niiden käyttö haittaa käyttöliittymäsuunnittelussa. JSTL:ää ja HTML:ää sisältäviä JSP-sivuja voi tarkastella myös suoraan selaimella.
Servlet-APIn versiota 2.5 käytettäessä käytämme JSTL:n versiota 1.2. JSTLn saa käyttöön lisäämällä projektin pom.xml-tiedostoon seuraavan riippuvuuden:
Kun JSTL-riippuvuus on lisätty projektiin, voi JSTL-tägikirjastoja käyttää osana JSP-sivua. Käytettävä tägikirjasto tulee aina esitellä JSP-sivun alussa. Esimerkiksi seuraava määrittely tuo JSTLn ydinkirjaston käyttöön.
Tägikirjastoja käytetään niille määriteltyjen etuliitteiden avulla. Yllä olevassa määrittelyssä ydinkirjastolle määritellään etuliite c, jolloin siihen liittyviin elementteihin pääsee käsiksi <c:-etuliitteen avulla.
JSTL sisältää tägit mm. perusohjelmoinnissa käytettävien kontrollirakenteiden käyttöön, erilaisten tulostusten formatointiin, ja esimerkiksi erilaisten RSS/XML-syötteiden käsittelyyn. Tällä kurssilla hyödynnämme lähinnä kontrollirakenteita.
Toistolauseet: forEach
Meille oleellisin komento on forEach, jota käytetään Collection-rajapinnan toteuttavien kokoelmien läpikäyntiin. Sille määritellään attribuutti items, jonka arvona on EL-kielellä merkattu läpikäytävä joukko. Toinen attribuutti, var, määrittelee muuttujan nimen, johon kokoelmasta otettava alkio kullakin iteraatiolla tallennetaan. Perussyntaksiltaan forEach on seuraavanlainen.
Yllä käytämme attribuuttia nimeltä joukko, ja tulostamme yksitellen sen sisältämät alkiot.
Huom! Klassisin virhe on määritellä iteroitava joukko merkkijonona items="joukko". Tämä ei luonnollisesti toimi.
Iteroitavan joukon alkioiden ominaisuuksiin pääsee käsiksi EL-kielellä. Tutkitaan seuraavaa esimerkkiä, jossa listaan lisätään kaksi esinettä, lista lisätään pyyntöön, ja lopulta näytetään JSP-sivulla.
...
Item one = new Item("Milk", 173);
Item another = new Item("Porridge", 222);
List<Item> list = new ArrayList<Item>();
list.add(one);
list.add(another);
request.setAttribute("list", list);
...
...
<p>And the menu is:</p>
<ol>
<c:forEach var="item" items="${list}">
<li>${item.name}</li>
</c:forEach>
</ol>
...
Harjoitellaan vielä hieman JSTL:n ja EL:n käyttöä. Tässä tehtävässä toteutetaan pyyntöön lisättyjen albumeiden listaus JSP-sivulla. Kannattaa tutustua luokkiin Album ja ListServlet ennen aloittamista. JSTL-riippuvuus on lisätty valmiiksi projektin pom.xml-tiedostoon.
Albumien nimien listaaminen
Muokkaa kansiossa WEB-INF/jsp olevaa sivua list.jsp siten, että se tulostaa attribuuttina olevien albumien nimet. Albumit on säilötty listaan, joka on pyynnössä attribuuttina albums.
Albumien kappaleiden lisääminen
Lisää list.jsp sivulle toiminnallisuus albumien sisältämien kappaleiden listaamiseen. Vinkki: Kun käyt edellisessä osassa albumeita läpi, jokainen yksittäinen albumi on olio, johon EL-kielen avulla voi viitata.
The end of viikko 1
Minkälainen kansiorakenne web-sovelluksissa on ja mikä on tiedoston web.xml rooli?
Mikä on Maven ja mitä se tekee?
Miten HTTP-protokollan pyyntötavat GET ja POST eroavat toisistaan?
Mistä tiedämme missä web-osoitteessa palvelinsovelluksemme sijaitsee?
Mitä ovat luokat HttpServletRequest ja HttpServletResponse, ja mitä ne tekevät?
Mikä on pyynnön parametri? Mikä on pyynnön attribuutti? Miten pyyntöön voidaan lisätä parametri?
The start of viikko 2
Hello Spring
Spring on sovelluskehys, joka tarjoaa apuvälineitä komponenteista koostuvien sovellusten toteuttamiseen ja testaamiseen. Käytännössä oman Spring-sovelluskehystä käyttävän sovelluksen arkkitehtuuri kootaan valitsemalla komponentit, joita sovelluksessa tarvitaan. Spring-sovelluskehyksen tehtävänä on toimia liimana komponenttien välillä, mutta se tarjoaa myös omia yleiskäyttöisiä komponentteja mm. web-sovellusten kehittämiseen.
Tässä kappaleessa käymme muutamia Spring-sovelluskehyksen tarjoamia apuvälineitä läpi, jonka jälkeen pohdimme niiden rakennetta. Käytössämme on Spring-sovelluskehyksen versio 3.2.4.RELEASE.
Tutustutaan "Hello World!"-tyyppisen web-sovelluksen toteuttamiseen Springin avulla.
Riippuvuudet ja peruskonfiguraatio
Springin web-toiminnallisuuden peruskiven tarjoaa komponentti spring-webmvc, jonka saa käyttöön lisäämällä pom.xml-tiedostoon seuraavan riippuvuuden. Määritelmä pyytää Mavenia noutamaan käyttöömme spring-webmvc-komponentin sekä komponentit, joista komponentti spring-webmvc riippuu.
Web-sovelluksia rakennettaessa Spring-sovelluskehys käynnistetään Spring-sovelluskehyksen tarjoaman DispatcherServlet -servletluokan avulla. DispatcherServlet-luokan tehtävänä on muun muassa sovellukseen tulevien pyyntöjen kuunteleminen sekä niiden ohjaaminen pyyntöjä käsitteleville luokille.
Käytännössä DispatcherServlet toteuttaa ns. Front Controller-suunnittelumallin, jossa kaikille sovellukseen tuleville pyynnöille tarjotaan keskitetty käsittelypaikka. Tällöin kaikki web-sovellukseen liittyvät pyynnöt ohjataan ensin yhdelle kontrollipalvelulle, esimerkiksi servletille, joka ohjaa ne eteenpäin riippuen pyynnöstä ja pyynnössä haluttavasta resurssista.
Tyypillinen esimerkki Front Controllerin käytöstä on käyttäjän oikeuksien varmistaminen. Koska kaikki pyynnöt ohjataan ensin tietylle servletille, voidaan servletissä tarkistaa mm. käyttöoikeuksien olemassaolo, sekä mahdollisesti hakea käyttäjäkohtaisia tietoja. Toinen esimerkki on Wizard-tyyppiset sovellukset, joissa sivujen näyttöjärjestys on erittäin tärkeä. Tässä Front Controller voi helposti kontrolloida sivujen näyttöjärjestystä.
Front Controller-suunnittelumallia käytetään web-sovellusten toteuttamiseen liittyvän "bulk"-koodin piilottamiseen. Pyyntöjen prosessoinnit, ohjaukset, ym. tulee ohjelmointikielestä riippumatta aina toteuttaa. Sovelluskehykset tarjoavat valmiit rungot, joita käyttämällä ohjelmoija voi keskittyä web-sovelluksen oleellisempiin asioihin. Huomattava osa aktiivisessa käytössä olevista sovelluskehyksistä käyttää Front Controller-suunnittelumallia, mm. Zend, Symfony, Ruby on Rails, ASP .NET MVC ja Spring.
Esimerkki: Oma Front Controller Servleteillä
Toteutetaan yksinkertainen Front Controller-servlet. Ajatuksena on se, että kaikki pyynnöt ohjataan ensin toteuttamallemme luokalle, jonka tehtävänä on: (1) ohjata pyynnöt niiden käsittelyyn erikoistuneille luokille, (2) hoitaa pyyntöihin liittyvät perustoiminnallisuudet. Kaikkien pyyntöjen ohjaaminen tietylle Servlet-luokalle onnistuu lisäämällä web.xml-dokumentin konfiguraatioon tähden *. Seuraava konfiguraatio ohjaa kaikki polkuun /app/ ja sen alle tulevat pyynnöt servletille FrontControllerServlet.
Tyypillisiä kaikille servleteille yhteisiä tehtäviä ovat vastauksen merkistön asettaminen (response.setContentType("text/html;charset=UTF-8")) sekä pyynnön ohjaaminen JSP-sivulle (request.getRequestDispatcher("/WEB-INF/kansio/sivu.jsp").forward(request, response)).
Luodaan näiden pohjalta runko FrontControllerServlet-toteutukselle.
Toteutetaan erillinen rajapinta Controller, joka määrittelee kaksi metodia. Toinen metodi palauttaa polun, johon tulevat pyynnöt ohjataan rajapinnan ilmentymälle, ja toinen käsittelee pyynnön ja palauttaa tiedon sivusta, johon pyyntö ohjataan.
Luodaan ensimmäinen konkreettinen kontrolleritoteutus ListController. Toteutus kuuntelee sovelluksen polkua list, lisää pyyntöön listan merkkijonoja, ja palauttaa JSP-sivuun osoittavan osoitteen.
// ...
public class ListController implements Controller {
@Override
public String getPath() {
return "list";
}
@Override
public String processRequest(HttpServletRequest request,
HttpServletResponse response) throws Exception {
request.setAttribute("list", Arrays.asList("hello", "world"));
return "/WEB-INF/jsp/list.jsp";
}
}
Muutetaan luokkaa FrontControllerServlet siten, että se tuntee Controller-rajapinnan toteuttamat luokat. Lisäämme kontrollerit init-metodissa, jota palvelin kutsuu Servlet-luokan luonnin yhteydessä. Tämän voisi toteuttaa myös esimerkiksi Javan reflektion avulla, jolloin luokan FrontControllerServlet ei tarvitsisi ennalta tietää Controller-rajapinnan toteuttamista luokista. Pitäydymme kuitenkin kevyemmässä esimerkissä.
// ...
public class FrontControllerServlet extends HttpServlet {
private Map<String, Controller> pathToControllerMap;
@Override
public void init() {
pathToControllerMap = new TreeMap<String, Controller>();
Controller listController = new ListController();
pathToControllerMap.put(listController.getListenedPath(), listController);
}
protected void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
// haetaan toteutus, joka sopii haetulle polulle
Controller controller = getController(request.getRequestURI());
if (controller == null) {
// jos sopivaa toteutusta ei löydy, kerrotaan siitä
response.setStatus(HttpServletResponse.SC_NOT_FOUND);
response.getWriter().println("404: " + request.getRequestURI());
return;
}
// ohjataan prosessointi kontrollerille, ja otetaan sivu, johon pyyntö ohjataan
String page = controller.processRequest(request, response);
// ohjataan pyyntö sivulle, jota kontrolleri ehdottaa
request.getRequestDispatcher(page).forward(request, response);
}
private Controller getController(String uri) {
if (!uri.contains("/")) {
return pathToControllerMap.get(uri);
}
uri = uri.substring(uri.lastIndexOf("/") + 1);
return pathToControllerMap.get(uri);
}
// HttpServlet-luokan metodit doGet ja doPost kutsuvat processRequest-metodia
}
Luodaan seuraavaksi kontrolleri tiedon lisäämiseen. Luokka AddController saa pyynnön mukana dataa, jota sen pitää tallentaa myöhempää käyttöä varten. Tiedon tallentaminen jää tekijän vastuulle.
// ...
public class AddController implements Controller {
@Override
public String getListenedPath() {
return "add";
}
@Override
public String processRequest(HttpServletRequest request,
HttpServletResponse response) throws Exception {
String information = request.getParameter("information");
// tallennetaan tieto
return "/WEB-INF/jsp/add.jsp"; // ???
}
}
Huomaamme palautettavan sivun osoitetta tarkastellessamme, että rikomme aiemmin mainittua sääntöä tiedon tallentamiseen liittyen. Jos pyynnössä tallennetaan tietoa, tulee se ohjata uudelleen tuplatallennusten estämiseksi. Joudumme siis toteuttamaan mekanismin pyyntöjen uudelleen ohjaamiselle.
Koska pyyntöjen eteenpäin ohjaaminen on luokan FrontControllerServlet-vastuulla, ei uudelleenohjausta voi määritellä Controller-rajapinnan toteuttamissa luokissa.
Ratkaistaan ongelma määrittelemällä sääntö. Jos metodin processRequest palauttama merkkijono sisältää alkuosan redirect:, tulee pyyntö ohjata uudestaan redirect:-osaa seuraavaan osoitteeseen. Muutetaan luokkaa AddController siten, että siihen saapuvat pyynnöt ohjataan lopulta list-osoitetta kuuntelevalle kontrollerille.
// importit
public class AddController implements Controller {
// mm. tiedon tallennuspaikka
@Override
public String getListenedPath() {
return "add";
}
@Override
public String processRequest(HttpServletRequest request,
HttpServletResponse response) throws Exception {
String information = request.getParameter("information");
// tallennetaan tieto
return "redirect:list";
}
}
Muokataan luokkaa FrontControllerServlet siten, että se ottaa huomioon Controller-tyyppisten olioiden erilaiset palautukset. Jos metodin processRequest palauttamassa merkkijonossa on alkuosa redirect:, pyydetään käyttäjää tekemään uudelleenohjaus. Muulloin pyyntö ohjataan määritellylle JSP-sivulle. Luokkaa myös refaktoroidaan hieman.
// ...
public class FrontControllerServlet extends HttpServlet {
private static final String REDIRECT_PREFIX = "redirect:";
private Map<String, Controller> pathToControllerMap;
// init-metodi, jossa kontrollerit luodaan ja lisätään pathToControllerMap-olioon
protected void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
// haetaan sopiva kontrolleri
Controller controller = getController(request.getRequestURI());
if (controller == null) {
// jos kontrolleria ei löydy, palautetaan statusviesti 404
response.setStatus(HttpServletResponse.SC_NOT_FOUND);
response.getWriter().println("404: " + request.getRequestURI());
return;
}
// suoritetaan pyyntö löydetyllä kontrollerilla
executeControllerAndResolveView(controller, request, response);
}
// suoritetaan pyyntö ja ohjataan pyynnön vastaus näkymän
// päättelevälle metodille
private void executeControllerAndResolveView(Controller controller,
HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
String resultPath = null;
try {
resultPath = controller.processRequest(request, response);
} catch (Exception ex) {
throw new ServletException(ex);
}
resolveView(resultPath, request, response);
}
// pyyntöön liittyvän näkymän etsiminen
private void resolveView(String resultPath,
HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
// jos vastaus alkaa etuliitteellä "redirect:", käyttäjälle
// tulee palauttaa pyyntö uudelleenohjaukseen
if (resultPath.startsWith(REDIRECT_PREFIX)) {
String redirectTo = resultPath.substring(REDIRECT_PREFIX.length());
// metodi sendRedirect lähettää käyttäjälle tiedon sivun muualla
// sijaitsemisesta. Käytännössä selain tekee uuden kyselyn vastauksessa
// tulevaan osoitteeseen.
response.sendRedirect(redirectTo);
} else {
request.getRequestDispatcher(resultPath).forward(request, response);
}
}
// ...
Yllä oleva Front Controller kuitenkin rikkoo oliosuunnittelun hyviä periaatteita. Luokalla on monta vastuuta: se ohjaa pyynnöt kontrollerille ja päättelee kontrollerin vastauksen perusteella palautettavan sivun. muun muassa palautettavan sivun päättelyyn kannattaisi tehdä erillinen luokka. Jätämme sen kuitenkin tässä tekemättä.
Lisätään web.xml-tiedostoon DispatcherServlet-servletin määrittely, jolloin käytettävä web-palvelin osaa ladata sen käyttöön sovellusta käynnistettäessä. Alla olevassa konfiguraatiossa kerromme erikseen, mistä kohta luomamme erillinen konfiguraatiotiedosto löytyy (contextConfigLocation), sekä pyydämme palvelinta lataamaan DispatcherServlet-luokan käyttöömme heti palvelimen käynnistyessä (load-on-startup arvo 0). Lisäksi määrittelemme, että kaikki sovelluksen osoitteeseen /app/ tai sen alle tulevat pyynnöt ohjataan DispatcherServlet-luokalle.
Luodaan WEB-INF -kansion sisälle kansio spring sekä sinne tiedosto spring-base.xml. Tämän jälkeen projektiin liittyvän webapp-kansion rakenne on (esimerkiksi) seuraava.
../src/main/webapp$ tree
├── index.jsp
├── META-INF
│ └── context.xml
└── WEB-INF
├── spring
│ └── spring-base.xml
└── web.xml
../src/main/webapp$
Kansio META-INF sisältää mm. NetBeansin lisäämää metatietoa, eikä ole tässä tapauksessa oleellinen. Sovelluksessa on jsp-sivu index.jsp, WEB-INF-kansiossa oleva web.xml, sekä WEB-INF-kansion sisällä olevassa spring-kansiossa oleva tiedosto spring-base.xml. Tiedostoa spring-base.xml käytetään sovelluskehyksen alustamiseen. Muokataan tiedostoa siten, että se sisältää seuraavan konfiguraatioloitsun.
Yllä oleva rakenne sisältää konfiguraatiotiedoston käyttämien XML-skeemojen sijainnit. Käytännössä XML-skeemat määrittelevät dokumentin hyväksyttävän rakenteen. Oleellisin osa konfiguraatiota on rivi, joka sisältää tekstin component-scan.
<context:component-scan base-package="wad" />
Rivi kertoo sovellukselle, että sen tulee etsiä pakkauksen wad sisältä ja sen alipakkauksista sovellukseen liittyviä tiedostoja. Sovelluksemme lähdekoodit tullaan siis asettamaan pakkaukseen wad tai sen alle.
Hyödynnetään samalla Springiä merkistöongelmien korjaamiseen lisäämällä seuraava määritelmä web.xml-tiedoston alkupäähän.
Selainten ja palvelinten välisessä matalan tason kommunikoinnissa kaikki viestit siirretään binäärimuodossa joukkona nollia ja ykkösiä. Binäärimuotoinen data käännetään tekstiksi sovitun merkistökoodauksen avulla. Merkistökoodauksia on useita erilaisia, joista perinteisin lienee ASCII (American Standard Code for Information Interchange). ASCII-merkistössä jokainen merkki kuvataan 8 bitin avulla, josta 7 bittiä on merkeille (viimeinen on esim. pariteettibitti, jota voidaan käyttää merkin oikeellisuuden tarkistamiseen).
ASCII-merkistö ei juurikaan tue erikoismerkkejä. Esimerkiksi suomessa käytetyille ääkkösille ei ole kuvausta ASCII-merkistössä. Erikoismerkkien tarpeen vuoksi on kehitetty lukuisia standardeja, mm. ISO-8859-versio. Merkistö ISO-8859-1 sisältää tuen mm. lähes kaikille suomen kielessä käytettäville merkeille, ja sitä käytetään paljon selainten ja palvelinten välisessä kommunikoinnissa.
Nykyisin web-sivuilla eniten käytetty merkistö on UTF-8, joka kuvaa merkit 8-32 bitin avulla.
Koska erilaisia merkistöjä on satoja ja käyttöjärjestelmävalmistajilla on usein hieman standardeista poikkeava oma merkistö, tulee palvelimella ja selaimella olla yhteisymmärrys käytettävästä merkistöstä. Yhteisymmärrys luodaan sisällyttämällä pyynnön ja vastauksen otsakkeisiin tieto käytetystä merkistöstä.
Esimerkiksi pyyntöön voi lisätä otsakkeen Accept-Charset, jolla kerrotaan toivottu merkistö.
Accept-Charset: utf-8
Vastauksessa käytetään otsaketta Content-Type vastauksen sisällön tyypin ja käytetyn merkistön ilmaisemiseen.
Content-Type: text/html; charset=utf-8
JSP-sivuilla käytetään usein lisäksi erillistä otsakekenttää, jolla pyritään valmistamaan käytetyn merkistön oikeellisuus. Esimerkiksi alla olevalla otsakkeella kuvataan sivun sisällöksi text/html ja merkistöksi UTF-8.
Merkistön sopiminen tapahtuu usein automaattisesti, mutta käytännössä ohjelmoijien tulee varautua merkistöongelmiin. Esimerkiksi servlettien alkuun asetetaan yleensä komento response.setContentType("text/html;charset=UTF-8"), joka lisää Content-Type-otsakkeen vastaukseen.
Mielenkiintoisia ongelmia tarjoavat tilanteet, joissa otsaketiedoissa kerrotaan sisällön olevan tiettyä tyyppiä, mutta sisältö onkin erilaista. Jos merkistö on asetettu ASCII-muotoiseksi, mutta sisältö sisältää ASCII-aakkostossa määrittelemättömiä merkkejä, on sisällön tulkinta sovelluksen vastuulla. Merkistöongelmat voivat johtua myös palvelimen käyttämistä kolmannen osapuolen komponenteista. Esimerkiksi tietokannat tallentavat dataa yleensä tietyllä merkistöllä: jos ISO-8859-1 -merkistöä käyttävään tietokantaan tallennetaan UTF-8-muotoista dataa, tulee ainakin osa tallennetusta datasta olemaan korruptoitunutta.
Checklist
Jos sovelluksessasi on merkistöongelma, aloita seuraavista tarkistuksista:
Varmista että pyynnöt ja vastaukset sisältävät otsakkeen merkistön asettamiseen.
Varmista että JSP-sivujen alussa on alla oleva komento, jolla varmistetaan merkistön asetus.
Varmista että tietokanta on konfiguroitu käyttämään haluttua merkistöä.
Varmista että palvelin on konfiguroitu käyttämään haluttua merkistöä.
Filtterit
Javan Servlet API sisältää servlettien lisäksi myös filttereitä. Filtterit ovat pyynnön ja vastauksen prosessoijia, joilla voidaan käsitellä pyyntöä ja vastausta ennen niiden servletille saapumista, sekä sen jälkeen kun servlet-koodi on suoritettu. Hyvin yleinen käyttötapa filtterille on merkistön asetus: yksittäistä filtteriä voidaan käyttää otsakkeiden asettamiseen pyyntöön ja vastaukseen.
Filtterit konfiguroidaan web.xml-tiedostoon lähes samoin kuin servletit. Poikkeuksena on se, että servlet-nimen sijaan käytetään elementtiä nimeltä filter. Alla on konfiguroitu kuvitteellinen SimpleFilter kuuntelemaan kaikkia web-sovellukseen tulevia pyyntöjä.
Spring-sovelluskehyksellä on valmis filtteri, joka muuttaa kaikki pyynnöt ja vastaukset (esimerkiksi) UTF-8 merkistöä käyttäväksi: CharacterEncodingFilter. Filtterin saa käyttöön lisäämällä sen web.xml-tiedostoon.
Lisätään luokalle HelloWorldController @Controller-annotaatio.
package wad;
import org.springframework.stereotype.Controller;
@Controller
public class HelloWorldController {
}
Pyyntöjä käsitteleviin luokkiin, eli kontrollereihin, voi määritellä metodeja, jotka käsittelevät palvelimelle lähetetyt pyynnöt. Luodaan ensimmäinen metodi public void helloWorld(HttpServletRequest request, HttpServletResponse response). Luokan HttpServletRequest ilmentymä request sisältää pyynnön tiedot, ja HttpServletResponse-luokan ilmentymä response sisältää pyynnölle vastauksena lähetettävän sisällön.
package wad;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Controller;
@Controller
public class HelloWorldController {
public void helloWorld(HttpServletRequest request, HttpServletResponse response) {
}
}
Tarvitsemme lisäksi vielä @RequestMapping-annotaation, jonka avulla määrittelemme tarkemmin kuunneltavan osoitteen sekä metodin. Annotaatiolla @RequestMapping(value = "hello", method = RequestMethod.GET) kerromme, että annotoitu metodi kuuntelee osoitteeseen hello tulevia pyyntöjä, joiden pyyntötyyppi on GET.
Lisätään koodiin vielä tekstin Hello World! kirjoittaminen vastaukseksi. Koska HttpServletResponse-luokan metodi getWriter() voi heittää poikkeuksen, lisätään helloWorld-metodille poikkeuksen heittäminen.
Kun sovelluksen käynnistää palvelimella ja avaa selaimella osoitteen /sovelluksen-polku/app/hello, jossa näemme seuraavanlaisen vastauksen.
Hello world
Pääsemme käsiksi pyynnössä oleviin parametreihin täsmälleen samalla tavalla kuin servlettejä käyttämällä. Esimerkiksi edellisen "Hello world" tulostuksen voi muuttaa hyödyntämään pyynnössä olevaa parametria "nimi" seuraavasti:
Pyynnön ohjaaminen JSP-sivulle onnistuu myös kuten ennenkin. Alla olevassa esimerkissä luetaan pyynnöstä parametri "nimi", asetetaan JSP-sivulla näytettävä attribuutti "viesti", sekä ohjataan pyyntö kansiossa "/WEB-INF/jsp/" olevalle "sivu.jsp"-tiedostolle.
Pyynnön vastaanottaminen ja käsittely web-sovelluksessa, osa 2
Yllä olevassa esimerkissä ohjelmoimme "Servletkoodia Springillä". Tehdään edelliset esimerkit uudestaan siten, että hyödynnämme Spring-sovelluskehystä paremmin.
Pyyntöjä käsittelevät metodit
Spring päättelee pyyntöjä käsittelevien metodien parametrit automaattisesti, ja osaa esimerkiksi hakea luokkien HttpServletRequest ja HttpServletResponse sisältämiä olioita käyttöömme. Sen sijaan, että määrittelemme pyynnön käsittelevät metodin parametreiksi edellä mainitut luokat ja pyydämme HttpServletResponse-luokan ilmentymältä PrintWriter-oliota metodilla getWriter, voimme ottaa sen käyttöömme suoraan.
package wad;
import java.io.PrintWriter;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
@Controller
public class HelloWorldController {
@RequestMapping(value = "hello", method = RequestMethod.GET)
public void helloWorld(PrintWriter writer) {
writer.println("Hello world");
}
}
Yllä olevalla esimerkillä Spring hakee automaattisesti HttpServletResponse-olion sisältämän PrintWriter-olion ilmentymän, ja asettaa sen metodin helloWorld käyttöön.
Toinen tapa vastauksen suoraan kirjoittamiseen käyttämiselle on annotaation @ResponseBody asettaminen metodille. Annotaatiolla @ResponseBody kerrotaan Springille, että metodin palauttama arvo palautetaan pyynnön vastauksena käyttäjälle.
Yllä olevassa esimerkissä metodi palauttaa String-tyyppisen arvon, joka ohjataan vastauksena käyttäjälle.
Pyynnöissä olevat parametrit
Pyynnössä olevat parametrit voidaan myös asettaa osaksi metodimäärittelyä. Metodin parametria edeltävällä annotaatiolla @RequestParam voidaan antaa parametrin nimi, jonka arvo asetetaan metodin parametriin. Esimerkiksi pyynnössä oleva parametri "nimi" saadaan asetettua osaksi metodimäärittelyä seuraavasti.
Parametrille voidaan asettaa myös oletusarvo lisäämällä annotaatioon attribuutti defaultValue. Alla olevassa esimerkissä nimi on oletuksena "B.A. Ware".
Huom! Et voi käyttää tässä tapauksessa @ResponseBody-annotaatiota, sillä sen avulla metodin palauttama arvo ohjataan suoraan käyttäjälle.
Jos haluamme välttää jsp-sivujen polun kirjoittamista palautettavaan merkkijonoon, voimme määritellä tiedostoon spring-base.xml erillisen päättelijän, joka lisää palautettavaan merkkijonoon etuliitteen ja loppuliitteen.
Servlet-ohjelmoinnissa attribuuttien lisääminen pyyntöön tapahtui HttpServletRequest-luokan ilmentymän tarjoaman setAttribute-metodin avulla. Spring abstrahoi attribuutit erilliseen Model-rajapintaan, jonka voi asettaa yhdeksi pyyntöjä käsittelevän metodin parametreista.
Alla olevassa esimerkissä pyyntöön lisätään attribuutti "viesti", jonka arvona on "Hello world". Tämän jälkeen pyyntö ohjataan esilliselle JSP-sivulle.
Parametrien lisääminen pyyntöön onnistuu nyt helpohkosti. Alla olevassa esimerkissä etsitään pyynnöstä parametria, jonka nimi on "nimi". Jos parametri löytyy, metodin helloWorld parametriksi nimi asetetaan sen arvo, muulloin arvoksi asetetaan "B.A. Ware". Metodissa parametri nimi asetetaan pyynnön attribuutiksi, jonka nimi on "viesti", ja lopulta pyyntö ohjataan JSP-sivulle polussa "/WEB-INF/jsp/sivu.jsp".
Rakennetaan Spring WebMVC-kehyksen avulla toimiva dynaaminen verkkosivu, joka koostuu controller-luokasta ja JSP-sivusta.
Konfiguraatio ja HelloWorldController
Lisää riippuvuus spring-webmvcpom.xml-tiedostoon. Käytä Springin versiota 3.2.4.RELEASE.
Konfiguroi tämän jälkeen tiedostoon spring-base.xml olioiden automaattinen lataaminen oliokontekstiin pakkauksesta wad ja sen alipakkauksista, sekä näkymänpäättelijä InternalResourceViewResolver. Aseta päättelijälle kentän prefix arvoksi /WEB-INF/jsp/ ja kentän suffix arvoksi .jsp.
Luo tämän jälkeen pakkaukseen wad.spring.web.helloworld luokka HelloWorldController. Kerro Springille että kyseessä on controller-luokka, eli lisää luokalle annotaatio @Controller.
Lisää luokalla HelloWorldController metodi public String sayHello(Model model), joka käsittelee sovellukselle tulevia HTTP-pyyntöjä. Määrittele metodille annotaatio @RequestMapping, joka kuuntelee polkuun "hello" tulevia GET-tyyppisiä pyyntöjä. Huomaa että DispatcherServlet käsittelee vain polkuun /app/ ja sen alle tulleita pyyntöjä.
Metodin sayHello tulee asettaa Model-oliolle attribuutti message, jonka arvo on "Great Scott!". Metodin tulee lisäksi palauttaa merkkijono, jonka avulla pyyntö ohjataan JSP-sivuun sijainnissa /WEB-INF/jsp/hello.jsp (muista miten konfiguroit InternalResourceViewResolverin).
View: hello.jsp
Luo hakemistoon /WEB-INF/jsp JSP-sivu hello.jsp. Hakemisto löytyy NetBeansin projektinäkymästä Web Pages-kansion alta. JSP-sivulla tulee olla teksti Hello World! ja EL-kielellä tehty viittaus sayHello-metodin asettamaan attribuuttiin message, jotta viesti näytetään sivulla.
Password Generator
Tehtävässä rakennetaan salasanageneraattori, jolta saa uuden salasanan aina kun generaattorin verkkosivu ladataan.
PasswordGeneratorController
Luo pakkaukseen wad.passwordgenerator luokka PasswordGeneratorController ja lisää sille kontrolleriluokkien tarvitsema annotaatio.
Toteuta luokkaan PasswordGeneratorController metodi public String generatePassword(), joka palauttaa uuden salasanan merkkijonona. Käytä salasanan generointiin UUID-luokan staattista metodia randomUUID(). Voit muuttaa UUID-luokan ilmentymän merkkijonoksi kaikille olioille yhteisellä toString-metodilla.
Toteuta seuraavaksi luokkaan PasswordGeneratorController metodi public String newPassword(Model model), joka vastaa polkuun new-password tuleviin pyyntöihin. Metodin newPassword tulee generoida uusi salasana generatePassword-metodia käyttäen, sekä asettaa luotu salasana Model-olion attribuutiksi avaimella password. Tämän jälkeen metodi newPassword palauttaa näkymän nimen, joka johtaa seuraavassa kohdassa tehtävälle JSP-sivulle password.jsp.
Huomaathan että DispatcherServlet kuuntelee vain polkua /app/ ja sen alle tulevia pyyntöjä.
View: password.jsp
Luo hakemistoon /WEB-INF/jsp JSP-sivu password.jsp. JSP-sivulla tulee olla teksti Password Generator ja EL-kielinen viittaus PasswordGeneratorController-luokassa asetettuun attribuuttiin password, jotta generoitu salasana näytetään sivulla.
Esimerkki: Laskuri ja POST/Redirect/GET
Luodaan sovellus, jonka tehtävänä on pitää kirjaa klikkauksista. Sovellus tulee toimimaan hieman kuten seuraava painike: kun nappia painetaan, siinä oleva luku kasvaa.
Luodaan sovellusta varten JSP-sivu jossa on nappi. Koska pyyntömme tulevat muuttamaan palvelimella olevaa dataa, asetetaan sovellus lähettämään tieto POST-muodossa palvelimelle.
Ylläolevalla sivulla oleva komento <c:url value="/app/increment"/> on JSTL:n tarjoama vastine EL-kielen tavalle ${pageContext.request.contextPath}/app/increment.
Luodaan seuraavaksi pyyntöjä käsittelevä luokka. Toteutetaan luokka siten, että käytössämme on kaksi erillistä polkua. POST-tyyppinen pyyntö polkuun increment kasvattaa laskurin lukua, ja GET-tyyppinen pyyntö polkuun count näyttää sovellukseen liittyvän JSP-sivun, jolla näkyy laskurin nykyinen arvo. Arvoa kasvattava osoite pidetään erillisenä, sillä näin osoitetta hakevat ulkopuoliset palvelut (esimerkiksi hakukoneiden web-sivujen indeksoijat ym...) eivät ota siihen yhteyttä.
Mutta! Nyt sivumme ei näytä laskurin arvoa POST-pyynnön jälkeen. Yksi ratkaisu olisi lisätä Model-attribuutti myös increment-metodille, ja asettaa laskurin arvo osaksi mallia myös siellä. Tämä ei kuitenkaan ole hyvä ratkaisu, sillä tällöin tekisimme saman asian kahdesti.
Ratkaistaan ongelma tekemällä uudelleenohjaus increment-polusta count-polkuun. Palauttamalla kontrolleriluokan metodista merkkijono, jossa on alkuliite "redirect:", voimme ohjata pyynnön uuteen osoitteeseen. Esimerkiksi merkkijonolla "redirect:count" saadaan käyttäjä ohjattua osoitteeseen "count".
Muokataan vielä sovelluksen juuripolussa olevaa index.jsp-tiedostoa siten, että sen tehtävä on ohjata käyttäjä nykyisen lukeman sisältävälle sivulle. Uudelleenohjauksen saa tehtyä JSTL:n avulla komennolla <c:redirect url="/app/count"/>.
POST/Redirect/GET on yleinen web-suunnittelumalli, jonka avulla voidaan välttää osa toisteisista lomakkeiden lähetyksistä sekä helpottaa kirjanmerkkien käyttöä. Käytännössä ajatuksena on pyytää käyttäjä tekemään GET-pyyntö onnistuneen POST-pyynnön jälkeen. GET-pyynnössä palautetaan sivu, jossa näytetään muuttuneet tiedot, kun taas POST-pyynnöllä tehdään tiedon muuttaminen.
Luokkien selkeät vastuut, case Laskuri
Vaikka edellisessä esimerkissä toteuttamamme sovellus toimii, rikomme siinä oliosuunnittelun periaatteita. Ohjelmistoja rakennettaessa jokaisella luokalla pitäisi olla yksi selkeä vastuu, ja tällä hetkellä luokka CountController tekee oikeastaan kahta asiaa: sekä hallinnoi sekä pyyntöjä että konkreettista laskurin lukua.
Toteutetaan vaihtoehtoinen laskuri, joka eriyttää laskemistoiminnan erilliseen palveluun. Toteutetaan ensin palvelulle rajapinta CountService, joka tarjoaa kaksi metodia: luvun kasvattamisen (increment) ja luvun hakemisen (getCount).
package wad;
public interface CountService {
void increment();
int getCount();
}
Toteutetaan tämän jälkeen luokka InMemoryCountService, jonka tehtävänä on pitää kirjaa laskusta. Luokka InMemoryCountService toteuttaa rajapinnan CountService.
package wad;
public class InMemoryCountService implements CountService {
private int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}
Luokka kapseloi muuttujan count, joka aiemmin oli osana luokkaa CountController. Muokataan seuraavaksi edellisessä esimerkissä toteuttamaamme CountController-luokkaa siten, että se hyödyntää juuri luomaamme palvelua.
Kontrollerin rakenne pysyi siis lähes samana kuin aiemminkin, mutta nyt vastuu laskun ylläpidosta on siirretty erilliselle palvelulle.
Riippuvaisuus vain rajapinnoista, case Laskuri
Laskurisovelluksemme on oikeasti melko hieno, mutta rikomme taas oliosuunnittelun periaatteita. Käyttämämme luokat tulisi toteuttaa mahdollisimman riippumattomaksi toisistaan, mutta tällä hetkellä kontrollerimme CountController riippuu konkreettisesta luokasta InMemoryCountService, sillä luokan InMemoryCountService ilmentymä alustetaan luokassa CountController. Luokan CountController tulisi tuntea vain käytettävä rajapinta.
Spring tukee riippuvaisuuksien injektointia, mikä mahdollistaa ilmentymien automaattisen kytkemisen rajapintoihin. Voimme määritellä luokan automaattisesti muistiin ladattavaksi annotaatiolla @Service. Lisätään luokalle InMemoryCountService @Service-annotaatio.
package wad;
import org.springframework.stereotype.Service;
@Service
public class InMemoryCountService implements CountService {
private int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}
Nyt Spring lataa käynnistyessään luokan InMemoryCountService muistiin.
Voimme merkitä annotaatiolla @Autowired muuttujia ja metodeja, joihin muistiin ladattuja luokkia yritetään asettaa. Muokataan CountController-luokkaa siten, että pyydämme Springiä asettamaan rajapintaan CountService sopiva toteutus.
Nyt muuttujaan countService asetetaan automaattisesti luokan InMemoryCountService ilmentymä sovelluksen käynnistyessä.
Käytännössä: Koska luokalla InMemoryCountService on annotaatio @Service, ladataan se muistiin web-sovelluksen käynnistyessä. Kun annotoidut luokat ovat ladattu muistiin, käydään läpi niissä olevat @Autowired-annotaatiot, ja asetetaan niihin sopivat ilmentymät. Koska CountController luokassa olevalla muuttujalla CountService on annotaatio @Autowired, siihen asetetaan rajapinnan CountService toteuttava luokka eli InMemoryCountService.
Magic 8 Ball
Sovelluksessa on valmiiksi konfiguroitu Spring-sovelluskehys sekä viikon 1 Magic 8 Ball-tehtävässä rakennettu JSP-sivu.
Tehtävänäsi on toteuttaa valmiiksi annettujen JSP-sivujen pohjalta oma kontrolleriluokka, joka käsittelee pyyyntöjä siten, että sovelluksen lopputoiminnallisuus on sama kuin viikon 1 Magic 8 Ball -tehtävässä. Hyödynnä valmista EightballService-rajapintaa sekä HardcodedEightballService-luokkaa.
Chatting with Anna
Tässä tehtävässä toteutetaan pienimuotoinen Chat valmista Anna-nimistä bottia käyttäen. Tehtäväpohjassa on valmiina kaksi palvelua ja niitä vastaavat rajapinnat pakkauksessa wad.chattingwithanna.service. Tehtävätekstiin on samalla kirjoitettu hieman kertausta ja uutta.
ChatControllerInterface-rajapinnan toteuttaminen
Luo pakkaukseen wad.chattingwithanna.controller luokka ChatController, joka toteuttaa tehtäväpohjassa annetun rajapinnan ChatControllerInterface. Rajapinta määrittelee toteutettavan Controller-luokan metodit ja toimii apuna tehtävän automaattisille testeille. Metodin addMessage tulee vastata POST-pyyntöihin polussa add-message ja uudelleenohjata pyyntö polkuun list. Metodin list tulee vastata GET-pyyntöihin polussa list ja näyttää tehtäväpohjan mukana annettu näkymä list.jsp. Metodien logiikka toteutetaan tehtävän seuraavassa kohdassa.
Metodin käyttämän HTTP-metodin (GET/POST/...) voi määrittää @RequestMapping-annotaation parametrilla method esimerkiksi näin:
Huom! Kun @RequestMapping annotaatiolle annetaan useampi parametri, täytyy ensimmäinenkin (polun määrittävä) parametri asettaa nimellä value.
ChatController-luokan metodien toteuttaminen
Metodissa tarvitaan tehtäväpohjan mukana annettuja palveluita MessageService ja ChatBot. Injektoi nämä riippuvuudet @Autowired-annotaation avulla ChatController-luokan oliomuuttujiksi.
Metodi addMessage saa parametrikseen käyttäjän lähettämän viestin merkkijonona. Spring voi hakea viestin automaattisesti metodille tulleesta HTTP-pyynnöstä parametrille määritettävän @RequestParam-annotaation avulla. Annotaation parametreista value on haettavan parametrin nimi ja required määrittelee hyväksytäänkö pyyntö, jossa parametria ei ole määritelty. Annotaatio määritellään metodin parametrille esimerkiksi näin:
Lisää metodin addMessage parametrille String message@RequestParam-annotaatio HTTP-parametrin nimellä message. HTTP-parametri message ei ole pakollinen, joten pyynnöt ilman sitä täytyy hyväksyä.
Jos parametrina oleva viesti on tyhjä tai null-viite, metodin tulee ohjata pyyntö suoraan listasivulle.
Kun käyttäjän kysymys on ok, tallenna se messageService-palveluun sen tarjoamalla addMessage-metodilla. Jotta keskustelun osapuolet voi erottaa, lisää käyttäjän viestin alkuun merkkijono "You: ". Tämän jälkeen tulee kysyä viestiin vastausta botilta. Vastauksen kysyminen tapahtuu ChatBot-palvelun getAnswerForQuestion-metodilla. Talleta botin antama vastaus MessageService-palvelulla, ja lisää botin viestin alkuun merkkijono botin nimi (botin metodilla getName()) ja kaksoispiste ":".
Huom! Metodi getAnswerForQuestion voi heittää poikkeuksen, jos verkkoyhteys ei toimi, joten käsittele metodin heittämät poikkeukset siten, että käytät poikkeuksen viestiä botin vastauksena. Tällöin voit testata ohjelmaa, vaikka verkkoyhteyttä ei olisi.
Toteuta lopuksi metodi list, jonka tulee lisätä MessageService-palvelusta haettu lista viestejä Model-instanssiin avaimella messages.
Keskustelun tulisi näyttää esimerkiksi tältä (käyttäjän esittämät kysymykset on merkitty punaisella):
You: What is your name?
Anna: You are talking to Anna, the .... USA Online Assistant. My job is to answer ...
You: How old are you?
Anna: I prefer not to discuss my age; let's talk about ....
You: I feel hemlig!
Anna: You're asking about ... restaurants. What's the name of the store?
You: Wut?
Anna: I don't know the answer to that question yet, I am sorry...
..
Ensisilmäyksellä koodi vaikuttaa hyvin paljon monimutkaisemmalta. Pohditaan kuitenkin tämän lähestymistavan hyötyjä.
Rajapintojen käyttäminen ja toteutusten vaihtaminen. Jos sovellus käyttää rajapintoja, voidaan todellinen toteutus piilottaa. Komponentin toteuttajan ei tarvitse millään tavalla tietää rajapinnan toteuttavan luokan todellisesta toteutuksesta.
Sovellusten testaaminen. Sovelluksia testatessa halutaan usein käyttää mock-olioita, joiden avulla voidaan tarkistaa että metodit ja luokat toimivat oikein.
Olioiden parametrien injektointi. Koska olioiden luominen onnistuu lennossa, voidaan olioiden parametrit myös asettaa lennossa. Esimerkiksi tietokantaa käyttävissä sovelluksissa testitapaukset ajetaan eri tietokannalla kuin tuotanto, vaikka lähdekoodi ei käytännössä muutu.
Koostamalla sovellukset avoimia rajapintoja käyttävistä palveluista, yksittäisen palvelun toteuttajan ei tarvitse välittää muiden palveluiden toteutuksessa käytetystä ohjelmointikielestä. Kun käytetty palvelu tarjoaa avoimen kuvauksen saatavilla olevasta datasta ja formaatista, ei palvelun taustalla olevalla ohjelmointikielellä tai -kielillä ole väliä.
Kolmannen osapuolen palvelun hyödyntäminen, case Laskuri
Otetaan esimerkiksi count.io-palvelu. Sen toiminta on yksinkertainen; kuka tahansa voi pitää sen avulla kirjaa erilaisista lukumääristä. Tekemällä GET-muotoinen pyyntö osoitteeseen http://count.io/vb/itse-keksitty-ryhmän-tai-sovelluksen-tunnus/laskettavan-asian-tunnus, sovellus palauttaa tiedon käsitteen lukumäärästä. Esimerkiksi osoitteessa http://count.io/vb/wepa-syksy-2013/kliksu on tieto siitä, kuinka monta kertaa "Hello Spring"-kappaleen laskin-esimerkissä olevaa painiketta on painettu. Tekemällä POST-tyyppinen pyyntö osoitteeseen http://count.io/vb/itse-keksitty-ryhmän-tai-sovelluksen-tunnus/laskettavan-asian-tunnus+ esineen tai käsitteen lukumäärää kasvatetaan yhdellä.
Toteutetaan aiempi laskurisovelluksemme siten, että numeroiden tallentamiseen ja ylläpitoon käytetään count.io-palvelua. Luodaan luokka CountIoCountService, joka toteuttaa aiemmin määrittelemämme rajapinnan CountService. Toteutetaan uusi palvelumme siten, että se hyödyntää count.io-palvelun tarjoamaa rajapintaa http://count.io/vb/wepa-syksy-2013/kliksu. Osoitteeseen tehtäviä kyselyjä voisi tehdä puhtaasti Javan avulla esimerkiksi URL-luokan tarjoamia toiminnallisuuksia hyödyntäen, mutta hyödynnetään tässä Springiä.
Spring tarjoaa luokan RestTemplate, jonka avulla voimme tehdä kyselyjä kolmannen osapuolen palveluihin.
POST-pyyntöjen tekeminen onnistuu esimerkiksi metodilla postForObject, jolle annetaan parametrina osoite, johon pyyntö lähetetään. Tämän lisäksi parametreina annetaan pyynnön mukana lähetettävä data, sekä formaatti, jossa palvelun antama vastaus palautetaan metodista. Alla olevassa esimerkissä luodaan ensin RestTemplate-ilmentymä, jonka jälkeen tehdään POST-pyyntö osoitteeseen "http://count.io/vb/wepa-syksy-2013/kliksu+". Pyynnön mukana ei lähetetä dataa, ja ilmaisemme, että haluamme vastauksen String-muodossa. Emme kuitenkaan tee vastauksella mitään.
RestTemplate template = new RestTemplate();
template.postForObject("http://count.io/vb/wepa-syksy-2013/kliksu+", null, String.class);
GET-pyyntöjen tekeminen onnistuu vastaavasti. Metodille getForObject annetaan parametrina osoite, johon pyyntö tehdään, sekä tyyppi, johon vastaus muunnetaan. Seuraavalla komennolla lähetämme GET-pyynnön osoitteeseen "http://count.io/vb/wepa-syksy-2013/kliksu", ja otamme vastauksen vastaan merkkijonona.
RestTemplate template = new RestTemplate();
String result = template.getForObject("http://count.io/vb/wepa-syksy-2013/kliksu", String.class);
Koska otamme vastauksen vastaan merkkijonona, etsimme erikseen halutun luvun vastauksesta.
package wad;
import java.util.Scanner;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Service
public class CountIoCountService implements CountService {
private RestTemplate restTemplate = new RestTemplate();
public void increment() {
restTemplate.postForObject("http://count.io/vb/wepa-syksy-2013/kliksu+", null, String.class);
}
public int getCount() {
String response = restTemplate.getForObject("http://count.io/vb/wepa-syksy-2013/kliksu", String.class);
response = response.substring(response.indexOf("count"));
return getFirstInteger(response);
}
private int getFirstInteger(String string) {
return new Scanner(string).useDelimiter("\\D+").nextInt();
}
}
Jos sovelluksessamme on useampi saman rajapinnan toteuttava luokka, täytyy @Autowired-annotaatiolle antaa lisätietoa siitä, minkä luokan ilmentymän otamme käyttöön. Annotaatiolle @Qualifier annetaan arvona olion nimi, joka @Qualifier-annotaation parina olevalle @Autowired-annotaatiolle sopii. Muistiin ladattujen olioiden nimet ovat oletuksena niiden luokkien nimet, mutta pienellä alkukirjaimella.
Avoimet palvelut perustuvat ymmärrettävään tiedonsiirtoformaattiin sekä kuvaukseen palvelun rajapinnasta (web-sovellusten tapauksessa tyypillisesti pyyntöosoitteet). Yleisimmät tiedonsiirtoformaatit ovat tällä hetkellä JSON ja XML joista JSONin suosio kasvaa (vieläkin) jatkuvasti. JSON (JavaScript Object Notation) on esitysmuoto, jota käytetään erityisesti selainohjelmistojen ja palvelinohjelmistojen välisessä kommunikaatiossa. JSON-muodon suosio johtuu vahvasti siitä, että Javascript-olioiden luominen JSON-datasta on erittäin yksinkertaista, aivan kuten JSON-kuvauksen luominen Javascript-olioista.
Tarkastellaan tarkemmin osoitteen "http://count.io/vb/wepa-syksy-2013/kliksu" palauttamaa JSON-muotoista vastausta.
Vastauksessa on muuttuja "item", jonka arvo on "kliksu", muuttuja "count", jonka arvo on 9, sekä muuttuja "group", jonka arvo on "wepa-syksy-2013". JSON-dataa voi katsella myös seuraavasti:
Luodaan luokka, johon määritellyt oliomuuttujat vastaavat edellä nähtyä JSON-dataa. Asetetaan luokan nimeksi ItemCount, ja luodaan sille oliomuuttujat item, count ja group, sekä niille sopivat get- ja set-metodit. Luokan runko on kutakuinkin seuraava:
package wad;
public class ItemCount {
private int count;
private String item;
private String group;
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public String getItem() {
return item;
}
public void setItem(String item) {
this.item = item;
}
public String getGroup() {
return group;
}
public void setGroup(String group) {
this.group = group;
}
}
Tutustutaan pikaisesti Jackson JSON-kirjastoon, joka osaa muuttaa JSON-muotoisia merkkijonona olioiksi ja takaisin. Käyttääksemme Jacksonia meidän tulee lisätä seuraava riippuvuus pom.xml-tiedostoon.
Käytännössä Jackson käy läpi luokan attribuutit, ja luo niiden arvojen pohjalta JSON-dataa. Esimerkiksi ItemCount-olion voi tulostaa JSON-muodossa seuraavasti:
// pakkaus
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class ItemCountDemo {
public static void main(String[] args) throws JsonProcessingException {
ObjectMapper mapper = new ObjectMapper();
ItemCount count = new ItemCount();
count.setCount(5);
count.setGroup("wad");
count.setItem("idea");
String result = mapper.writeValueAsString(count);
System.out.println(result);
}
}
Ylläolevan ohjelman tulostus on seuraavanlainen:
{"count":5,"item":"idea","group":"wad"}
Merkkijonon muuntaminen olioksi onnistuu yhtä helposti.
Ylläoleva esimerkki tulostaa seuraavanlaisen merkkijonon:
9 wepa-syksy-2013 kliksu
RestTemplate ja JSON
Spring osaa hyödyntää monia yleisesti käytössä olevista komponenteista. Esimerkiksi aiemmin käytetty RestTemplate sisältää toiminnallisuuden erilaisten datanmuuntajien (HttpMessageConverter) rekisteröimiseksi. Voimme lisätä RestTemplatelle Jackson JSON-tuen käyttämällä Springin luokkaa MappingJackson2HttpMessageConverter -- olettaen tietenkin että olemme lisänneet Jackson JSON-riippuvuuden pom.xml-tiedostoon.
Muokataan aiempaa CountIoCountService-luokkaa siten, että rekisteröimme RestTemplate-luokalle MappingJackson2HttpMessageConverter-luokan. Alla olevassa esimerkissä käytetty annotaatio @PostConstruct tarkoittaa sitä, että metodi suoritetaan kun luokasta on tehty ilmentymä. Käytännössä siis kun CountIoCountService ladataan Springin toimesta käyttöön, sen sisältämään RestTemplateen rekisteröidään samalla tuki JSON-olioiden käsittelyyn.
package wad;
import javax.annotation.PostConstruct;
import org.springframework.http.converter.json.MappingJackson2HttpMessageConverter;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Service
public class CountIoCountService implements CountService {
private RestTemplate restTemplate;
@PostConstruct
private void init() {
restTemplate = new RestTemplate();
restTemplate.getMessageConverters().add(new MappingJackson2HttpMessageConverter());
}
public void increment() {
restTemplate.postForObject("http://count.io/vb/wepa-syksy-2013/kliksu+", null, String.class);
}
public int getCount() {
ItemCount itemCount = restTemplate.getForObject("http://count.io/vb/wepa-syksy-2013/kliksu", ItemCount.class);
return itemCount.getCount();
}
}
Tutkitaan hieman getCount metodissa tapahtuvaa kutsua. RestTemplaten metodikutsu getForObject sai parametrikseen osoitteen, johon pyyntö tehdään, sekä tyypin, johon vastaus pyritään muuntamaan. Koska aiemmin luotu ItemCount on rakennettu vastaamaan count.io-palvelun palauttamaa JSON-dataa, voimme asettaa getForObject-metodin palauttamaan ItemCount-olion, jolloin palvelun vastaus muunnetaan automaattisesti ItemCount-olioksi. Nyt itse count-muuttujan arvon saaminen on paljon helpompaa: voimme kutsua ItemCount-luokan ilmentymän metodia getCount. Koska emme ole kiinnostuneet metodin postForObject-palauttamasta arvosta, voimme pitää palautustyypin vieläkin String-tyyppisenä.
RestTemplate-luokan käyttämille poluille voi myös antaa parametreja. Alla oleva CountIoCountService-luokan ilmentymä toteuttaa täsmälleen saman toiminnan kuin yllä oleva toteutus.
package wad;
import javax.annotation.PostConstruct;
import org.springframework.http.converter.json.MappingJackson2HttpMessageConverter;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Service
public class CountIoCountService implements CountService {
private RestTemplate restTemplate;
@PostConstruct
private void init() {
restTemplate = new RestTemplate();
restTemplate.getMessageConverters().add(new MappingJackson2HttpMessageConverter());
}
public void increment() {
restTemplate.postForObject("http://count.io/vb/{group}/{item}+", null, String.class,
"wepa-syksy-2013", "kliksu");
}
public int getCount() {
ItemCount itemCount = restTemplate.getForObject("http://count.io/vb/{group}/{item}", ItemCount.class,
"wepa-syksy-2013", "kliksu");
return itemCount.getCount();
}
}
Hangman
Neljän pisteen arvoinen avoin tehtävä. Tämä tarkoittaa sitä, että saat suunnitella sovelluksen rakenteen täysin vapaasti. Tehtävälle ei ole (annettuja) testejä. Kun olet toteuttanut tehtävän tehtävänannon mukaisesti ja se toimii, palauta tehtävä TMC:lle -- avoimiin tehtäviin saa tukea ja palautetta ohjaajilta. Pohjassa on valmis Spring-konfiguraatio.
Osoitteessa http://t-avihavai.users.cs.helsinki.fi/hangman-backend toimii JSON-muotoista dataa tarjoava palvelinohjelmisto hirsipuu-pelille. Tässä tehtävässä tarkoituksenasi on toteuttaa sovellus, jonka avulla edellämainittua peliä voi pelata.
Käytettävä palvelin toimii seuraavasti:
GET-tyyppinen kysely osoitteeseen http://t-avihavai.users.cs.helsinki.fi/hangman-backend/app/new luo uuden pelin ja palauttaa pelin JSON-muotoisen esityksen. JSON-muotoinen esitys on seuraavanlainen:
Kenttä "id" kertoo pelin yksilöivän tunnisteen, "used" sisältää listan käytetyistä kirjaimista, "word" on arvattava sana osittain piilotettuna (merkki "_" kuvaa piilotettua sanaa, "state" kertoo pelin tilan (START, GAMING, WIN, LOSE), "wrong" väärin menneiden arvausten määrän, "remaining" jäljellä olevien arvausten määrän, ja "length" sanan pituuden (tässä aina 8).
GET-tyyppinen kysely osoitteeseen http://t-avihavai.users.cs.helsinki.fi/hangman-backend/app/{gameId}/status, missä {gameId} on pelattavan pelin yksilöivä tunniste, kertoo pelin tämänhetkisen tilanteen. Esimerkiksi osoitteessa http://t-avihavai.users.cs.helsinki.fi/hangman-backend/app/d4ea4610/status on peli, jonka pelaaja on voittanut:
POST-tyyppinen kysely osoitteeseen http://t-avihavai.users.cs.helsinki.fi/hangman-backend/app/{gameId}/guess/{character}, missä {gameId} on pelattavan pelin yksilöivä tunniste, ja {character} arvattava kirjain, tekee arvauksen palvelimelle, johon palvelin palauttaa vastauksen edellä mainitussa muodossa.
Huom! Kuten annetussa esimerkissä, on täysin OK olettaa, että käyttäjä pelaa peliä "oikein", eli virheidentarkistusta ei tarvitse tehdä. On myös täysin OK jos käyttäjää ei uudelleenohjata toiselle sivulle mahdollisen POST-pyynnön jälkeen (erityisesti koska emme ole vielä tutustuneet mekanismeihin, joita käytetään käyttäjän tilan muistamiseen).
REST
REST (representational state transfer) on HTTP-protokollaan perustuva arkkitehtuurimalli, joka määrittelee miten HTTP-protokollan pyyntömetodeja ja osoitteita tulee käyttää ohjelmointirajapintojen toteuttamiseen. Taustaidea on periaatteessa yksinkertainen: käsiteltävät resurssit määritellään osoitteiden avulla siten, että jokaisella resurssilla on resurssin yksilöivä tunnus. Pyyntötyypillä kuvataan resurssiin kohdistuva operaatio.
Tutkitaan seuraavaa REST-rajapintaa, joka on toteutettu kirjojen ylläpitämiseen.
GET osoitteeseen /books palauttaa kaikkien kirjojen tiedot tai osajoukon kirjojen tiedoista -- riippuen toteutuksesta.
GET osoitteeseen /books/{id}, missä {id} on yksittäisen kirjan yksilöivä tunniste, palauttaa kyseisen kirjan tiedot.
PUT osoitteeseen /books/{id}, missä {id} on yksittäisen kirjan yksilöivä tunniste, lisää tai muokkaa kyseisen kirjan tietoja. Kirjan tiedot lähetetään pyynnön rungossa.
DELETE osoitteeseen /books/{id} poistaa kirjan tietyllä tunnuksella.
POST osoitteeseen /books luo uuden kirjan pyynnön rungossa lähetettävän datan pohjalta. Palvelun vastuulla on päättää kirjalle tunnus.
REST-rajapinnan käyttämä dataformaatti on toteuttajan päätettävissä. Tyypillisiä formaatteja ovat muun muassa JSON ja XML.
Osoitteissa käytetään substantiivejä -- ei books?id={id} vaan /books/{id}, ja pyynnöt kategorisoidaan pyyntötyyppien mukaan. DELETE-tyyppisellää pyynnöllä poistetaan, POST-tyyppisellä pyynnöllä lisätään, PUT-tyyppisellä pyynnöllä joko lisätään tai päivitetään, ja GET-tyyppisellä pyynnöllä haetaan. Kuten normaalissakin HTTP-kommunikaatiossa, GET-pyyntöjen ei tule muuttaa tallennettua dataa.
REST on hyödyllinen arkkitehtuurimalli mm. olemassaolevien jo hieman ikääntyneiden palveluiden kapselointiin. Sovelluskehittäjä voi kehittää uuden käyttöliittymän, ja käyttää vanhaan sovellukseen liittyvää toiminnallisuutta REST-rajapinnan kautta. REST-arkkitehtuuriin perustuvat palvelut ovat nykyään hyvin yleisiä ja niiden luomiseen on tehty huomattava määrä apuohjelmia. Yksinkertaisen REST-palvelun voi luoda esimerkiksi suoraan olemassaolevasta NetBeansin Web Services -osiossa olevien toimintojen avulla.
"A truly RESTful API looks like hypertext. Every addressable unit of information carries an address, either explicitly (e.g., link and id attributes) or implicitly (e.g., derived from the media type definition and representation structure). Query results are represented by a list of links with summary information, not by arrays of object representations (query is not a substitute for identification of resources)."
REST-palvelun käyttäminen
Oletetaan että aiemmin määrittelemämme REST-rajapinta kirjojen ylläpitämiseen käyttää JSON-formaattia, sisältää tiedon kirjojen nimestä, ja että dataformaatti yksittäiselle kirjalle on seuraavanlainen.
{
"id":2,
"name":"Harry Potter and the Chamber of Secrets"
}
Luodaan kirjaa vastaava Java-luokka.
package wad;
public class Book {
private int id;
private String name;
public int getId() {
return this.id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return this.name;
}
public String setName(String name) {
this.name = name;
}
}
Ulkoisen rajapinnan käyttäminen onnistuu RestTemplate-luokan avulla. Huom! Käytettävälle RestTemplate-ilmentymälle tulee olla rekisteröity käytettävä datanmuuntaja.
GET osoitteeseen /books palauttaa kaikkien kirjojen tiedot tai osajoukon kirjojen tiedoista -- riippuen toteutuksesta.
// kirjojen hakeminen
List<Book> books = restTemplate.getForObject("osoite/books", List.class);
GET osoitteeseen /books/{id}, missä {id} on yksittäisen kirjan yksilöivä tunniste, palauttaa kyseisen kirjan tiedot.
// tunnuksella 5 määritellyn kirjan hakeminen
Book book = restTemplate.getForObject("osoite/books/{id}", Book.class, 5);
PUT osoitteeseen /books/{id}, missä {id} on yksittäisen kirjan yksilöivä tunniste, muokkaa kyseisen kirjan tietoja tai lisää kirjan kyseiselle tunnukselle (toteutuksesta riippuen, lisäystä ei aina toteutettu). Kirjan tiedot lähetetään pyynnön rungossa.
// tunnuksella 5 määritellyn kirjan hakeminen
Book book = restTemplate.getForObject("osoite/books/{id}", Book.class, 5);
book.setName(book.getName() + " - DO NOT BUY!");
// kirjan tietojen muokkaaminen
restTemplate.put("osoite/books/{id}", book, 5);
DELETE osoitteeseen /books/{id} poistaa kirjan tietyllä tunnuksella.
// tunnuksella 32 määritellyn kirjan poistaminen
restTemplate.delete("osoite/books/{id}", 32);
POST osoitteeseen /books luo uuden kirjan pyynnön rungossa lähetettävän datan pohjalta. Palvelun vastuulla on päättää kirjalle tunnus.
Book book = new Book();
book.setName("Harry Potter and the Goblet of Fire");
// uuden kirjan lisääminen
book = restTemplate.postForObject("osoite/books", book, Book.class);
// nyt book-oliossa myös backendin palauttama tunnus
Common Items
Osoitteessa http://t-avihavai.users.cs.helsinki.fi/take-a-rest/app/items pyörii (kerettiläinen) REST-api esineiden tallentamiseen. Jokaisella esineellä on nimi ("name") ja kuvaus ("description"), sekä numeerinen tunnus ("id"). API on kutakuinkin seuraavanlainen:
GET osoitteeseen .../app/items palauttaa kaikki esineeet.
GET osoitteeseen .../app/items/{id}, missä {id} on yksittäisen esineen yksilöivä tunniste, palauttaa kyseisen esineen tiedot.
PUT osoitteeseen .../app/items/{id}, missä {id} on yksittäisen esineen yksilöivä tunniste, muokkaa kyseisen esineen tietoja. Esineen tiedot lähetetään pyynnön rungossa.
DELETE osoitteeseen .../items/{id} poistaa esineen tietyllä tunnuksella.
POST osoitteeseen .../app/items luo uuden esineen pyynnön rungossa lähetettävän datan pohjalta. Palvelu päättää esineelle tunnuksen.
(deja-vu)
API käyttää JSON-formaattia datan siirrossa.
RestItemService
Toteuta pakkaukseen wad.commonitems.service rajapinnan ItemService toteuttava luokka RestItemService. Luokan RestItemService tulee käyttää yllä kuvattua rajapintaa RestTemplate-luokan avulla. Huomaa, että kaikkia toiminnallisuuksia ei tarvitse toteuttaa.
ItemController-luokan täydentäminen
Muokkaa ItemController-luokkaa siten, että se hyödyntää edellisessä osassa toteuttamaasi RestItemService-luokkaa (luonnollisesti ItemService-rajapinnan kautta). Metodin addItem tulee luoda uusi Item-olio parametrina olevista arvoista ja lisätä se ItemService-toteutuksen avulla keskitettyyn tavaratietokantaan. Metodin deleteItem tulee taas poistaa keskitetystä tavaratietokannasta haluttu esine.
Täydennä luokan metodit siten, että molemmat POST-tyyppisiä pyyntöjä kuuntelevat metodit ohjaavat pyynnöt lopuksi listItems-metodille. Metodin listItems tulee asettaa ItemService-toteutukselta saatavat esineet model-parametrin attribuutiksi nimeltä "items" ja näyttää käyttäjälle /WEB-INF/jsp/list.jsp -sivun avulla renderöity listasivu.
le end of viikko 2
Mikä on Front Controller ja mitä se tekee?
Mitä tapahtuu kun palvelin tekee uudelleenohjauksen (redirect)? Tuleeko selaimen tällöin tehdä jotain? Mitä?
Miksi POST-pyynnön jälkeen on hyvä ohjata selain tekemään GET-pyyntö? Miten selaimen voi ohjata tekemään uuden pyynnön?
Mitä on JSON ja mihin sitä käytetään?
Mikä on REST? Minkälaisen REST-rajapinnan suunnittelisit opiskelijoiden tietojen tallentamiseen?
Mitä annotaatio @Controller tekee? Miksi ja milloin sitä käytetään?
Mitä annotaatio @RequestMapping tekee? Miksi ja milloin sitä käytetään?
Mitä eroa on pyynnön parametreilla ja pyyntöön asetettavilla attribuuteilla? Missä tapauksissa näitä käytetään?
Miksi Springin Model-olioon lisätyt attribuutit eivät ole käytössä uudelleenohjauksen jälkeen?
le start of viikko 3
Omat palvelut
Suurimmat syyt ohjelmistojen pilkkomisessa erillisiksi palveluiksi on uudelleenkäytön helpottaminen sekä toteutusten kapselointi -- oikeastaan täysin samat asiat, mitkä ovat ajaneet olio-ohjelmoinnin kehitystä. Olemassaolevat palvelut, joiden toteutus on piilotettu hyvin määritellyn rajapinnan taakse, helpottavat uusien sovellusten kehitystä sillä sovelluskehittäjän ei tarvitse keskittyä jo olemassaolevan palvelun toteutuksen yksityiskohtiin. Tämä helpottaa myös ohjelmiston jatkokehitystä sekä ylläpidettävyyttä. Vastaavasti, yksittäisen palvelun ylläpidossa ja kehittämisessä tarvitsee keskittyä vain kyseiseen palveluun.
JSON-dataa tuottava palvelu kirjojen käsittelyyn
Toteutetaan JSON-muotoista dataa käyttävä palvelu kirjojen tallentamiseen ja lataamiseen. Jotta saamme Springin kontrollerit vastaanottamaan ja lähettämään JSON-muotoista dataa, lisäämme spring-konfiguraatioon rivin <mvc:annotation-driven />.
<mvc:annotation-driven />
Rivin lisääminen lisää muun muassa toiminnallisuuden viestien muutamiseen muodosta toiseen. Jotta saamme rivin lisättyä, tulee konfiguraatiotiedostoon asettaa myös mvc-nimiavaruuden otsaketiedot. Kokonaisuudessaan konfiguraatiotiedosto on (esimerkiksi) seuraavankaltainen.
Jos projektin Maven-tiedostoon on lisätty jackson-databind-riippuvuus, jota käytettiin JSON-muotoisen datan lähettämiseen ja vastaanottamiseen RestTemplate-luokan avulla, osaa Spring nyt lähettää ja vastaanottaa JSON-muotoista dataa myös @Controller-annotaatiolla merkityissä luokissa.
Pyynnössä olevan JSON-muotoisen datan muuttaminen olioksi tapahtuu annotaation @RequestBody avulla. Annotaatio @RequestBody edeltää kontrollerimetodin parametrina olevaa luokkaa, ja sen olemassaolo pyytää Spring-sovelluskehystä muuntamaan pyynnössä olevan datan olioksi.
@RequestMapping(value="books", method=RequestMethod.POST)
public String postBook(@RequestBody Book book) {
bookStorage.create(book);
return "done";
}
Vastauksen saa lähetettyä käyttäjälle JSON-muodossa (tai muussa muodossa, riippuen käytössä olevista riippuvuuksista) lisäämällä pyyntöä käsittelevään metodiin annotaation @ResponseBody. Annotaatio @ResponseBody pyytää Spring-sovelluskehykstä asettamaan palvelimen tuottaman datan selaimelle lähetettävän vastauksen runkoon. Jos vastaus on olio, muutetaan se automaattisesti esimerkiksi JSON-olioksi kun <mvc:annotation-driven /> on lisätty spring-konfiguraatioon ja projektin riippuvuuksiin on lisätty jackson-databind-riippuvuus.
@RequestMapping(value="books", method=RequestMethod.GET)
@ResponseBody
public Book getBook() {
Book book = new Book();
book.setName("Spring API");
return book;
}
Edellä mainitut annotaation voi myös yhdistää. Oletetaan, että käytössä on lisäksi bookService-niminen olio, jonka metodi create lisää kirjalle yksilöivän tunnuksen ja varastoi sen myöhempää käyttöä varten. Metodi myös palauttaa viitteen uuteen kirja-olioon. Uuden kirjan lisääminen tapahtuisi tällöin seuraavasti.
@RequestMapping(value="books", method=RequestMethod.POST)
@ResponseBody
public Book postBook(@RequestBody Book book) {
return bookStorage.create(book);
}
Voimme lisätä annotaatioon @RequestMapping lisätietoa metodin tuottamasta datasta. Attribuutti consumes kertoo minkälaista dataa metodin kuuntelema osoite hyväksyy. Metodi voidaan rajoittaa vastaanottamaan JSON-muotoista dataa merkkijonolla "application/json".
@RequestMapping(value="books", method=RequestMethod.POST, consumes="application/json")
@ResponseBody
public Book postBook(@RequestBody Book book) {
return bookStorage.create(book);
}
Vastaavasti metodille voidaan lisätä tietoa datasta, jota se tuottaa. Attribuutti produces kertoo tuotettavan datatyypin. Alla määritelty metodi sekä vastaanottaa että tuottaa JSON-muotoista dataa.
@RequestMapping(value="books", method=RequestMethod.POST,
consumes="application/json", produces="application/json")
@ResponseBody
public Book postBook(@RequestBody Book book) {
return bookStorage.create(book);
}
Toteutetaan seuraavaksi kaikki tarvitut metodit kirjojen tallentamiseen. Kontrolleri hyödyntää erillistä luokkaa, joka tallentaa kirjaolioita muistiin, sekä tarjoaa tuen aiemmin määrittelemiemme books-osoitteiden ja pyyntöjen käsittelyyn.
GET osoitteeseen /books palauttaa kaikkien kirjojen tiedot. Listan muutaminen JSON-muotoiseksi vastaukseksi onnistuu samoin kuin yksittäisen olion muuntaminen JSON-muotoiseksi vastaukseksi. Kun käyttäjä tekee GET-tyyppisen pyynnön osoitteeseen "/books", alla määritelty kontrolleri hakee bookService-oliolta listan kirjoja, ja palauttaa ne JSON-muodossa.
@RequestMapping(value="books", method=RequestMethod.GET)
@ResponseBody
public List<Book> getBooks() {
return bookService.list();
}
GET osoitteeseen /books/{id}, missä {id} on yksittäisen kirjan yksilöivä tunniste, palauttaa kyseisen kirjan tiedot. Spring-kontrollerille voi lisätä RestTemplate-luokan käytöstä tutun polkuparametrin. Määrittelemällä osoite "/books/{id}" annotaatiolla @RequestMapping merkityn metodin käsittelemäksi poluksi, voimme lisätä metodiin annotaatiolla @PathVariable merkityn muuttujan, johon polun {id}-kohdassa oleva arvo asetetaan.
@RequestMapping(value="books/{id}", method=RequestMethod.GET)
@ResponseBody
public Book getBook(@PathVariable Integer id) {
return bookService.read(id);
}
PUT osoitteeseen /books/{id}, missä {id} on yksittäisen kirjan yksilöivä tunniste, muokkaa kyseisen kirjan tietoja. Kirjan tiedot lähetetään pyynnön rungossa JSON-muotoisena. Saamme muutettua JSON-muotoisen kirjaesityksen kirjaolioksi annotaatiolla @RequestBody, ja annotaatiolla @PathVariable saadaan polusta muunnettavan kirjan tunnus. Lisätään metodiin vielä muunnetun kirjan palauttaminen.
@RequestMapping(value="books/{id}", method=RequestMethod.PUT)
@ResponseBody
public Book updateBook(@PathVariable Integer id, @RequestBody Book book) {
return bookService.update(id, book);
}
DELETE osoitteeseen /books/{id} poistaa kirjan tietyllä tunnuksella. Palautetaan myös poistettu kirja.
@RequestMapping(value="books/{id}", method=RequestMethod.DELETE)
@ResponseBody
public Book deleteBook(@PathVariable Integer id) {
return bookService.delete(id);
}
POST osoitteeseen /books luo uuden kirjan pyynnön rungossa lähetettävän datan pohjalta. Palvelun vastuulla on päättää kirjalle tunnus.
@RequestMapping(value="books", method=RequestMethod.POST)
@ResponseBody
public Book postBook(@RequestBody Book book) {
return bookService.create(book);
}
Palvelinohjelmistot, jotka tarjoavat vain avoimen rajapinnan kolmannen osapuolen ohjelmistoille, eivät tyypillisesti sisällä erillistä käyttöliittymää. Tällöin niiden testaaminen tapahtuu tyypillisesti sekä automaattisilla testeillä, että erilaisilla selainohjelmistoilla. Yksi hyvin hyödyllinen apuväline on Postman, jonka saa lisättyä Google Chromeen Googlen web-storesta.
Postmanin hyödyntäminen on erittäin suositeltavaa (katso esittelyvideo).
ItemStorage
Tässä tehtävässä toteutetaan edellisen viikon viimeisessä tehtävässä (Common Items) tietojen tallentamiseen käytetty komponentti.
InMemoryItemStorage
Toteuta pakkaukseen wad.itemstorage rajapinnan ItemStorage toteuttava luokka InMemoryItemStorage. Luokan InMemoryItemStorage tulee hallinnoida Item-tyyppisiä olioita tarjotun ohjelmointirajapinnan kautta, ja sen vastuulla on yksilöivän tunnuksen asettaminen uusille Item-luokan ilmentymille (create-metodissa). Voit käyttää olioiden tallentamiseen esimerkiksi Map-tietorakennetta, missä avaimena on tunnus (Integer) ja arvona on Item-olio. Aseta myös InMemoryItemStorage-luokalle @Service-annotaatio, jotta siihen pääsee käsiksi myöhemmin.
Metodin update tulee päivittää olemassaolevan Item-ilmentymän nimeä ja kuvausta. Jos päivitettävää oliota ei löydy, metodin tulee palauttaa arvo null, muuten palautetaan päivitetty olio. Metodin delete tulee poistaa olio, jonka tunnus annetaan metodille parametrina. Palauta poistettu olio metodin paluuarvona.
ItemStorageController
Lisää konfiguraatiotiedostoon spring-base.xml seuraava rivi.
<mvc:annotation-driven />
Konfiguraatiotiedostossa on valmiina XML-otsaketiedot. Rivi muun muassa lisää pyyntöjen käsittelijään toiminnallisuudet JSON-muotoisten pyyntöjen vastaanottamiseen ja lähettämiseen.
Toteuta tämän jälkeen pakkaukseen wad.itemstorage luokka ItemStorageController, jolla on annotaatio @Controller. Toteuta luokkaan metodit, jotka käsittelevät pyynnöt seuraaviin osoitteisiin:
GET osoitteeseen items palauttaa kaikki esineeet JSON-muotoisena listana.
GET osoitteeseen items/{id}, missä {id} on yksittäisen esineen yksilöivä tunniste, palauttaa yksittäisen esineen JSON-muotoisen esityksen.
PUT osoitteeseen items/{id}, missä {id} on yksittäisen esineen yksilöivä tunniste, ja pyynnön rungossa tulee esineen tiedot, päivittää kyseisen esineen tiedot.
DELETE osoitteeseen items/{id} poistaa esineen annetulla tunnuksella sekä palauttaa poistettavan esineen JSON-muotoisena.
POST osoitteeseen items luo uuden esineen pyynnön rungossa lähetettävän datan pohjalta ja palauttaa uuden esineen JSON-muotoisena. Palvelu päättää esineelle tunnuksen.
Hyödynnä edellisessä tehtävässä toteuttamaasi luokkaa InMemoryItemStorage luonnollisesti siten, luokka ItemStorageController tuntee vain rajapinnan ItemStorage.
REST-sovelluksissa osoitteet ovat substantiiveja, sillä niillä esitetään käsitteitä. Osa sovelluskehittäjistä toivovat, että käyttäisimme substantiivin yksikkömuotoa yksittäistä käsitettä haettaessa; sen sijaan että käyttäisimme osoitetta /books/{id} yhden kirjan näyttämiseen, käyttöön valittaisiin osoite /book/{id}. Käytännössä tämä debaatti on kuitenkin merkityksetön ja pitäydymme tällä kurssilla monikkojen käytössä: oleellista "oikeassa" REST-arkkitehtuurissa on datan linkittäminen käytössä oleviin resursseihin siten, että palvelimen tarjoama data sisältää linkit, joita tarvitaan olemassaolevien resurssien navigointiin (olemme vieläkin kerettiläisiä tässä suhteessa..).
Palveluiden yhdistäminen
Mietitään seuraavaksi tilannetta, missä resursseihin liittyy muita resursseja. Käytämme aiemmin tutuksi tullutta kirjaesimerkkiä, sekä lisäämme seuraavan APIn kirjoittajien hallintaan.
GET osoitteeseen /authors palauttaa kaikkien kirjoittajien tiedot.
GET osoitteeseen /authors/{id}, missä {id} on yksittäisen kirjoittajan yksilöivä tunniste, palauttaa kyseisen kirjoittajan tiedot.
PUT osoitteeseen /authors/{id}, missä {id} on yksittäisen kirjoittajan yksilöivä tunniste, muokkaa kyseisen kirjoittajan tietoja (muokattavat tiedot lähetetään pyynnön rungossa).
DELETE osoitteeseen /authors/{id} poistaa kirjoittajan tietyllä tunnuksella.
POST osoitteeseen /authors luo uuden kirjoittajan (kirjoittajan tiedot pyynnön rungossa).
Pohditaan esimerkkiä, jossa tavoitteena on luoda sovellus, missä kirjoittajille lisätään heidän kirjoittamia kirjoja.
Yksi vaihtoehto on muokata kirjoittajat sisältävää palvelua siten, että yksittäisen kirjoittajan tietoja haettaessa palvelu palauttaa myös listan kaikista kirjoittajan kirjoittamista kirjoista. Tämä ei kuitenkaan ole kovin mielekästä, tai edes järkevää. Kirjoittajista vastaavan palvelun tulee hoitaa vain kirjoittajiin liittyviä asioita (tai henkilöihin!), ei kirjojen listaamista.
Parempi vaihtoehto on määritellä kirjoittajille oma kyselyosoite, joka aggregoi eli yhdistää kirjoittajien ja kirjojen tiedot. Määritellään uusi REST-tyyppinen rajapinta kirjoittajiin liittyvien kirjojen käsittelyyn.
GET osoitteeseen /authors/{authorId}/books palauttaa kaikki tiettyyn kirjoittajaan liittyvät kirjat (yksittäisen kirjoittajan tiedot saa yhä haettua kirjoittajia hallinnoivalta palvelulta).
DELETE osoitteeseen /authors/{authorId}/books/{bookId} poistaa kirjoittajalta {authorId} kirjan, jonka tunnus on {bookId}.
POST osoitteeseen /authors/{authorId}/books/{bookId} lisää kirjoittajalle {authorId} kirjan, jonka tunnus on {bookId}.
Toisaalta, yksittäisen kirjan tietoja voisi hyvin muokata siten, että se sisältäisi tiedon myös kirjoittajasta: niitä ei yleensä ole kovin montaa. Olisi myös mahdollista toteuttaa erillinen rajapinta kirjojen kirjoittajien käsittelyyn.
GET osoitteeseen /books/{bookId}/authors palauttaa kaikki kirjaan liittyvät kirjoittajat.
DELETE osoitteeseen /books/{bookId}/authors/{authorId} poistaa kirjalta {bookId} kirjoittajan, jonka tunnus on {authorId}.
POST osoitteeseen /books/{bookId}/authors/{authorId} lisää kirjalle {bookId} kirjoittajan, jonka tunnus on {authorId}.
Käytännössä palveluita yhdistelevien osoitteiden määrittelyyn ei ole sovittu yhtä oikeaa lähestymistapaa, vaan sovelluskehittäjä usein suunnittelee mahdollisimman kuvaavat osoitteet itse.
Yllä olevissa aggregaattipalveluissa on tarkoituksella jätetty pois kirjoittajien ja kirjojen muokkaaminen. Ongelman muodostaa usein se, että esimerkiksi kirjoittajiin liittyvien kirjojen listaaja ei pakosti esitä kirjoittajista samoja tietoja kuin kirjoittajia listaava palvelu. Oikeastaan kirjoittajien ja kirjojen muokkaaminen ei edes kuulu yllä määritellyt rajapinnat toteuttavan palvelun vastuulle.
Suunnitellaan palvelut siten, että ne toteuttavat oman vastuualueensa hyvin, ja jättävät muut tehtävät muille.
Voisiko edellä kuvatut aggregaattipalvelut toteuttaa esimerkiksi erillisellä palvelulla authorships. Miten?
High Five!
Tässä tehtävässä toteutetaan pelitulospalvelu, joka tarjoaa REST-rajapinnan pelien ja tuloksien käsittelyyn. Huom! Rajapinnan kaikki syötteet ja vasteet ovat JSON-muotoisia olioita. Tehtäväpohjassa on toteutettu valmiiksi luokat Game ja Score, sekä tarvittavat palvelut niiden käsittelyyn ja tallettamiseen.
Huom! Tässä tehtävässä hyödynnät valmiita Service-luokkia, ja toteutat niille kontrollerit. Tehtävän testit testaavat sovelluksen ulkoista toimintaa: jotta testit toimisivat, tulee testipalvelimen käynnistyksen onnistua (portti 8090 avoin, sovelluksen lähdekoodissa ei virheitä).
GameController
Pelejä käsitellään luokan Game avulla.
Toteuta pakkaukseen wad.highfive.controller luokka GameController, joka tarjoaa REST-rajapinnan pelien käsittelyyn:
POST /app/games luo uuden pelin sille annetun pelin tiedoilla ja palauttaa luodun pelin tiedot. (Huom. vieläkin! Pyynnön rungossa oleva data on aina JSON-muotoista. Vastaukset tulee myös palauttaa JSON-muotoisina.)
GET /app/games listaa kaikki talletetut pelit.
GET /app/games/{name} palauttaa yksittäisen pelin tiedot pelin nimen perusteella.
DELETE /app/games/{name} poistaa nimen mukaisen pelin. Palauttaa poistetun pelin tiedot.
Vinkki! Muistele minkälaiset pyynnöt ohjautuvat Springille. Mitä tämä tarkoittaa toteuttamasi kontrollerin näkökulmasta?
ScoreController
Jokaiselle pelille voidaan tallettaa pelikohtaisia tuloksia (luokka Score). Jokainen pistetulos kuuluu tietylle pelille, ja tulokseen liittyy aina pistetulos points numerona, pelaajan nimimerkki nickname ja tuloksen lisäyshetkestä kertova aikaleimatimestamp (lisää tälle siis arvo itse!).
Toteuta luokka wad.highfive.controller.ScoreController, joka tarjoaa REST-rajapinnan tuloksien käsittelyyn:
POST /app/games/{name}/scores luo uuden tuloksen pelille name ja asettaa tulokseen pelin tiedot. Tuloksen tiedot lähetetään kyselyn rungossa. Huom! Lisää tulokseen myös aikaleima täällä!
GET /app/games/{name}/scores listaa pelin name tulokset.
GET /app/games/{name}/scores/{id} palauttaa tunnuksella id löytyvän tuloksen name-nimiselle pelille.
DELETE /app/games/{name}/scores/{id} poistaa avaimen id mukaisen tuloksen peliltä name (pelin tietoja ei tule pyynnön rungossa). Palauttaa poistetun tuloksen tiedot.
HATEOAS
Tutustu blogikirjoitukseen, jossa käsitellään HATEOAS-termiä. Mitä tällä kurssilla tarkoitetaan kun puhutaan siitä, että olemme kerettiläisiä REST-palveluiden määrittelyssä?
Avoimen rajapinnan tarjoavat palvelut
Toteutettujen palveluiden ei missään nimessä tarvitse aina seurata REST-arkkitehtuuria. Oikeastaan, kuten HATEOAS-artikkelistakin tulee ilmi, moni itseään REST-palveluksi tituleeraava palvelu ei seuraa alkuperäistä REST-arkkitehtuuria.
Hang'Em
Tässä tehtävässä toteutetaan osa viime viikon Hirsipuu-pelin palvelinkomponentin toiminnallisuudesta, sekä otetaan muutamia askelia sen "paranteluun".
HangmanController
Toteuta pakkaukseen wad.hangman luokka HangmanController, ja lisää sille annotaatio @Controller.
Hyödynnä InMemoryHangmanService-luokan tarjoamia toiminnallisuuksia, luonnollisesti siten, että luokka HangmanController tuntee vain rajapinnan HangmanGameService. Toteuta sovellukseen seuraavien osoitteiden käsittely:
GET /app/new luo uuden pelin ja palauttaa pelin JSON-muotoisen esityksen. JSON-muotoinen esitys on esimerkiksi seuraavanlainen:
GET /app/{gameId}/status, missä {gameId} on pelattavan pelin yksilöivä tunniste, kertoo pelin tämänhetkisen tilanteen. JSON-muotoinen esitys on esimerkiksi seuraavanlainen:
POST /app/{gameId}/guess/{character}, missä {gameId} on pelattavan pelin yksilöivä tunniste, ja {character} arvattava kirjain käsittelee peliin liittyvän arvauksen palvelimella. Palvelin palauttaa vastauksena pelin statuksen arvauksen jälkeen.
HangEm
Parannellaan hieman pelin toiminnallisuutta: luodaan pelistä versio, joka välttelee pelaajan arvauksia. Huom! Voit palauttaa tehtävän myös ilman tämän osion toteuttamista (muiden tehtävien tekeminen ennen tätä osiota voi olla hyvä idea!).
Lisää rajapintaan WordService metodi List<String> getWordOptions(List<String> existingGuesses, String newGuess);.
Toteuta luokkaan InMemoryWordService vaadittava metodi List<String> getWordOptions(List<String> existingGuesses, String newGuess); siten, että metodi luo listan mahdollisista käytettävistä sanoista seuraavasti:
Metodi luo ensin sanalistan, joka on kopio listan words sanoista
Metodi ottaa listan existingGuesses kirjaimista ensimmäisen, ja tutkii sanalistan sanat yksitellen. Jos kirjain löytyy sanasta, sana poistetaan sanalistasta.
Tätä jatketaan seuraavilla kirjaimilla kunnes:
kaikki kirjaimet on käyty läpi, ja sanalistalla on vielä sanoja.
tai sanalistan sanat loppuvat kesken jonkun kirjaimen kohdalla. Tällöin käytetään sanalistaa, johon on jätetty kaikki sanat, jotka olivat sanalistassa kyseisen kirjaimen tarkastelun alussa.
Tämän jälkeen, sanalistasta poistetaan vielä sanat, joista löytyy kirjain newGuess. Jos sanalista olisi tämän jälkeen tyhjä, käytetään edellisestä vaiheesta saatua sanalistaa, muuten kirjaimen newGuess poiston jälkeistä listaa.
Muokkaa tämän jälkeen luokan InMemoryHangmanGameService metodia guess siten, että status-oliolle arvotaan aina uusi sana WordService-rajapinnan metodin getWordOptions palauttamasta sanalistasta.
Testaa toteutustasi ja palauta se TMC:lle. Huom! Logiikkaa voi parantaa vielä reilusti nykyisestä, testit odottavat kuitenkin ylläkuvattua "brute-force"-lähestymistapaa. Jos lähdet vielä parantamaan toteutusta, muista ensin palauttaa tehtävä TMC:lle siten, että saat siitä pisteet.
Tiedon tallentaminen tietokantaan
Tietokannat ovat sovelluksia ohjelmiston käyttämän tiedon tallentamiseen. Tähänastiset sovelluksemme ovat hukanneet käyttämänsä tiedot sovelluksen sammuessa. Tämä johtuu siitä että tietoa ei ole varastoitu mihinkään, vaan se on ollut vain sovelluksen muistissa. Käytännössä tiedon säilymisen varmistamiseksi tieto tulee tallentaa pysyväismuistiin, esimerkiksi kovalevylle.
Tietokantoja käytetään tiedon tallentamiseen. Termiä tietokanta käytetään puhekielessä usein termin tietokannanhallintajärjestelmä korvaajana. Tässä materiaalissa termillä tietokanta tarkoitetaan yleensä tietokannanhallintajärjestelmää. Tietokannanhallintajärjestelmät (DBMS, Database Management System) ovat sovelluksia, jotka tarjoavat tukitoiminnallisuuksia tietokannan ydintoiminnallisuuden toteuttavan tietokantamoottorin päälle. Tietokantamoottori tarjoaa toiminnallisuuden tiedon luomiseen, lukemiseen, päivittämiseen ja poistamiseen (create, read, update and delete, CRUD), sekä erilaisiin listauksiin.
Huomattava osa tietokannoista toteuttaa ACID-ehdot, joiden avulla lisätään järjestelmän luotettavuutta. Käytännössä ACID-ehtoja seuraamalla tietokantaan tallennettavat tiedot ovat yleensä palautettavissa myös virhetilanteiden sattuessa. ACID koostuu seuraavista osista:
Atomisuus (atomicity): tietokantaan tehtävä kyselysarja suoritetaan kokonaan, tai sitä ei suoriteta lainkaan. Tähän liittyy käsite transaktio. Transaktioiden avulla voidaan suorittaa joukko tietokantaoperaatioita siten, että jos yksikin operaatio epäonnistuu, yhtäkään transaktion sisältämistä operaatioista ei suoriteta, vaan palataan transaktiota edeltävään tilaan. Esimerkiksi jos tilisiirtotransaktiossa, jossa on kaksi operaatiota, nosto ja pano, toinen operaatio epäonnistuu, nostetut rahat katoavat.
Johdonmukaisuus (consistency): tietokannan tulee olla jokaisen transaktion jälkeen eheässä ja johdonmukaisessa tilassa. Tietokantaan tehtävien muutosten tulee näkyä muille tietokantaa käyttäville ohjelmille aina samalla tavalla (johdonmukaisesti).
Eristyneisyys (isolation): Tietokantaan tehtävät transaktiot eivät saa vaikuttaa toisiinsa, ja kesken oleva transaktio ei saa näkyä muille transaktioille.
Pysyvyys (durability): Kun transaktio on suoritettu loppuun, tehdyt muutokset eivät saa kadota järjestelmästä.
Tietokannat ovat yleensä palvelinohjelmistoista erillisiä ohjelmistoja, joihin palvelinsovellus ottaa yhteyden tietokantakyselyjä tehtäessä. Käytännössä tietokanta voi olla myös täysin erillisellä koneella: se kuuntelee jotain ennaltamääriteltyä porttia, johon palvelinohjelmisto ottaa yhteyden (kuten ensimmäisen viikon Knock-knock -sovellus).
Tietokannan sisältöä kuvattaessa yksittäiseen käsitteeseen liittyvää tietoa kuvataan usein taulukkomuotoisena, missä sarakkeet kuvaavat tallennettavan tiedon attribuutteja, ja rivit tallennettua tietoa. Esimerkiksi alla oleva "taulu" sisältää tietoa kolmesta Henkilöstä:
Henkilo
id nimi huone
1 Arto B215
2 Matti D232
3 Mikael B215
Käsittelemme ensin relaatiotietokantojen käyttöä osana web-palvelinohjelmistoja, jonka jälkeen tutustumme pikaisesti NoSQL-tietokantoihin. Relaatiotietokantoihin liittyvissä esimerkeissä ja tehtävissä käytämme tällä viikolla Javalla kirjoitettua H2-tietokantaa, jonka saa käyttöön lisäämällä seuraavan riippuvuuden pom.xml-tiedostoon.
Oikeastaan tämän viikon tapamme käyttää H2-tietokantaa lataa uuden tietokannan muistiin aina palvelinohjelmistoa uudelleenkäynnistettäessä, eli emme käytännössä tallenna vieläkään mitään levylle. Otamme kuitenkin askeleita tietokantojen hyödyntämiseen palvelinohjelmistoissa.
Huom! Glassfish ja transaktiotuki
Glassfish-palvelin vaatii että käyttäisimme sen omaa mekanismia transaktioiden hallintaan. Emme kuitenkaan halua sitoutua yksittäiseen palvelinalustaan, joten tästä eteenpäin käytämme TomEE-palvelinta, missä Tomcat-palvelimeen on lisätty JavaEE-tuki.
Voit myös käyttää useimpiin harjoitustehtäväpohjiin lisättyä Jetty-palvelinta. Sen voit käynnistää projektikansiossa ollessasi komentoriviltä komennolla mvn jetty:run
JDBC...
JDBC (Java Database Connectivity) on Javalle on määritelty standarditapa tietokantayhteyden luomiseen sekä tietoa muokkaavien ja hakevien kyselyjen suorittamiseen. Tausta-ajatuksena JDBCn kehitykselle on ollut yhteisen rajapinnan määrittely relaatiotietokantojen käyttöön -- käytettävään tietokantaan tulee voida ottaa yhteys, ja jokaiseen tietokantaan tulee pystyä tekemään kyselyitä. Kehitykseen on vaikuttanut ODBC, joka on vastaava projekti C-kielelle. JDBC tarjoaa suoran kytköksen valmiisiin ODBC-toteutuksiin.
Jotta JDBCn avulla voidaan ottaa yhteys tietokantaan, tulee käytössä olla tietokantakohtainen JDBC-ajuri, jonka tietokannan toteuttaja yleensä tarjoaa. JDBC-ajurin vastuulla on tietokantayhteyden luomiseen liittyvät yksityiskohdat sekä kyselytulosten muuntaminen JDBC-standardin mukaiseen muotoon.
Oletetaan että käytössämme on seuraavanlainen tietokantataulu:
Henkilo
id nimi huone
1 Arto B215
2 Matti D232
3 Mikael B215
JDBCn avulla kyselyn tekeminen tietokantatauluun tapahtuu seuraavasti:
package wad.db;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class Main {
public static void main(String[] args) throws Exception {
Class.forName("org.h2.Driver");
String jdbcUrl = "<jdbc-osoite tietokantaan>";
String username = "SA";
String password = "";
Connection connection = DriverManager.getConnection(jdbcUrl, username, password);
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT * FROM Henkilo");
while(resultSet.next()) {
int id = resultSet.getInt("id");
String nimi = resultSet.getString("nimi");
String huone = resultSet.getString("huone");
System.out.println(id + "\t" + nimi + "\t" + huone);
}
connection.close();
}
}
1 Arto B215
2 Matti D232
3 Mikael B215
Tutkitaan koodia hieman tarkemmin. Alussa rekisteröidään tietokantakohtainen JDBC-ajuri käyttöön (kutsun Class.forName tarvitsee vain ennen Javan versiota 6). Tämän jälkeen määritellään yhteys tietokantaan. Alla ei ole määritelty tietokantaosoitetta, mutta se voisi olla esimerkiksi "jdbc:h2:~/test", jos halutaan käyttää tiedostossa test sijaitsevaa tietokantaa. Jos palvelin on käynnissä portissa 9101, ja tietokannan nimi on test, osoite on "jdbc:h2:tcp://localhost:9101/~/test". H2-tietokannan saa käynnistettyä muistissa käyttämällä osoitetta "jdbc:h2:mem:tietokannannimi". Lisää vaihtoehtoja löytyy H2-tietokannan dokumentaatiosta.
Konkreettinen yhteys luodaan JDBCn DriverManager-luokan avulla.
Kyselyn tekeminen tapahtuu pyytämällä yhteydeltä Statement-oliota, jota käytetään kyselyn tekemiseen ja tulosten pyytämiseen. Metodi executeQuery suorittaa parametrina annettavan SQL-kyselyn, ja palauttaa tulokset sisältävän ResultSet-olion.
Tämän jälkeen ResultSet-oliossa olevat tulokset käydään läpi. Metodia next() kutsumalla siirrytään kyselyn palauttamissa tulosriveissä eteenpäin. Kultakin riviltä voi kysyä sarakeotsikon perusteella solun arvoa. Esimerkiksi kutsu getString("nimi") palauttaa kyseisellä rivillä olevan sarakkeen "nimi" arvon String-tyyppisenä.
while(resultSet.next()) {
int id = resultSet.getInt("id");
String nimi = resultSet.getString("nimi");
String huone = resultSet.getString("huone");
System.out.println(id + "\t" + nimi + "\t" + huone);
}
Lopulta tietokantayhteys suljetaan. Tämä vapauttaa tietokantakyselyyn liittyvät resurssit.
connection.close();
JDBC tarjoaa tuen normaaleihin tietokantakyselyihin kuten päivitysoperaatioihin. Esimerkiksi seuraava kysely luo aiemmin nähdyn tietokantataulun sekä lisää sinne rivin.
// ...
Statement statement = connection.createStatement();
// taulun luova kysely
statement.executeUpdate(
"CREATE TABLE Henkilo ("
+ "id INT NOT NULL PRIMARY KEY, "
+ "nimi VARCHAR(255) NOT NULL, "
+ "huone VARCHAR(255))");
// lisätään rivi
statement.executeUpdate("INSERT INTO Henkilo VALUES (1, 'arto', 'B215')");
connection.close();
// ...
Käytännössä suurin osa sovelluksista liittyy tietoon: tiedon hakemiseen tietokannasta, tiedon muokkaamiseen ja näyttämiseen, ja tiedon tallentamiseen tietokantaan. Jos ulkopuolinen sovelluksen käyttäjä voi vaikuttaa tehtävien SQL-kyselyiden sisältöön, pääsee hän vaikuttamaan myös näytettävään tietoon.
Vuonna 2011 kerätyssä vaarallisimmat ohjelmointivirheet sisältävässä listassa on SQL-injektiot numerona 1. Yksinkertaisimmillaan SQL-injektio on tilanne, jossa sovelluksen käyttäjä syöttää SQL-komentoon jotain siihen kuulumatonta, joka saa kyselyn toimimaan eri tavalla, kuin aluksi toivottiin. Oletetaan esimerkiksi että sovellus suorittaa kirjautumisen tarkistamalla onko seuraavan kyselyn tulos tyhjä:
// ...
String nimi = "nimi";
String salasana = "salasana";
String kysely = "SELECT * FROM user WHERE username = '"
+ nimi + "' AND password = '" + salasana + "'";
// ...
Jos käyttäjä antaa käyttäjänimen muodossa haha' OR '1'='1, on kyselyssä tuloksena kaikki taulun user käyttäjät ja kirjautuminen onnistuu aina.
Prepared Statement-kyselyt ovat valmiiksi määriteltyjä kyselyitä, joissa kyselyissä käytettävät arvot annetaan kyselylle parametreina. Valmiita kyselyitä käyttämällä pystytään estämään ainakin osa SQL-injektioista, sillä parametreja käytettäessä varmistetaan että parametrien arvot liittyvät aina vain tiettyyn kenttään -- kyselyparametrit eivät "vuoda yli". Prepared Statement-kyselyt mahdollistavat myös kyselyiden optimoinnin, sillä kysely on aina samanmuotoinen.
Valmiit kyselyt määritellään Connection-olion prepareStatement-metodin avulla. Metodi palauttaa PreparedStatement-olion, johon kyselyn käyttämät arvot määritellään parametreina. Esimerkiksi edellä nähdyssä SQL-injektioesimerkissä oleva kysely luodaan valmiiden kyselyiden avulla seuraavasti:
// ...
String name = "nimi";
String password = "kala";
PreparedStatement statement =
connection.prepareStatement("SELECT * FROM user WHERE username = ? AND password = ?");
statement.setString(1, name);
statement.setString(2, password);
ResultSet resultSet = statement.executeQuery();
// ...
Vastaavasti tietokantaa muokkaavan kyselyn voi tehdä seuraavasti (alla oletetaan että taulussa user on vain kaksi saraketta):
// ...
String name = "nimi";
String password = "kala";
PreparedStatement statement =
connection.prepareStatement("INSERT INTO user VALUES (?, ?)");
statement.setString(1, name);
statement.setString(2, password);
statement.execute();
// ...
Huomaa että tietojenkäsittelytieteilijöille epätyypillisesti kyselyssä käytettävien parametrien indeksointi alkaa numerosta 1.
Datasource
DriverManager-luokkaa käytettäessä yhteys tietokantaan luodaan yleensä alusta asti. Yhteyden luominen voi kestää jopa sekunteja riippuen ajurin lataamisesta, palvelimen sijainnista ja käytössä olevasta infrastruktuurista. DriverManager-olion käyttöä suositellumpi tapa JDBC-yhteyksien luomiseen on DataSource-rajapinnan toteuttavan palvelun käyttö.
Käyttäessämme Spring-sovelluskehystä, saamme DataSource-olion käyttöömme helpohkosti. Luodaan erillinen tiedosto database.xml, johon asetamme tietokantakonfiguraation. Oleellista on rivi <jdbc:embedded-database id="dataSource" type="H2" />, joka käynnistää palvelimen käynnistyessä H2-tietokannan muistiin, ja lataa Springin kontekstiin siihen liittyvän yhteyden. Nyt käytössä on dataSource-niminen olio, jonka voi lisätä sovellukseen @Autowired-annotaation avulla.
Muokataan vielä spring-base.xml tiedostoa siten, että se lataan database.xml-tiedoston käyttöön. Huom! Tiedoston database.xml tulee olla samassa kansiossa spring-base.xml -tiedoston kanssa.
Spring-sovelluskehys sisältää JDBC-kyselyjen tekemistä helpottavan komponentin. Komponentti spring-jdbc saadaan käyttöön lisäämällä se projektin pom.xml-tiedostoon.
Riippuvuus tuo käyttöömme muutamia hyödyllisiä apuvälineitä, joista eräs on JdbcTemplate (dokumentaatio). Luokka JdbcTemplate hoitaa tietokantakyselyihin liittyviä toistuvia asioita puolestamme. Esimerkiksi tietokantayhteyden avaaminen, pyynnön suorittaminen, transaktioiden käsittely sekä yhteyden sulkeminen on luokan JdbcTemplate vastuulla.
Luokan JdbcTemplate-luokan konstruktori tarvitsee DataSource-olion parametrina. DataSource-olio injektoidaan yleensä JdbcTemplate-olion toiminnallisuutta käyttävälle luokalle. Oletetaan, että käytössämme on seuraavankaltainen tietokantataulu:
User
name password
Arto wateva!
Matti rails!
Mikael play!
Kyselyiden muodostaminen JdbcTemplate-luokan avulla on helpohkoa. Luodaan luokka UserDatabase yllä kuvatun taulun käsittelyyn. (Huom! Tarvitsisimme mahdollisesti myös kyselyt tietokannan luomiseen ym. Niitä ei tässä kuitenkaan käsitellä.
// ...
@Component
public class UserDatabase {
private JdbcTemplate jdbcTemplate;
@Autowired
public final void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void addUser(String name, String password) throws SQLException {
this.jdbcTemplate.update("INSERT INTO User VALUES (?, ?)", name, password);
}
public List<Map<String, Object>> retrieveUsers() throws SQLException {
return this.jdbcTemplate.queryForList("SELECT * FROM User");
}
}
RowMapper
Springin JDBC-komponentti tarjoaa myös tuen tulosten kytkemiseen olioihin. Oletetaan että käytössämme on seuraava luokka User:
// pakkaus
public class User {
private String name;
private String password;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
Kyselytulosten kytkeminen olioihin onnistuu JdbcTemplaten ja RowMapper-rajapinnan avulla. Käytännössä RowMapper rajapinnan toteuttava luokka luo ResultSet-oliossa olevista tuloksista halutun tyyppisiä olioita. Luodaan oma UserMapper-luokka, joka toteuttaa rajapinnan RowMapper. Huomaa että rajapinnalle annetaan tyyppiparametrina luokka, johon tulokset kytketään.
// pakkaus ja mahdollisesti muita importteja
import java.sql.ResultSet;
import java.sql.SQLException;
import org.springframework.jdbc.core.RowMapper;
public class UserMapper implements RowMapper<User> {
public User mapRow(ResultSet resultSet, int rowIndex) throws SQLException {
User user = new User();
user.setName(resultSet.getString("name"));
user.setPassword(resultSet.getString("password"));
return user;
}
}
Rajapinnan RowMapper toteuttavia luokkia käytetään Springin JdbcTemplatekyselyjen avulla seuraavasti:
// ... jdbcTemplaten luonti dataSourcen avulla jne
List<User> users = this.jdbcTemplate.query("SELECT * FROM User", new UserMapper());
for(User user: users) {
System.out.println(user.getName() + "\t" + user.getPassword());
}
// ...
Olioita tietokantaan -- quid agis
Huomaamme, että tietokannassa olevien käsitteiden kuvaaminen luokkien avulla on oikeastaan aika loogista. Tietokantataulun nimi vastaa luokan nimeä ja taulun attribuutit (eli sarakkeiden nimet) ovat luokan attribuutteja eli oliomuuttujia. Jokainen luokasta luotava olio vastaa yhtä tietokantataulun riviä. Viitteet eri taulujen välillä voidaan taas kuvata viitteinä olioiden välillä.
Sovelluksia suunniteltaessa yksi suunnittelun aloitustapa on ongelma-alueen tietoa kuvaavien olioiden luonti. Tämä tapahtuu luonnollisesti yhteistyössä asiakkaan kanssa, jolloin voidaan varmistaa että puhutaan asiakkaan ja ongelma-alueen käyttämällä kielellä. Tutkitaan seuraavaa lentokentän hallintajärjestelmän kuvausta:
Case: Lentokenttä
He told us: "...Basically what we need is a system for monitoring aircrafts and airports. Each aircraft has a unique identifier, e.g. LOL-52, and a numeric capacity. Airports on the other hand reside in a location, have a unique identifier and a name, e.g. e.g. LOL for Derby Field United States and FUN for International Tuvalu. Each airport can host one or more aircrafts..."
Ongelma-alueen purkaminen lähtee liikkeelle substantiivien etsimisellä.
He told us: "...Basically what we need is a system for monitoring aircrafts and airports. Each aircraft has a unique identifier, e.g. LOL-52, and a numeric capacity. Airports on the other hand reside in a location, have a unique identifier and a name, e.g. LOL for Derby Field United States and FUN for International Tuvalu. Each airport can host one or more aircrafts..."
Tämän jälkeen substantiiveista erotetaan pääkäsitteet, pääkäsitteiden attribuutit, ja ei-oleelliset käsitteet. Pääkäsitteitä ovat aircraft ja airport, ja system on ei-oleellinen käsite. Loput ovat pääkäsitteiden attribuutteja.
Pääkäsitteiden attribuutit löytyy etsimällä lisätietoa antavia lauseita (esim. has a, in a, ...). Yllä olevasta esimerkistä löytyy seuraavat käsitteet attribuutteineen.
Tämän lisäksi lentokenttä (Airport) sisältää yhden tai useamman lentokoneen. Käsitteitä tietokantaan lisättäviksi olioiksi muunnettaessa jokaiselle luokalle lisätään yleensä numeerinen id-attribuutti, joka toimii taulun pääavaimena. Oliot olisivat lopulta esimerkiksi seuraavankaltaiset:
// pakkaus
public class Aircraft {
private Long id;
private String identifier;
private Integer capacity;
// getterit ja setterit
}
// pakkaus
public class Airport {
private Long id;
private String location;
private String identifier;
private String name;
private List<Aircraft> aircrafts;
// getterit ja setterit
}
Luotujen käsitteiden pohjalta voidaan lähteä hahmottelemaan sovelluksen toimintaa. Oikeastaan tässäkään vaiheessa tietokannan käyttö ei ole vielä pakollista.
DAO-pattern
DAO-pattern (Data Access Object) on suunnittelumalli, jossa tiedon tallennusmekanismi kapseloidaan sovelluslogiikalle näkymättömäksi. DAO-rajapinnan ideana on mahdollistaa tallennusmekanismin helppo vaihtaminen: sovellus voi aluksi säilyttää olioita esimerkiksi muistissa -- rajapinnan käyttäjän ei tarvitse välittää toteutuksesta. Toteutetaan aiemmin esitellyille olioille DAO-oliot ja niihin liittyvät toteutukset.
Luodaan rajapinta AircraftDAO, joka määrittelee lentokoneiden hallintaan liittyvät metodit.
Huomaamme heti toistavamme itseämme. Refaktoroidaan rajapinnoista erillistä tyyppiparametria käyttävä yleishyödyllinen rajapinta DAO.
public interface DAO<T> {
T create(T object);
T read(Long id);
T update(T object);
void delete(Long id);
}
Nyt aiemmat rajapinnat AircraftDAO ja AirportDAO voidaan muuttaa seuraavanlaisiksi.
public interface AircraftDAO extends DAO<Aircraft> {
}
public interface AirportDAO extends DAO<Airport> {
}
Luodaan ensimmäinen DAO-toteutus lentokoneiden tallentamiseen. Koska voimme vaihtaa toteutusta lennossa, tehdään ensimmäinen versio sellaiseksi, että siinä ei ole oikeaa tallennuslogiikkaa. Tiedot tallennetaan AircraftDAO-toteutuksen kapseloimaan Map-tyyppiseen olioon, annotaatio @Component on kuin annotaatio @Service, mutta ei nimeä toimintoa "palveluksi".
// importit
@Component
public class InMemoryAircraftDAO implements AircraftDAO {
private Map<Long, Aircraft> aircrafts;
private Long counter;
@PostConstruct
private void init() {
aircrafts = new TreeMap<Long, Aircraft>();
counter = new Long(1);
}
@Override
public Aircraft create(Aircraft object) {
if (object.getId() != null) {
throw new IllegalArgumentException("A new object should not have an ID");
}
object.setId(counter);
aircrafts.put(object.getId(), object);
counter++;
return object;
}
@Override
public Aircraft read(Long id) {
return aircrafts.get(id);
}
@Override
public Aircraft update(Aircraft object) {
if (object.getId() == null) {
throw new IllegalArgumentException("An object to be updated should have an ID");
}
aircrafts.put(object.getId(), object);
return object;
}
@Override
public void delete(Long id) {
aircrafts.remove(id);
}
}
Käytössämme on nyt luokka AircraftDAO, joka tarjoaa toiminnallisuuden lentokone-olioiden muistiin tallentamiseen. Jos haluamme vaihtaa toteutuksen, meidän tulee luoda toinen toteutus rajapinnalle. Esimerkiksi tiedostoja käyttävä luokka FileAircraftDAO, joka tallentaisi lentokoneet tiedostoon. Tällöin joutuisimme myös määrittelemään komponentille erillisen tunnuksen, jotta olion automaattinen asetus onnistuu.
@Component(value="fileAircraftDAO")
public class FileAircraftDAO implements AircraftDAO {
// ...
}
Myös muistia käyttävälle toteutukselle tulee määritellä oma nimi.
// ...
@Component(value = "inMemoryAircraftDAO")
public class InMemoryAircraftDAO implements AircraftDAO {
// ...
Nyt @Autowired-annotaation lisäksi tulisi @Qualifier-annotaatio, jolla kerrottiin mikä toteutus halutaan käyttöön. Alla olevaan Application luokkaan injektoitaisiin InMemoryAircraftDAO-luokan toteutus.
// ...
@Component
public class Application {
@Autowired
@Qualifier("inMemoryAircraftDAO")
private AircraftDAO aircraftDao;
// ...
ORM ja JPA
ORM-työkalut (Object Relational Mapping) tarjoavat ohjelmistokehittäjälle mm. toiminnallisuutta tietokantataulujen luomiseen määritellyistä luokista. Työkalut hallinnoivat luokkien välisiä viittauksia ja ylläpitävät tietokannan eheyttä, jolloin ohjelmoijan vastuulle jää sovellukselle tarpeellisten kyselyiden toteuttaminen niiltä osin kun niitä ei tarjota valmiiksi.
Relaatiotietokantojen käsittelyyn on kehitetty joukko ORM-sovelluksia. Oracle/Sun standardoi olioiden tallentamisen relaatiotietokantoihin JPA (Java Persistence API) -standardilla. JPA:n toteuttavat kirjastot (esim. EclipseLink ja Hibernate) abstrahoivat relaatiotietokannan, ja mahdollistavat kyselyjen tekemisen suoraan ohjelmakoodista.
Käytämme tällä kurssilla EclipseLink-kirjaston versiota 2.5.0, jonka saa käyttöön lisäämällä projektiin seuraavat riippuvuudet. Alempi riippuvuus tuo käyttöön JPA2.1-APIn.
Muunnetaan luokka Aircraftentiteetiksi, eli olioksi jonka voi tallentaa JPA:n avulla tietokantaan.
// pakkaus
public class Aircraft {
private Long id;
private String identifier;
private Integer capacity;
// getterit ja setterit
}
Jokaisella tietokantaan tallennettavalla oliolla tulee olla annotaatio @Entity sekä @Id-annotaatiolla merkattu attribuutti, joka toimii tietokantataulun ensisijaisena avaimena. JPA:ta käytettäessä id-attribuutti on usein numeerinen (Long tai Integer), mutta merkkijonojen käyttö on yleistymässä.
Numeeriselle avainattribuutille voidaan lisäksi määritellä annotaatio @GeneratedValue(strategy = GenerationType.AUTO), joka antaa id-kentän arvojen luomisen vastuun tietokannalle. Muokataan luokkaa Aircraft vielä siten, että se toteuttaa rajapinnan Serializable, ja lisätään sille tyhjä konstruktori. Luokka näyttää nyt seuraavalta:
// pakkaus
import java.io.Serializable;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Aircraft implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String identifier;
private Integer capacity;
// getterit ja setterit
}
Koska haluamme, että tietokantataulumme ovat selkeitä, ja sarakkeiden nimet kuvaavia, määritellään ne tarkemmin @Column-annotaation avulla. Lisätään luokalle myös @Table-annotaatio, jonka avulla määritellään luotavan tietokantataulun nimi.
Ylläoleva konfiguraatio määrittelee luokasta Aircraft tietokantataulun nimeltä "Aircraft", jolla on sarakkeet "id", "identifier", ja "capacity". Sarakkeiden tyypit päätellään muuttujien tyyppien perusteella.
Palvelinohjelmistot ja konfiguraatio
JPAn käyttämiseksi tarvitsemme konfiguraation käytetylle tietokannalle sekä JPAn vaatiman persistence.xml-konfiguraation, mikä sisältää mm. tiedon siitä, milloin olioista luodaan tietokannan taulut. Tietokantakonfiguraation ja persistence.xml-tiedoston voisi yhdistää, mutta haluamme pitää ne erillään myöhemmin ilmenevistä syistä.
Käytännössä Spring-konfiguraatiomme koostuu nyt kolmesta tiedostosta ja web.xml-tiedostosta. Konfiguraatiotiedosto spring-base.xml sisältää komponenttien automaattisen etsimisen (context:component-scan), vastausten ja pyyntöjen automaattisen haluttuun muotoon muuntajan (mvc:annotation-config), mahdollisen näkymän päättelijän (viewresolver) sekä tietokantakonfiguraation lataamisen.
Tiedosto database.xml sisältää tietokantakonfiguraation, missä määritellään muun muassa annotaatioihin perustuva tietokantatransaktioiden käsittely, tietokantakohtaisten poikkeusten muuntaminen yhtenäisempään muotoon sekä automaattisesti käytössä oleva muistiin ladattava tietokanta. Huom! Nämä konfiguraatiot eivät ole kurssin arvostelun kannalta oleellisia -- halutessasi voit ajatella että ne on saatu mavenin archetype-mekanismin avulla, toisaalta halutessasi voit tulla juttelemaan niin kerron näistä lisää. Oleellisempiin asioihin paneudutaan vielä kurssin edetessä.
JPA:n konfigurointi tapahtuu persistence.xml-nimisen tiedoston avulla. Tiedosto persistence.xml asetetaan kansioon NetBeansissa näkyvään Other Sources-kansion (kansio /src/main/resources/) sisälle META-INF-kansioon. Alla olevassa konfiguraatiossa tiedostoon persistence.xml on konfiguroitu SQL-kyselyiden automaattinen tulostaminen ja tietokantataulujen automaattinen uudelleenluonti sovellusta käynnistettäessä.
Tämän lisäksi, koska useat ohjelmoijat ovat päättäneet toteuttaa oman logituskirjastonsa ja jakaa niitä muille, lisäämme konfiguraatioon useamman kirjaston, joiden avulla luomme fasaadin yleisimmille logituskirjastoille.
Taas, valmiin projektipohjan saa luotua myös Maven archetypen avulla.
EntityManager ja olioiden tallentaminen tietokantaan
Luokka EntityManager hallinnoi entiteettejä ja niiden tallennusta tietokantaan. Sovelluskehys -- tai sovelluskehittäjä -- luo EntityManagerin tarpeen vaatiessa. EntityManager tarjoaa joukon palveluita, joista oleellisimmat ovat lisääminen (komennot persist ja merge), poistaminen (komento remove) ja hakeminen (komento find). EntityManager lisätään sovellukselle @PersistenceContext-annotaation avulla (toimii kuten @Autowired).
Luodaan rajapinnan AircraftDAO toteuttava luokka JpaAircraftDAO, joka käyttää JPA:ta olioiden tallentamiseen tietokantaan. Huomaa, että annotoimme luokan annotaatiolla @Repository. Spring muuntaa @Repository-annotaatioilla merkityissä luokissa tapahtuvat tietokantapoikkeukset ihmisystävällisemmiksi, sekä injektoi EntityManager-olion annotaatiolla @PersistenceContext merkittyyn olioon.
Yllä on kaikki koodi mitä Aircraft-olioiden tietokantaan tallentamiseen tarvitaan.
Annotaatiolla @Transactional määrittelemme, että jokainen luokan metodi suoritetaan omassa transaktiossa. Huomaat todennäköisesti, että käytämme EntityManager-olion merge-metodia useassa paikassa. Metodi merge luo olion tietokantaan, jos se ei ole jo tietokannassa. Jos olio on jo tietokannassa, se päivittää olion tilan tietokantaan. Metodi palauttaa viitteen tietokannassa olevaan olioon.
Spring ja transaktiot
Spring tarjoaa apuvälineitä transaktioiden hallintaan. Tiedostossa database.xml konfiguroitu luokka JpaTransactionManager delegoi transaktioiden käsittelyn EntityManager-olioille. Käytännössä transaktiot voidaan määritellä metodi- tai luokkatasolla annotaation @Transactional avulla. Tällöin annotaatiolla @Transactional merkittyä metodia suoritettaessa metodin alussa aloitetaan tietokantatransaktio, jossa tehdyt muutokset viedään tietokantaan metodin lopussa. Jos annotaatio @Transactional määritellään luokkatasolla, se koskee jokaista luokan metodia.
// pakkaus
@Repository
@Transactional
public class JpaAircraftDAO implements AircraftDAO {
@PersistenceContext
private EntityManager entityManager;
public Aircraft create(Aircraft object) {
return entityManager.merge(object);
}
public Aircraft read(Long id) {
return entityManager.find(Aircraft.class, id);
}
// ...
Emme käytännössä kuitenkaan halua jokaiselle metodille transaktiota, jossa tietokantamuutosten tekeminen on mahdollista. Annotaatiolle @Transactional voidaan määritellä parametri readOnly, jonka avulla määritellään kirjoitetaanko muutokset tietokantaan. Jos parametrin readOnly arvo on true, metodiin liittyvä transaktio perutaan metodin lopussa (rollback). Tällöin metodi ei yksinkertaisesti voi muuttaa tietokannassa olevaa tietoa. Muunnetaan ylläoleva luokka sellaiseksi, että metodi create käyttää tietokantaa muokkaavaa transaktiota, mutta metodissa read ei voi tehdä tietokantamuutoksia.
// pakkaus
@Repository
public class JpaAircraftDAO implements AircraftDAO {
@PersistenceContext
private EntityManager entityManager;
@Transactional(readOnly=false)
public Aircraft create(Aircraft object) {
return entityManager.merge(object);
}
@Transactional(readOnly=true)
public Aircraft read(Long id) {
return entityManager.find(Aircraft.class, id);
}
// ...
JPQL
JPQL (Java Persistence Query Language on kyselykieli, jonka avulla @Entity-annotaatioilla merkittyjen luokkien ilmentymiä voidaan hakea tietokannasta. Kyselyt ovat SQL-kyselyiden kaltaisia, mutta JPQL ei tue kaikkia SQL-kielen ominaisuuksia. EntityManager-ilmentymän avulla on mahdollista kirjoittaa myös puhtaita SQL-kyselyitä. Kaikki Aircraft-oliot listaava kysely on seuraavanlainen.
SELECT a FROM Aircraft a
EntityManager-luokan ilmentymän avulla voimme hakea listan esineitä vastaavasti.
String queryString = "SELECT a FROM Aircraft a";
Query query = entityManager.createQuery(queryString);
List<Aircraft> aircrafts = query.getResultList();
Ehtojen lisääminen tapahtuu parametrien avulla
String queryString = "SELECT a FROM Aircraft a WHERE a.capacity = :capacity";
Query query = entityManager.createQuery(queryString);
query.setParameter("capacity", 33);
List<Aircraft> aircrafts = query.getResultList();
Huom! Kyselyissä käytettävä Aircraft on entiteetin nimi, ei tietokantataulun nimi. Jos @Entity-annotaatiolle ei määritellä name-attribuuttia, entiteetin nimenä käytetään oletuksena luokan nimeä.
Ajan tallentaminen
Aikaa kuvaavat attribuutit tulee annotoida @Temporal-annotaatiolla, joka määrittelee mikä osa ajasta tallennetaan. Annotaatiolle annetaan parametrina TemporalType-tyyppinen arvo, joka kertoo tarkemman tallennusmuodon. Arvo TemporalType.DATE tallentaa päivämäärän (esim. 2012-09-15), TemporalType.TIME tallentaa kellonajan (esim. 18:00:00), ja arvo TemporalType.TIMESTAMP tallentaa päivän ja ajan (esim. 2012-09-15 18:00:00).
Annotaatiolla @Temporal merkityn attribuutin tulee olla joko tyyppiä java.util.Date tai tyyppiä java.util.Calendar. Alla on määritelty entiteettiluokka GroceryItem, joka kuvaa elintarviketta. Elintarvikkeella on myös parasta ennen-päivämäärä (bestBeforeDate).
Oikeastaan, yllä olevassa luokassa on hyvin paljon toiminnallisuutta, joka on yleistä kaikille tietokantaolioita tallentaville luokille. Esimerkiksi lentokenttiä tallentava luokka olisi lähes samanlainen.
Oikeastaan, erittäin samanlainen. Voimme toteuttaa abstraktin luokan, joka saa tyyppiparametrina käytettävät toiminnallisuudet käyttöönsä. Samalla luomme myös DAO-rajapinnasta erillisen yleisen rajapinnan. Käytännössä lähes jokainen JPA:n kanssa paininut paljon tietokantakyselyitä luova sovelluskehittäjä on jossain vaiheessa luonut itselleen hieman seuraavankaltaisen pohjan, jonka perimällä saa käyttöön oleellisimmat toiminnot.
// yleiskäyttönen JpaDao
public abstract class JpaDAO<T> implements DAO<T> {
@PersistenceContext
EntityManager entityManager;
private Class clazz;
public JpaDAO(Class clazz) {
this.clazz = clazz;
}
@Override
public void create(T instance) {
entityManager.merge(instance);
}
@Override
public T read(Long id) {
return (T)entityManager.find(clazz, id);
}
@Override
public T update(T instance) {
return entityManager.merge(instance);
}
@Override
public void delete(Long id) {
T instance = read(id);
if(instance != null) {
entityManager.remove(instance);
}
}
@Override
public List<T> list() {
// CriteriaBuilder on ohjelmallinen API kyselyjen tekemiseen
CriteriaBuilder criteriaBuilder = entityManager.getCriteriaBuilder();
CriteriaQuery query = criteriaBuilder.createQuery(clazz);
return entityManager.createQuery(query).getResultList();
}
}
Konkreettinen tietokantatoiminnallisuus yllä olevaa luokkaa käyttäen onnistuu perimällä yllä olevan luokan. Aiemmin toteutettu JpaAircraftDAO pienenee seuraavaan muotoon.
// pakkaus
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import org.springframework.stereotype.Repository;
import org.springframework.transaction.annotation.Transactional;
@Repository
@Transactional
public class JpaAircraftDAO extends JpaDAO<Aircraft> implements AircraftDAO {
public JpaAircraftDAO() {
super(Aircraft.class);
}
}
Saman asian ovat huomanneet myös Spring-projektin tyypit.
Spring Data JPA (http://projects.spring.io/spring-data-jpa/) on Spring-sovelluskehykseen liittyvä projekti, joka helpottaa tyypillisten JPA-tietokantaluokkien toteuttamista. Spring Data JPAn etuna muihin toteutuksiin on integroituminen Spring-sovelluskehykseen, ja sitä kautta komponenttien automaattiseen muistiin lataamiseen ja @Autowired-annotaatiolla merkittyjen rajapintojen tarkisteluun.
Spring Data JPA on valmiiksi konfiguroituna osana aiempaa konfiguraatiotamme. Tiedoston database.xml rivi <jpa:repositories base-package="wad" /> lataa sen käyttöömme, ja pyytää Spring Data JPA:ta etsimään tietokantalogiikkaan liittyviä rajapintoja pakkauksesta wad tai sen alipakkauksista.
Lentokoneiden tallentaminen, taas!
Toteutetaan JpaAircraftDAO-luokkaa vastaava toiminnallisuus Spring Data JPA:n avulla. Määritellään ensin oma rajapinta AircraftRepository, joka perii Spring Data JPAn CrudRepository-rajapinnan.
Nyt voimme toteuttaa luokan, missä lentokoneita käytetään. Toteutetaan kontrolleriluokka AircraftController, jonka kuuntelee polkuun "aircrafts" tehtäviä pyyntöjä. GET-tyyppinen pyyntö palauttaa JSP-muotoisen sivun, jossa on listaus lentokoneista, ja POST-tyyppinen pyyntö luo uuden lentokoneen ja ohjaa pyynnön GET-metodille.
Hei! Eihän tuolla toteutettu tuota AircraftRepository-rajapintaa! Ei niin. Koska huomattava osa JPA- ja tietokantatoiminnallisuudesta on hyvin samankaltaista (kuten abstraktia JpaDAO-luokkaa toteutettaessa huomattiin), voi vastaavan toiminnallisuuden toteuttaa Spring-sovelluskehyksen puolelle. Käytännössä Spring Data JPA sisältää sen tarjoamat rajapinnat (esim. JpaRepository) toteuttavat luokat, jotka voidaan injektoida automaattisesti @Autowired-annotaatiolla merkityille rajapinnoilla.
Spring Data JPA:n käyttämissä luokissa on määritelty luokkatason transaktiot, joten tallennusoperaatiot toimivat myös ilman @Transactional-annotaatiota.
Easy Storing of Objects
Luodaan sovellus esineiden lisäämiseen tietokantaan. Käyttöliittymätiedostot sekä tarvittava konfiguraatio tulee valmiina projektin mukana.
Tallennettava: Item
Luo pakkaukseen wad.storage.domain luokka Item, joka toteuttaa rajapinnan Serializable. Luokalla Item tulee olla @Entity-annotaatio sekä attribuutit id, name ja count, joiden tyypit ovat Long, String ja Integer vastaavasti.
Lisää attribuutille id annotaatiot @Id, @GeneratedValue(strategy = GenerationType.TABLE) ja @Column. Lisää @Column annotaatio myös attribuuteille name ja count. Lisää jokaiselle attribuutille myös get- ja set-metodit.
Tallentaja: ItemRepository
Luo seuraavaksi pakkaukseen wad.storage.repositoryrajapintaluokka ItemRepository. Rajapintaluokka ItemRepository perii Spring Data JPA:n rajapintaluokan CrudRepository siten, että tallennettava olio on tyyppiä Item, ja avaimena on Long.
Kontrolleri: StorageController
Luo pakkaukseen wad.storage.controller luokka StorageController, joka toteuttaa rajapinnan StorageControllerInterface. Luokka StorageController kapseloi rajapintaluokan ItemRepository, jonka tulee olla merkattu annotaatiolla @Autowired. Toteuta luokalta StorageController vaaditut metodit seuraavasti:
Metodi String view(Model model) kuuntelee GET-tyyppisiä pyyntöjä osoitteeseen view. Pyynnössä ei ole parametreja. Metodi view saa parametrinaan Model-olion, jonka attribuuttiin items tulee asettaa kaikki rajapintaluokasta ItemRepository metodilla findAll saatavat esineet. Metodi palauttaa view-merkkijonon, jolloin käyttäjälle näytetään /WEB-INF/jsp/view.jsp-tiedosto.
Metodi String add(String name) kuuntelee POST-tyyppisiä pyyntöjä osoitteeseen add. Pyynnössä tulee olla parametri nimeltä name, jonka pohjalta luodaan uusi Item-olio, joka tallennetaan rajapintaluokan ItemRepository avulla. Uuden Item-olion count-muuttujan arvon tulee olla aina aluksi 1. Pyyntö ohjataan lopulta view-osoitteeseen.
Metodi String increaseCount(Long itemId) kuuntelee POST-tyyppisiä pyyntöjä osoitteeseen increaseCount. Pyynnössä tulee olla parametri nimeltä itemId. Pyynnön parametria itemId käytetään Item-olion etsimiseen ItemRepository-rajapintaluokan avulla. Kun olio on löytynyt, kasvata sen count-arvoa yhdellä ja ohjaa pyyntö view-osoitteeseen. Muistathan varmistaa että olion uusi arvo tallennetaan myös tietokantaan (esim. ItemRepository-oliota käyttämällä..).
Kun sovelluksesi toimii, lähetä se TMC:lle.
Omien kyselyiden toteuttaminen
Spring Data JPA ei tarjoa kaikkia kyselyitä valmiiksi. Jos tarvitset tietynlaisen kyselyn, sinun tulee yleensäottaen myös määritellä se. Laajennetaan aiemmin määriteltyä rajapintaa AircraftRepository siten, että sillä on metodi List<Aircraft> findByCapacity(Integer capacity) -- eli hae koneet, joilla on tietty kapasiteetti.
Ylläoleva esimerkki on esimerkki kyselystä, johon Spring Data ei tarvitse erillistä toteutusta. Se arvaa että kysely olisi muotoa SELECT a FROM Aircraft a WHERE a.capacity = :capacity, ja luo sen valmiiksi. Lisää Spring Data JPA:n kyselyjen arvaamisesta löytyy sen dokumentaatiosta.
Tehdään toinen esimerkki, jossa joudumme oikeasti luomaan oman kyselyn. Lisätään rajapinnalle AircraftRepository metodi findAirForceOne, joka suorittaa kyselyn "SELECT a FROM Aircraft a WHERE a.identifier = 'Air Force One'".
// pakkaus
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.CrudRepository;
public interface AircraftRepository extends CrudRepository<Aircraft, Long> {
List<Aircraft> findByCapacity(Integer capacity);
@Query("SELECT a FROM Aircraft a WHERE a.identifier = 'Air Force One'")
Aircraft findAirForceOne();
}
Käytössämme on nyt myös metodi findAirForceOne, joka suorittaa @Query-annotaatiossa määritellyn kyselyn. Tarkempi kuvaus kyselyiden määrittelystä osana rajapintaa löytyy Spring Data JPAn dokumentaatiosta.
Jatkokehitetään tässä tehtävässä sovellusta lentokoneiden ja lentokenttien hallintaan. Projektissa on jo valmiina ohjelmisto, jossa voidaan lisätä ja poistaa lentokoneita. Tavoitteena on lisätä toiminnallisuus lentokoneiden kotikenttien asettamiseksi.
Tallennettavat: Aircraft ja Airport.
Lisää luokkaan Aircraft attribuutti airport, joka kuvaa lentokoneen kotikenttää, ja on tyyppiä Airport. Koska usealla lentokoneella voi olla sama kotikenttä, käytä attribuutille airport annotaatiota @ManyToOne. Lisää attribuutille myös @JoinColumn-annotaatio, jonka avulla kerrotaan että tämä attribuutti viittaa toiseen tauluun. Lisää luokalle myös oleelliset get- ja set-metodit.
Lisää seuraavaksi Airport-luokkaan attribuutti aircrafts, joka kuvaa kaikkia koneita, keiden kotikenttä kyseinen kenttä on, ja joka on tyyppiä List<Aircraft>. Koska yhdellä lentokentällä voi olla useita koneita, lisää attribuutille annotaatio @OneToMany. Koska luokan Aircraft attribuutti airport viittaa tähän luokkaan, aseta annotaatioon @OneToMany parametri mappedBy="airport". Nyt luokka Airport tietää että attribuuttiin aircrafts tulee ladata kaikki Aircraft-oliot, jotka viittaavat juuri tähän kenttään.
Lisää myös luokalle Airport oleelliset get- ja set-metodit.
Lentokentän asetus lentokoneelle
Lisää sovellukselle toiminnallisuus lentokentän lisäämiseen lentokoneelle. Käyttöliittymä sisältää jo tarvittavan toiminnallisuuden, joten käytännössä sinun tulee toteuttaa luokan AircraftController metodi String assignAirport. Kun käyttäjä lisää lentokoneelle lentokenttää, käyttöliittymä lähettää POST-tyyppisen kyselyn osoitteeseen /app/aircrafts/{aircraftId}/airports, missä aircraftId on lentokoneen tietokantatunnus. Pyynnön mukana tulee lisäksi parametri airportId, joka sisältää lentokentän tietokantatunnuksen.
Toteuta metodi siten, että haet aluksi tietokantatunnuksia käyttäen lentokoneen ja lentokentän, tämän jälkeen asetat lentokoneelle lentokentän ja lentokentälle lentokoneen, ja tallennat haetut oliot.
Ohjaa lopuksi pyyntö osoitteeseen /app/aircrafts/
Kun olet valmis, lähetä sovellus TMC:lle tarkistettavaksi.
Tietokantatransaktioiden hallinta palvelutasolla
Sovelluksia suunniteltaessa transaktiot toteutetaan yleensä palvelutasolla. Tällöin tietokantatason operaatioita kerätään saman transaktion sisään, ja kaikkien suoritus riippuu transaktion onnistumisesta. Oletetaan että käytössämme on aiemmin luotu AircraftRepository, ja Aircraft-olioiden avain on tyyppiä Long. Luodaan rajapinta AircraftService, joka tarjoaa metodit Iterable<Aircraft> list() ja void changeIdentifierString(Long aircraftId, String identifierString).
Luodaan seuraavaksi rajapinnalle toteutus. Tutki erityisesti metodin changeIdentifierString toteutusta.
// importit ym
@Service
public class RepositoryAircraftService implements AircraftService {
@Autowired
private AircraftRepository aircraftRepository;
@Override
@Transactional(readOnly = true)
public Iterable<Aircraft> list() {
return aircraftRepository.findAll();
}
@Override
@Transactional(readOnly = false)
public void changeIdentifierString(Long aircraftId, String identifierString) {
Aircraft craft = aircraftRepository.findOne(aircraftId);
if ( craft == null ) {
throw new NoSuchElementException("No aircraft with id " + aircraftId);
}
craft.setIdentifier(identifierString);
}
//...
Huomionarvoista on että metodissa changeIdentifierString oliota Aircraft ei tallenneta erikseen. JPAn EntityManager-luokkaa käytettäessä entiteetit ovat EntityManager-olion hallinnoitavana koko transaktion ajan. Metodissa changeIdentifierString aloitetaan transaktio, luetaan Aircraft-olio tietokannasta, ja asetetaan oliolle uusi identifier-muuttujan arvo metodilla setIdentifier. Transaktion lopussa EntityManager tutkii onko hallinnoitaviin olioihin tehty muutoksia. Jos muutoksia on tehty, muutokset tallennetaan tietokantaan automaattisesti.
Entiteetti on hallinnoitava jos EntityManager on hakenut sen tietokannasta kyseisen transaktion sisällä -- nyt transaktio aloitetaan metodin alussa. Myös Spring Data JPA käyttää EntityManager-olioita toteutuksessaan.
Seuraavaa tehtävää tehtäessä kannattaa pohtia olisiko erillisen palvelukerroksen toteuttamisesta hyötyä. Tällöin sovelluksen kommunikointi kulkisi kutakuinkin seuraavasti: käyttäjä tekee pyynnön sivulla -- kontrolleri vastaanottaa pyynnön ja ohjaa sen sopivalle palvelukerroksen luokalle -- palvelukerros käsittelee tietokannassa olevia olioita Spring Data JPA:n avulla, palvelukerroksessa on myös transaktio, ja palauttaa vastauksen kontrollerille -- kontrolleri lisää palvelusta saadun datan modeliin, ja ohjaa pyynnön sopivalle JSP-sivulle.
Movie Database
Tämä tehtävä on avoin tehtävä jossa saat itse suunnitella huomattavan osan ohjelman sisäisestä rakenteesta. Ainut määritelty asia ohjelmassa on käyttöliittymä, joka tulee tehtäväpohjan mukana. Tehtäväpohjassa on myös valmis konfiguraatio spring-projektille.
Tehtävästä on mahdollista saada yhteensä 4 pistettä.
Huom! Aloita näyttelijän lisäämisestä ja poistamisesta. Suunnittele ensin sopiva tietokantaolio, sekä sille sopivat repository-oliot. Jatka tämän jälkeen kontrollerin toteutuksella -- sekä mahdollisesti palvelukerroksen lisäämisellä. Kannattanee hyödyntää käyttöliittymätiedostoissa näkyvää EL-kieltä tietokantaolioiden attribuuttien määrittelyssä.
Pisteytys:
+ 1p: Näyttelijän lisääminen ja poistaminen onnistuu. Käyttöliittymän olettamat osoitteet ja niiden parametrit:
GET /app/actors - näyttelijöiden listaus, ei parametreja pyynnössä.
POST /app/actors - parametri name, joka sisältää lisättävän näyttelijän nimen. Lisäyksen tulee lopulta ohjata pyyntö osoitteeseen /app/actors.
POST /app/actors/{actorId}/delete - polun parametri actorId, joka sisältää poistettavan näyttelijän tietokantatunnuksen. Poiston tulee lopulta ohjata pyyntö osoitteeseen /app/actors.
+ 1p: Elokuvan lisääminen ja poistaminen onnistuu. Käyttöliittymän olettamat osoitteet ja niiden parametrit:
GET /app/movies - elokuvien listaus, ei parametreja pyynnössä.
POST /app/movies - elokuvan lisäys, parametrit name, joka sisältää lisättävän elokuvan nimen, ja lengthInMinutes, joka sisältää elokuvan pituuden minuuteissa. Lisäyksen tulee lopulta ohjata pyyntö osoitteeseen /app/movies.
POST /app/movies/{movieId}/delete - polun parametri movieId, joka sisältää poistettavan elokuvan tietokantatunnuksen. Poiston tulee lopulta ohjata pyyntö osoitteeseen /app/movies.
+ 2p: Näyttelijän voi lisätä elokuvaan (kun näyttelijä tai elokuva poistetaan, tulee myös poistaa viitteet näyttelijästä elokuvaan ja elokuvasta näyttelijään). Käyttöliittymän olettamat osoitteet ja niiden parametrit:
GET /app/actors/{actorId} - polun parametri actorId, joka sisältää näytettävän näyttelijän tietokantatunnuksen. Näyttää sivun /WEB-INF/jsp/actor.jsp (tutustu tiedostoon, ja varmista että pyynnössä on sivun sisältämät attribuutit.)
POST /app/actors/{actorId}/movies - polun parametri actorId, joka sisältää kytkettävän näyttelijän tietokantatunnuksen, ja parametri movieId, joka sisältää kytkettävän elokuvan tietokantatunnuksen. Lisäämisen tulee lopulta ohjata pyyntö osoitteeseen /app/actors.
end of wk3
Pieni HTTPn kertaus. Minkälaisia osia HTTP-pyynnössä on? Mikä on pyynnön runko, ja mitä se mahdollisesti sisältää?
Mistä lyhenne ACID koostuu?
Mikä on tietokantatransaktio?
Mikä on ORM? Mihin sitä käytetään? Miten JPA liittyy tähän?
Mitä tekee @Controller?
Mitä tekee @Service?
Mitä tekee @Repository?
start of wk4
RESTgull Service
Tietojenkäsittelytieteen laitos on erikoistunut muiden erikoisalueidensa lisäksi lokkien bongaamiseen. Erästä TKTL:llä yhä kehitettävää järjestelmää käytetään lintubongausten hallinnointiin mm. museoviraston toimesta. Tässä tehtävässä toteutetaan REST-tyyppinen JSON-dataa käsittelevä rajapinta lokkibongausten käsittelyyn.
Sovelluksessa on toteutettuna kaikki muut luokat paitsi luokka GullSightingController. Toteuta luokkaan seuraava toiminnallisuus:
GET-pyyntö osoitteeseen gulls palauttaa JSON-muotoisen listan tietokannassa olevista havainnoista. Käytä GullSightingService-rajapintaa havaintojen noutamiseen.
GET-pyyntö osoitteeseen gulls/{tunnus} palauttaa JSON-muotoisen esityksen tunnus-polkumuuttujan identifioimasta havainnosta. Käytä olemassaolevaa GullSightingService-rajapintaa havainnon noutamiseen.
JSON-dataa sisältävä POST-pyyntö osoitteeseen gulls tallentaa uuden GullSighting-olion GullSightingService-rajapinnan avulla ja palauttaa juuri tallennetun havainnon JSON-muotoisena.
DELETE-pyyntö osoitteeseen gulls/{tunnus} poistaa havainnon tunnuksella tunnus. Osoite palauttaa poistetun havainnon JSON-muotoisen esityksen.
Kun olet valmis, testaa toteuttamasi palvelun toimintaa esimerkiksi POSTManin avulla.
Palvelin- tai muistiongelmia?
NetBeans jättää sovellukset käytössä olevalle palvelimelle tulevaa testausta varten. Tämä on kätevää silloin, kun kehitettäviä sovelluksia on muutama. Tapauksessamme kuitenkin sovelluksia on kymmeniä, mikä voi johtaa siihen, että palvelimen käynnistäminen hidastuu, ja palvelin vaatii reilusti muistia.
Voit poistaa olemassaolevia sovelluksia palvelimelta NetBeansin kautta palvelimen ollessa käynnissä valitsemalla Services-välilehden ja avaamalla osion Servers. Näet siellä käytössä olevat palvelimet. Klikkaamalla käynnissä olevaa palvelinta, näet sen sisältämät web-sovellukset.
Voit poistaa yksittäisiä sovelluksia oikealla hiirennäppäimellä, ja valitsemalla "Undeploy". Älä kuitenkaan poista sovelluksia "/home", "/manager", ja "/".
Tämän lisäksi, voit lisätä palvelimen käyttöön lisää muistia muokkaamalla palvelimelle käyttöön annettavaa muistimäärää. Tämä ratkoo osittain yleisimpiä muistiongelmia (OutOfMemoryError). NetBeans tarjoaa (nykyään) mahdollisuuden lisätä osalle palvelimista ylimääräisiä Java-virtuaalikoneen parametreja. Esimerkiksi TomEE-palvelimen parametreja saa muokattua klikkaamalla Services-välilehdellä TomEE-palvelinta, ja valitsemalla Properties. Saat tutkittua ja lisättyä virtuaalikoneen parametreja osiossa Platform ja VM-options.
Lisäämällä VM Options kohtaan merkkijonon:
-Xmx1G -XX:MaxPermSize=256m
Sanot palvelimelle, että se saa käyttää maksimissaan gigatavun muistia, josta 256 megatavua luokkien tietojen tallentamiseen.
Perinteisesti Java-ohjelmissa luokat ladataan muistiin ohjelman käynnistyessä, ja niitä ei poisteta oletuksena. Automaattinen roskienkeruu on siis koskenut vain olioiden poistamista. Dynaamisten ohjelmointikielten ja luokkien automaattisen generoinnin myötä tämä kuitenkin aiheuttaa päänvaivaa, sillä käytössä oleva muisti täyttyy hiljalleen automaattisesti luotavista luokista.
Haluamme usein tallentaa olion joka viittaa olioon, josta viitataan takaisin. Esimerkiksi edellisen viikon tehtävässä lentokone tietää lentokentästä ja lentokenttä lentokoneesta.
Pohditaan tätä kontekstissa, jossa tavoitteena on lisätä uusia henkilö-olioita olemassaolevaan huoneeseen. Huoneella on lista siinä olevista henkilöistä. Yksi ratkaisu on seuraava.
@Transactional(readOnly = false)
public void lisaaHenkilo(Henkilo henkilo, Long huoneId) {
Huone huone = huoneRepository.findOne(huoneId); // etsitään oikea huone
henkilo.setHuone(huone);
henkilo = henkiloRepository.save(henkilo); // tallennetaan henkilö save-komennolla
// näin saamme viitteen luotuun henkilöön
// lisätään henkilö vielä huoneeseen.
huone.getHenkilot().add(henkilo);
}
Koska ylläolevassa esimerkissä koodi suoritetaan transaktion sisällä, kaikki tietokannasta haettavat tai tietokantaan luotavat oliot ovat saman hallinnoijan (EntityManager) alla. Käytännössä hallinnoituihin olioihin tehtävät muutokset viedään tietokantaan transaktion lopussa.
Kaksisuuntaisten viitteiden ylläpito käsin ei ole kovin mukavaa. Ylläolevassa esimerkissä henkilo-oliolle lisätään hallinnoitu viite huoneeseen, johon henkilöä lisätään. Jos luotava henkilö on täysin uusi, toiminnallisuuden parantelu Huone-luokkaan lisättävän lisaaHenkilo-metodin ei auta, sillä alussa käytössämme oleva viite henkilö-olioon ei ole sama viite kuin se, joka luodaan kun henkilö luodaan tietokantaan.
@Transactional(readOnly = false)
public void lisaaHenkilo(Henkilo henkilo, Long huoneId) {
Huone huone = huoneRepository.findOne(huoneId); // etsitään oikea huone
huone.lisaaHenkilo(henkilo);
}
Tämä ei siis vielä toimisi.
Tässä tulee avuksi tallennusten propagointi. Annotaatiolle @OneToMany (sekä muille x-to-x) voi määritellä parametrin cascade, jolla määrittelemme mitkä toiminnot pitää propagoida eteenpäin viitatuille olioille. Voimme esimerkiksi tallentaa Huone-luokan siten, että siihen lisätty -- eli vielä tallentamaton -- henkilö tallennetaan. Tämä tapahtuu seuraavasti. Lisätään Cascade-määre luokalle Huone.
@Entity
public class Huone implements Serializable {
// id ja muut kentät
@OneToMany(mappedBy = "huone", cascade={CascadeType.MERGE, CascadeType.PERSIST})
private List<Henkilo> henkilot;
// getterit ja setterit
Ylläolevassa esimerkissä oletetaan että luokalla Henkilo on attribuutti private Huone huone, sekä siihen liittyvät getterit ja setterit. Nyt kun huone-olio tallennetaan, tallennamme myös siihen liittyvät tallentamattomat henkilöt. Muokataan metodia, jolla lisätään huone.
@Transactional
public void lisaaHenkilo(Henkilo henkilo, Long huoneId) {
Huone huone = huoneRepository.findOne(huoneId); // etsitään oikea huone
huone.getHenkilot().add(henkilo);
henkilo.setHuone(huone);
}
Vaikka ylläoleva ratkaisu on jo mukavan näköinen on siinä vielä parannettavaa. Joudumme vieläkin asettamaan viittauksen henkilöstä huoneeseen! Lisätään taas edellisessä ratkaisussa yritetty lisaaHenkilo-metodi luokalle Huone.
@Transactional
public void lisaaHenkilo(Henkilo henkilo, Long huoneId) {
Huone huone = huoneRepository.findOne(huoneId);
huone.lisaaHenkilo(henkilo);
}
Annotaatioille @OneToOne, @OneToMany, @ManyToOne ja @ManyToMany voi lisätä attribuuttina cascade-arvon, joka kertoo propagoidaanko tehtyjä muutoksia myös viitatuille olioille. Lisää tietoa löytyy muun muassa Oraclen JavaEE-dokumentaatiosta täältä. Huomaa, että cascade-annotaatio ei auta esimerkiksi viitteiden paikalleen jäämiseen. Tähän ei valitettavasti ole vastausta JPA:ssa, mutta osa ORM-toteuttajista tarjoaa joissain tapauksissa ns. orphan removal-tuen.
Poistaminen
Pohditaan seuraavaksi tilannetta, jossa haluaisimme poistaa tietyn henkilön. Ensimmäinen hahmotelma on kutakuinkin seuraavanlainen:
Yllä olevassa lähestymistavassa ongelmana on kuitenkin se, että huoneet eivät kadota viittausta henkilöön. Käytännössä henkilö jää "haamuksi" järjestelmään. Jos haluamme poistaa huoneisiin liittyvät viittaukset henkilöön, joudumme tekemään sen käsin.
Tietokantakyselyn tulosten järjestäminen ja rajoittaminen
Tietokantakyselyn tulokset halutaan usein hakea tai järjestää tietyn kriteerin mukaan. Jos tietokantadatan läpikäynti toteutettaisiin osana palvelinohjelmistoa, tekisimme oikeastaan juuri sen työn, missä tietokannat loistavat. Koska tietokantoihin on usein määritelty attribuutteja varten erilaisia indeksejä, on attribuuttien mukaan hakeminen tyypillisesti varsin nopeaa.
Esimerkiksi alla oleva lisäys tarjoaa metodin henkilöiden etsimiseen, joilla ei ole huonetta.
public interface HenkiloRepository extends JpaRepository<Henkilo, Long> {
List<Henkilo> findByHuoneIsNull();
}
Vastaavasti voisimme hakea esimerkiksi nimen osalla: findByNimiContaining(String osa).
Spring Data JPAn rajapinta JpaRepository mahdollistaa muutaman lisäparametrin käyttämisen osassa pyyntöjä. Voimme esimerkiksi käyttää parametria PageRequest, joka tarjoaa apuvälineet sivuttamiseen sekä pyynnön hakutulosten rajoittamiseen. Alla olevalla PageRequest-oliolla haluasimme ensimmäiset 50 hakutulosta attribuutin nimi mukaan käänteisessä järjestyksessä.
Pageable pageable = new PageRequest(0, 50, Sort.Direction.DESC, "nimi");
Voimme muokata metodia findByHuoneIsNull hyväksymään Pageable-rajapinnan toteuttavan olion parametriksi, jolloin metodi palauttaa Page-luokan ilmentymän.
Tehtäväpohjassa on toteutettuna melko noheva kirjojen hakupalvelu, jossa HTML-sivu noutaa dataa palvelimelta Javascript-koodin avulla. Kun käyttäjä kirjoittaa sivun oikeassa yläkulmassa olevaan laatikkoon tekstiä, ohjelma hakee käyttäjälle sopivat kirjat tietokannassa olevista kirjoista.
Ohjelman toimintaan liittyy kuitenkin pieni mutta. Lähdekoodin auditoinnissa paljastui, että kirjojen järjestäminen ja filtteröinti on toteutettu osana palvelinohjelmistoa: käytetyllä testiaineistolla ongelmaa ei oltaisi ilman auditointia havaittu, mutta palvelun lanseeraus olisi ollut katastrofaalinen lopullisella, kymmeniätuhansia kirjoja sisältävällä aineistolla.
Pikaisella testillä kolmannen osapuolen konsulttipalvelu pääsi noin 200ms kestävistä yksittäisistä hauista:
Noin 30 millisekuntia kestäviin hakuihin (tulokset ovat luonnollisesti konekohtaisia):
Tässä tehtävässä tehtävänäsi on siirtää filtteröinti- ja järjestyslogiikka tietokantasovelluksen vastuulle. Sivun toiminnallisuuden pitäisi pysyä samana, eli sivulla pitäisi näkyä aina maksimissaan 10 kirjaa, jotka ovat aakkosjärjestyksessä kirjan nimen mukaan.
Tehtävässä ei ole automaattisia testejä, eli voit valita lähestymistavan vapaasti. Kun filtteröinti ja järjestäminen tapahtuu tietokannassa, palauta tehtävä. Tässä ei tarvitse pohtia kirjojen nimien indeksointia (jolla tehokkuutta saisi nostettua vielä reiluhkosti ;)).
NoSQL-tietokannat
NoSQL-tietokannat, eli ei SQL- ja relaatiomalliin pohjautuvat tietokannat, ovat viime aikoina nousseet otsikoihin niiden suorituskyvyn takia. Yksi merkittävistä NoSQL-buumin aloittajista oli Twitterin noin 2010 tekemä päätös vaihtaa pois relaatiotietokannoista; taustasyynä oli "relaatiotietokantojen hitaus".
NoSQL on oikeastaan yleinen termi koko perheelle erilaisia tietokantoja. Tyypillisimmät NoSQL-tietokannat ovat avain-arvo -tietokantoja, joissa yksittäisen avaimen perusteella tapahtuvien hakujen nopeutta on pyritty optimoimaan. Muita vaihtoehtoja ovat muunmuassa dokumenttitietokannat sekä erilaiset verkkotietokannat. Vaikka NoSQL-tietokantoihin assosioidaan usein nopeus, nopeuteen vaikuttaa erityisesti käyttötapaus. Esimerkiksi yksittäisen avaimen perusteella tapahtuvat haut voivat olla nopeampia avain-arvo -tietokannoissa, erityisesti jos kaikki käytössä oleva data mahtuu muistiin. Toisaalta, relaatiotietokannat ovat erityisen hyviä myös tiedon jakamisessa levyille.
Suurin osa laajoistakin palvelinohjelmistoista toimii tehokkaasti relaatiotietokannoilla, kunhan relaatiotietokantojen olemassaolevia ominaisuuksia kuten indeksointi hyödynnetään: tulevaisuudessa siirrytään todennäköisesti enemmän ja enemmän tietokantoihin, jotka tukevat sekä relaatiomallia, että joitakin NoSQL-tietokantojen malleja.
Kolmannen osapuolen perspektiivi
Lue myös mitä MySQL:n ja MariaDB:n isä Monty Widenius on mieltä NoSQL-tietokannoista.
The main reason Twitter had problems with MySQL back then, was that they were using it incorrectly. The strange thing was that the solution they suggested for solving their problems could be done just as easily in MySQL as in Cassandra.
Kerrosarkkitehtuuri jakaa sovelluksen kerroksiin; tiedon tallentamiseen ja hakemiseen liittyvään logiikkaan, sovelluksen palveluihin liittyvään logiikkaan, käyttöliittymästä tehtyjä pyyntöjä ohjaavaan kerrokseen, ja käyttöliittymäkerrokseen.
N-tier -arkkitehtuurilla tarkoitetaan yleisesti sovelluksen jakamista itsenäisiin osiin, jotka toimivat vuorovaikutuksessa muiden osien kanssa. Client-Server -arkkitehtuuri on esimerkki 2-tier arkkitehtuurista, 3-tier -arkkitehtuuri taas esimerkiksi jakaa käyttöliittymän, sovelluslogiikan, ja tietokantalogiikan erillisiksi osioikseen. Tällä kurssilla kerrosarkkitehtuurista puhuessamme tarkoitamme yleisesti ottaen seuraavaa jakoa:
Käyttöliittymälogiikka (JSP)
Pyyntöjen ohjaus ja syötteiden tarkistus (Controller)
Palvelulogiikka (Service)
Tallennuslogiikka (Repository)
Tiedon hakemiseen ja tallentamiseen liittyvässä logiikassa käytetään lähes aina valmiita komponentteja, esim. JPA tai Spring Data JPA. Alimman kerroksen toiminnallisuus -- relaatiotietokannat, key/value -tietokannat, dokumenttitietokannat, jne.. -- ovat web-sovelluskehittäjän näkökulmasta "done", eli omaa ei kannata lähteä toteuttamaan.
Sovelluksen oleellisin osa on palveluissa, eli keskitasossa. Sovelluslogiikka sisältää toiminnallisuuden, joka tekee sovelluksestamme arvokkaan. Sovelluslogiikka käyttää alempana olevan tietokantakerroksen tarjoamia palveluita. Sovelluslogiikkakerros sisältää yleensä myös transaktioiden hallinnan.
Sovelluslogiikkakerroksen päällä on käyttöliittymäkutsuja ohjaava kerros, "kontrollikerros". Käyttöliittymäkutsuja ohjaavan kerroksen tehtävänä on toimia rajapintana sovelluskerroksen ja käyttöliittymän välillä. Se vastaanottaa käyttäjän tekemiä pyyntöjä ja ohjaa niitä eteenpäin tarpeellisille palveluille. Kontrollikerroksen tulee olla mahdollisimman ohut; siinä käytetään sovelluskerroksen tarjoamaa toiminnallisuutta. Kutsun suorittamisen jälkeen kontrollikerros palauttaa dataa jossain muodossa. Javascript-kutsulla voi pyytää XML- tai JSON-muodossa olevaa dataa, jonka näyttäminen tapahtuu selainpuolella. Toisaalta, palautettu data voidaan ohjata erilliselle käyttöliittymän renderöintipalvelulle, joka luo näytettävän HTML-sivun.
Kontrollikerroksen päällä on käyttöliittymä. Käyttöliittymiä voi olla useita erilaisia. Kaikille yhteistä on se, että ne tekevät pyyntöjä web-sovelluksen tarjoamiin osoitteisiin.
Sovelluslogiikkakerros
Sovelluslogiikka jaetaan oliosuunnittelun periaatteiden mukaisesti toiminnallisuutta tarjoaviin palveluihin, joita kontrollikerros käyttää. Spring tarjoaa hyvät välineet sovelluslogiikan ja kontrollikerroksen erottamiseen. Tutustumme seuraavaksi kontrolliluokan ja sovelluslogiikan yhteistoimintaan. Pieni kertaus ennen sitä.
Jokaisella oliolla on oma selkeä vastuualueensa, ja niiden sekoittamista tulee välttää. Inversion of Control ja Dependency Injection ovat suunnitelumalleja, joilla pyritään vähentämään olioiden turhia riippuvuuksia.
Inversion of Control
Perinteisissä ohjelmistoissa luokkien ilmentymien luominen on ohjelmoijan vastuulla. Huomasimme jo aiemmin että Spring luo käyttöömme luokkia joita tarvitsemme: Kontrollin käännöllä tarkoitetaan ohjelman toiminnan hallinnan vastuun siirtämistä sovelluskehykselle ja ohjelmaa suorittavalle palvelimelle.
Dependency Injection
Dependency Injectionin tehtävänä on syöttää riippuvuudet silloin kun niitä tarvitaan.
Käytännössä siis: palvelin ja sovelluskehys ottaa vastuuta luokkien hallinnoinnista. Sovelluskehys syöttää riippuvuudet niitä tarvittaessa. Molemmat toiminnallisuudet ovat oleellisia kerrosarkkitehtuurin kerrosten toisistaan erottamisessa.
Palveluesimerkki: HitCounter
Luodaan palvelu jonka tehtävänä on yksittäisten vierailujen määrän laskeminen. Määritellään rajapinta HitCounter-palvelulle. Rajapinta tarjoaa kaksi metodia: getCount(), joka palauttaa kävijöiden määrän, ja incrementCount(), joka kasvattaa kävijöiden määrää yhdellä.
// pakkaus
public interface HitCounter {
int getCount();
void incrementCount();
}
Luodaan rajapinnalle toteutus InMemoryHitCounter. Toteutus merkitään annotaatiolla @Service. Annotaatio @Service on kuin @Component, mutta se kuvaa paremmin komponentit tarkoitusta.
// pakkaus ja muut importit
import org.springframework.stereotype.Service;
@Service
public class InMemoryHitCounter implements HitCounter {
private int count = 0;
@Override
public int getCount() {
return count;
}
@Override
public void incrementCount() {
count++;
}
}
Luodaan seuraavaksi näkymä, jonka tehtävänä on kertoa käyntien määrä. Esimerkissämme näkymä sijaitsee tiedostossa hits.jsp.
Näkymässämme on EL-tägi hits, jonka tehtävänä on näyttää osumien määrä. Luodaan lopuksi kontrolleri HitController, joka vastaanottaa pyynnöt osoitteeseen hitme, kutsuu HitCounter-palvelun tarjoamia metodeja, ja palauttaa lopuksi luodun mallin näkymää varten.
Kontrolleritason ensisijaisena vastuuna on pyyntöjen kuuntelu, pyyntöjen ohjaaminen oikealle palvelulle, sekä tuotetun tiedon ohjaaminen oikealle näkymälle. Jotta palveluille ei ohjata epäoleellista dataa, esimerkiksi huonoja arvoja sisältäviä parametreja, on kontrolleritason vastuulla myös pyyntöparametrien validointi. Parametrien validointi tapahtuu käytännössä käsin, joko siten, että ohjelmoija itse toteuttaa validoinnin, tai jotain olemassaolevaa validointimekanismia käyttämällä.
Pyyntöparametrien validointi
Ensimmäinen askel pyyntöparametrien validointiin on pyyntöparametrien asettaminen odotetun tyyppisiin muuttujiin. Esimerkiksi numeerisia arvoja saavan parametrin oikeellisuuden voi varmistaa asettamalla sen Integer-tyyppiseen muuttujaan. Poikkeustapauksessa tiedämme heti, että käyttäjä on yrittänyt syöttää sovellukselle virheellisiä arvoja.
Alkeellinen muuttujien arvojen validointi toteutetaan kontrolleriin tai erilliseen validointiluokkaan. Oletetaan että seuraava lomake sijaitsee tiedostossa grocery-item-form.jsp, lomakkeen lähetys ohjautuu luokassa GroceryItemController olevalle metodille addGroceryItem. Lisäksi käytössämme on erillinen rajapinta GroceryItemService, joka tarjoaa metodit tallentamiseen ja listaamiseen.
Ensimmäisessä validoinnissa estämme merkkijonot, joiden pituus on alle 5 tai yli 20. Jos merkkijono ei kelpaa, lomakkeessa tulee näyttää virheviesti "Length of name should be between 5 and 20.". Tämän lisäksi lomakkeessa tulee näyttää syötetty teksti.
Jotta lomakkeessa voisi näkyä aiemmin syötetty teksti, tulee lomakkeessa olla sille attribuutti. Muokataan lomaketta siten, että siinä on paikka sekä virheelle että syötetylle datalle. Lomakkeessa olevalle input-elementille voi asettaa arvon value-attribuutin avulla. Virheviesti on merkattu EL-kielen attribuuttina ${nameError} ja näytetään lomakekentän jälkeen.
Muunnetaan seuraavaksi kontrolleriluokassa olevaa addGroceryItem-metodia siten, että nimen ollessa liian pitkä tai liian lyhyt, käyttäjälle palautetaan lomake jossa näkyy aiemmin lähetetty arvo sekä virhekuvaus. Tarvitsemme tätä varten POST-pyyntöä kuuntelevassa metodissa Model-olion.
// ...
@Controller
public class GroceryItemController {
@Autowired
private GroceryItemService groceryItemService;
@RequestMapping(value = "items", method=RequestMethod.GET)
public String viewForm() {
return "grocery-item-form";
}
@RequestMapping(value = "items", method=RequestMethod.POST)
public String addGroceryItem(Model model, @RequestParam String name) {
// validointi
if(name.length() < 5 || name.length() > 20) {
model.addAttribute("name", name);
model.addAttribute("nameError", "Length of name should be between 5 and 20.");
return "grocery-item-form";
}
groceryItemService.add(name);
return "redirect:success"; // muualle
}
// ...
}
Emme pyydä käyttäjän selainta tekemään uudelleenohjausta lomakkeen lähetyksen epäonnistuessa, vaan palautamme käyttäjän takaisin lomakesivulle. Jos tarkistusmetodi tekisi uudelleenohjauksen myös lomakesivulle, ei Model-olioon lisättyjä attribuutteja olisi käytössä.
Going for a Ball
Tehtävän mukana tulee sovellus, jota käytetään tanssijuhliin ilmoittatumiseen. Tällä hetkellä käyttäjä voi ilmoittautua juhliin oikeastaan minkälaisilla tiedoilla tahansa. Tehtävänäsi on toteuttaa parametreille seuraavanlainen validointi:
Nimen (name) tulee olla vähintään 4 merkkiä pitkä ja enintään 30 merkkiä pitkä.
Osoitteen (address) tulee olla vähintään 4 merkkiä pitkä ja enintään 50 merkkiä pitkä.
Sähköpostiosoitteessa (email) tulee olla @-merkki.
Jos yksikään ylläolevista tarkastuksista epäonnistuu, tulee käyttäjälle näyttää rekisteröitymislomake uudelleen. Tällöin lomakkeessa tulee olla lähetetyt parametrit valmiina. Tämän lisäksi jokaiselle virhetapaukselle tulee olla oma virheviesti. Virheviestit lisätään Model-olioon, jotta ne voidaan näyttää näkymässä. Virheviesteinä tulee käyttää seuraavia:
Attribuutin nimi: nameError, arvo: Length of name should be between 4 and 30.
Attribuutin nimi: addressError, arvo: Length of address should be between 4 and 50.
Attribuutin nimi: emailError, arvo: Email should contain a @-character.
Virheviestiä ei tule lisätä vastaukseen jos kyseistä virhettä ei lähetetyssä lomakkeessa ole. Käyttöliittymä on tehtävässä valmiina -- älä muuta luokassa RegistrationController olevien metodien parametrimäärittelyjä. Saat toki muokata metodien sisältöä sekä lisätä uusia metodeja. Alkuperäisten metodien toiminnan tulee säilyä kun käyttäjän antamat rekisteröitymistiedot ovat oikein.
Lomakkeet ja oliot
Kun pohdimme lomakkeita, huomaamme että ne sopivat melko hyvin olio-ohjelmointiajatteluun. Lomakkeissa syötetään usein tietoa johonkin käsitteeseen -- luokkaan liittyen -- ja yhden lomakkeen sisältämät tiedot kuvautuvat helposti oliona. Onkin itseasiassa suhteellisen helppoa rakentaa oma luokka, joka muuntaa pyynnössä olevat parametrit tietynlaiseksi olioksi.
Ajatustasolla olion luominen pyynnöstä tapahtuu luomalla ensin oliosta ilmentymä, ja sen jälkeen käymällä pyynnön parametreja läpi. Jos pyynnössä on parametri, joka on saman niminen kuin olion attribuutti, asetetaan parametrin arvo olion attribuutiksi. Huomattava osa yleisessä käytössä olevista sovelluskehyksistä tekee tämän jollain tavalla puolestamme (Spring tekee tämän automaattisesti jos konfiguraatiossa on rivi <mvc:annotation-config />.
Oletetaan että käytössämme on luokka Person, joka sisältää attribuutit name ja email.
// pakkaus jne
public class Person implements Serializable {
private String name;
private String email;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}
Person-luokalla on attribuutit name ja email. Luodaan lomake tietojen lähettämiseen.
Huomaa, että lomakkeen kenttien nimet ovat samat kuin luokan Person attribuuttien nimet. Luodaan seuraavaksi kontrollerimetodi pyynnön vastaanottamista varten. Spring-sovelluskehyksen annotaatio @ModelAttribute asettaa pyyntöön liittyviä parametreja annotoidun olion arvoksi.
@RequestMapping(value = "person", method = RequestMethod.POST)
public String createPerson(@ModelAttribute Person person) {
// lähetetään person-olio esimerkiksi palvelulle
return "redirect:list";
}
Pyyntöä suoritettaessa Spring asettaa pyynnön parametreja ensin @ModelAttribute-annotaatiolla merkattuihin olioihin. Tämän jälkeen arvoja asetetaan @RequestParam-annotaatiolla merkattuihin muuttujiin.
Olioiden validointi
Lomakkeiden ja lähetettävän datan validointi on web-sovelluksille hyvin oleellista. Ensimmäinen askel -- jonka olemme jo ottaneet -- on tallennettavan datan järkevä esitys. Käytämme datan esittämiseen olioita, joihin on määritelty sopivat kenttien tyypit. Tämä helpottaa työtämme jo hieman: esimerkiksi numerokenttiin ei saa asetettua merkkijonoja.
Tämä ei kuitenkaan vielä riitä.
Javassa on oma API Bean-tyyppisten olioiden validoinnille: Bean Validation API (Javadoc). Bean validation API on, kuten muutkin JSRt (Java Specification Request, vain rajapinta, jolla voi olla useampi toteuttaja. Käytämme JSR-303 -apin, eli Bean Validation APIn, toteutuksena Hibernate Validator-projektia (dokumentaatio), jonka saamme käyttöömme lisäämällä pom.xml-tiedostoon seuraavan riippuvuuden.
Koska JSR-303:n määrittelemä Bean Validation API on hieman vaillinainen, eikä tarjoa työkaluja esimerkiksi sähköpostiosoitteiden validointiin, käytämme suoraan Hibernaten toteutusta.
Oliomuuttujien validointi
Muuttujien validointia varten tarkistettaville muuttujille määritellään annotaatiot. Muokataan aiemmin käytettyä luokkaa Person siten, että henkilöllä tulee olla henkilötunnus, nimi ja sähköpostiosoite.
// pakkaus jne
public class Person {
private String socialSecurityNumber;
private String name;
private String email;
public String getSocialSecurityNumber() {
return socialSecurityNumber;
}
public void setSocialSecurityNumber(String socialSecurityNumber) {
this.socialSecurityNumber = socialSecurityNumber;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}
Lisätään seuraavaksi attribuuttien validointi. Sovitaan että henkilötunnus ei saa koskaan olla tyhjä, ja sen tulee olla tasan 11 merkkiä pitkä. Nimen tulee olla vähintään 5 merkkiä pitkä, ja korkeintaan 30 merkkiä pitkä, ja sähköpostiosoitteen tulee olla validi sähköpostiosoite. Hibernate Validator-projektista löytyy näitä varten sopivia validointiannotaatioita. Annotaatio @NotBlank varmistaa ettei annotoitu attribuutti ole tyhjä -- lisätään se kaikkiin. Annotaatiolla @Length voidaan määritellä pituusrajoitteita muuttujalle, ja annotaatiolla @Email varmistetaan, että attribuutin arvo on varmasti sähköpostiosoite.
// pakkaus
import org.hibernate.validator.constraints.Email;
import org.hibernate.validator.constraints.Length;
import org.hibernate.validator.constraints.NotBlank;
public class Person {
@NotBlank
@Length(min = 11, max = 11)
private String socialSecurityNumber;
@NotBlank
@Length(min = 5, max = 30)
private String name;
@NotBlank
@Email
private String email;
// getterit ja setterit
Pyynnössä saatavan olion, joka on merkitty annotaatiolla @ModelAttribute validointi on helpohkoa. Kun olemme lisänneet Spring-konfiguraatioon komennon <mvc:annotation-driven/>, saamme käyttöön muitakin toiminnallisuuksia kuin olioiden generoinnin pyynnöstä. Yksi ominaisuus on olioiden validointi. Spring lataa automaattisesti käyttöönsä validointikehyksen, jos sellainen löytyy käytössä olevista kirjastoista. Jos olemme lisänneet Hibernate Validator-projektin osaksi pom.xml-tiedostoa, on se käytössämme automaattisesti.
Itse olion validointi tapahtuu lisäämällä kontrollerimetodissa olevalle @ModelAttribute-annotaatiolle merkatulle oliolle annotaatio @Valid (javax.validation.Valid;).
@RequestMapping(value = "persons", method = RequestMethod.POST)
public String create(@Valid @ModelAttribute Person person) {
// .. toteutus
}
Nyt person-olion ilmentymä validoidaan heti kun se kontrollerissa vastaanottaa pyynnön. Validointivirheet eivät kuitenkaan ole kovin kaunista luettavaa. Yllä olevalla kontrollerimetodilla esimerkiksi virheellisen nimen kohdalla saamme statuskoodin 500, sekä hieman kaoottisen ilmoituksen.
org.springframework.web.util.NestedServletException: Request processing failed;
nested exception is org.springframework.validation.BindException:
org.springframework.validation.BeanPropertyBindingResult: 4 errors
Field error in object 'person' on field 'name': rejected value [];
codes [NotBlank.person.name,NotBlank.name,NotBlank.java.lang.String,NotBlank];
arguments [org.springframework.context.support.DefaultMessageSourceResolvable:
codes [person.name,name];
arguments [];
default message [name]];
default message [may not be empty]
...
Ei kovin kaunista katseltavaa.
Helpotetaan elämäämme hieman kytkemällä validointitulokset erilliseen olioon.
Olioiden validointi ja BindingResult
Kontrollerimetodissa oliota validoidessa validointivirheet aiheuttavat poikkeuksen, jos niille ei erikseen määritellä tallennuspaikkaa. Luokka BindingResult toimii validointivirheiden tallennuspaikkana, jonka kautta voimme käsitellä virheitä omien tarpeidemme mukaan. BindingResult-olio kuvaa aina yksittäisen olion luomisen ja validoinnin onnistumista, ja se tulee asettaa heti validoitavan olion jälkeen. Seuraavassa esimerkki kontrollerista, jossa validoinnin tulos lisätään BindingResult-olioon.
@RequestMapping(value = "persons", method = RequestMethod.POST)
public String create(@Valid @ModelAttribute Person person, BindingResult bindingResult) {
if(bindingResult.hasErrors()) {
// validoinnissa virheitä: virheiden käsittely
}
// muu toteutus
}
Ylläolevassa esimerkissä kaikki validointivirheet tallennetaan BindingResult-olioon. Oliolla on metodi hasErrors, jonka perusteella päätämme jatketaanko pyynnön prosessointia vai ei. Yleinen muoto lomakedataa tallentaville kontrollereille on seuraavanlainen:
Yllä oletetaan että lomake lähetettiin sivulta "form". Käytännössä jos näemme virheen validoinnissa, palaamme takaisin sivulle. Aiempaa lähestymistapaa seuraten voisimme käyttää erillistä Model-oliota validointivirheiden lisäämiseksi ja niiden näyttämiseksi sivulla. Tutkitaan seuraavaksi toista tapaa.
Springin lomakkeet ja BindingResult
Spring tarjoaa käyttöömme tägikirjaston lomakkeiden luomiseen JSP-sivulla. Lomakekirjaston saa JSP-sivulla käyttöön lisäämällä sivun alkuun seuraavan komennon.
Komento tuo käyttöömme springin lomakkeet, joita voi käyttää form:-etuliitteellä. Lomakkeet määritellään kuten normaalit HTML-lomakkeet, mutta sisältävät muutaman apuvälineen. Lomakkeen attribuutti commandName kertoo mihin kontrollerissa olevaan olioon lomakkeen kentät tulee pyrkiä liittämään. Sitä käytetään yhdessä kontrolleriluokan ModelAttribute-annotaation kanssa. Lomakkeen kentät määritellään polkujen path avulla, jotka kertovat ModelAttribute-annotaatiolla merkityn olion kentät. Ehkä oleellisin on kuitenkin tägi <form:errors path="..." />, jonka avulla saamme kenttiin liittyvät virheet esille.
Luodaan lomake aiemmin nähdyn Person-olion luomiseen.
Yllä on määritelty lomake, joka lähettää lomakkeen tiedot osoitteessa <sovellus>/person olevalle alla kontrollerimetodille. Lomakkeelle tullessa tarvitsemme erillisen tiedon käytössä olevasta oliosta. Alla on näytetty sekä kontrollerimetodi, joka ohjaa GET-pyynnöt lomakkeeseen, että kontrollerimetodi, joka käsittelee POST-tyyppiset pyynnöt. Huomaa erityisesti @ModelAttribute-annotaatio kummassakin metodissa, sekä annotaation parametri "person", joka vastaa lomakkeessa olevaan command-attribuuttia. Tämän avulla lomake tietää, mitä oliota käsitellään.
// yleistä tauhkaa
@RequestMapping(value = "persons", method = RequestMethod.GET)
public String viewForm(@ModelAttribute("person") Person person) {
return "form";
}
@RequestMapping(value = "persons", method = RequestMethod.POST)
public String create(@Valid @ModelAttribute Person person, BindingResult bindingResult) {
if(bindingResult.hasErrors()) {
return "form";
}
// .. toteutus
}
Jos lomakkeella lähetetyissä kentissä on virheitä, virheet tallentuvat BindingResult-olioon. Tarkistamme kontrollerimetodissa create ensin virheiden olemassaolon -- jos virheitä on, palataan takaisin lomakkeeseen. Tällöin Spring tuo lomakkeelle käyttöön sekä validointivirheet BindingResult-oliosta, että aiemmin lomakkeeseen syötetyt arvot @ModelAttribute-annotaatiolla merkitystä oliosta. Huomaa että virheet ovat pyyntökohtaisia, ja esimerkiksi kutsu "redirect:person" kadottaisi virheet.
Huom! Springin lomakkeita käytettäessä lomakesivut haluavat käyttöönsä olion, johon data kytketään jo sivua ladattaessa. Yllä lisäsimme pyyntöön Person-olion seuraavasti:
@RequestMapping(value = "persons", method = RequestMethod.GET)
public String view(@ModelAttribute("person") Person person) {
return "form";
}
Edellisessä tehtävässä parametrien validointi tehtiin käsin osana kontrolleriluokan toimintaa. Käytetään tällä kertaa ModelAttributea, Spring form-elementtiä ja annotaatioilla tapahtuvaa validointia.
Spring Form-lomake on toteutettu valmiiksi tehtäväpohjan mukana tuleviin JSP-sivuihin. Tehtävänäsi on toteuttaa validointitoiminnallisuus pakkauksessa wad.registration.domain olevaan luokkaan Registration.
Nimen (name) tulee olla vähintään 4 merkkiä pitkä ja enintään 30 merkkiä pitkä.
Osoitteen (address) tulee olla vähintään 4 merkkiä pitkä ja enintään 50 merkkiä pitkä.
Sähköpostiosoitteen (email) tulee olla validi sähköpostiosoite.
Jos yksikään ylläolevista tarkastuksista epäonnistuu, tulee käyttäjälle näyttää rekisteröitymislomake uudelleen. Muista lisätä kontrolleriin validoitavalle parametrille annotaatio @Valid. Virheviestien ei tule näkyä vastauksessa jos lomakkeessa ei ole virhettä. Käyttöliittymä on tehtävässä valmiina.
Validointi ja entiteetit
Vaikka esimerkissämme käyttämäämme Person-luokkaa ei oltu merkitty @Entity-annotaatiolla -- eli se ei ollut tallennettavissa JPAn avulla tietokantaan -- mikään ei estä meitä lisäämästä sille @Entity-annotaatiota. Toisaalta, lomakkeet voivat usein sisältää tietoa, joka liittyy useaan eri talletettavaan olioon. Tällöin onkin fiksua luoda erillinen lomakkeen validointiin tarkoitettu lomakeolio, Form Object, jonka pohjalta luodaan tietokantaan tallennettavat oliot kunhan validointi onnistuu. Erilliseen lomakeobjektiin voi täyttää myös kannasta haettavia listoja ym. ennalta.
Model ja Redirect
Kun käyttäjä ohjataan tekemään uusi pyyntö redirect:-komennon avulla, selaimelle käytännössä palautetaan HTTP statuskoodi 303 (tai 302), sekä uusi osoite. Tällöin selain tekee pyynnön uuteen osoitteeseen. Koska HTTP on tilaton protokolla, ei sillä ole välineistöä käyttäjän pyyntöjen yhdistämiseen: aiemmassa pyynnössä käytössä oleva data ei ole käytössä seuraavassa pyynnössä.
Tämä on yleensä täysin hyväksyttävää, ja toivottavaakin, mutta joissain tapauksissa ohjelmoija haluaa aiemmasta pyynnöstä tietoja myös seuraavaan pyyntöön. Tyypillinen käyttötapaus on tietyn informaatioviestin lisääminen sivulle, johon käyttäjä ohjataan. HTTP-protokollan tarjoamat evästeet mahdollistavat tiedon katoamisen kiertämisen: jos kaivattu tieto tallennetaan sessioon, on se olemassa myös seuraavalla pyynnöllä. Vastaava toiminnallisuus on myös useassa sovelluskehyksessä valmiina.
Spring tarjoaa pyynnöissä käytettävän parametrin RedirectAttributes, johon voi tallentaa attribuutteja, jotka halutaan näkyville seuraavalla pyynnöllä. Käytännössä RedirectAttributes-olio tallentaa attribuutit sessioon, josta ne lisätään Model-olion attribuutteihin seuraavan pyynnön yhteydessä.
Pohditaan tilannetta, jossa luomme uutta Person-oliota. Kun henkilö on luotu, käyttäjä ohjataan sivulle, jossa on henkilön tiedot. Kun käyttäjä tulee sivulle ensimmäisen kerran, sivulla näytetään myös viesti "New person created!". Lisätään Person-luokalle attribuutti id, jota käytetään henkilön tunnistamiseen.
// pakkaus
import org.hibernate.validator.constraints.Email;
import org.hibernate.validator.constraints.Length;
import org.hibernate.validator.constraints.NotBlank;
public class Person {
private Long id;
@NotBlank
@Length(min = 11, max = 11)
private String socialSecurityNumber;
@NotBlank
@Length(min = 5, max = 30)
private String name;
@NotBlank
@Email
private String email;
// getterit ja setterit
Käytössämme on rajapinta PersonService, joka tarjoaa seuraavat metodit:
public interface PersonService {
Person create(Person registration);
Person read(Long id);
}
Rajapinnan toteutus injektoidaan valmiiksi kontrolleriin -- kontrollerin ei oikeastaan tarvitse tietää toteutuksesta sen enempää: palvelutaso on abstrahoitu kontrollerilta. Muokataan aiemmin käytössämme ollutta PersonController-luokan create metodia siten, että se saa parametrina RedirectAttributes-olion. Parametrina saatu Person-olio annetaan PersonService-palvelun metodille create, joka muun muassa asettaa oliolle yksilöivän tunnuksen ja (mahdollisesti) tallentaa sen esimerkiksi tietokantaan. Tämän jälkeen asetamme RedirectAttributes-oliolle kaksi attribuuttia.
Normaali attribuutti, joka lisätään metodilla addAttribute on käytössä tämän pyynnön loppuun asti. Alla olevassa esimerkissä lisäämme attribuutin id, jonka Spring myöhemmin asettaa osaksi osoitetta, johon käyttäjä ohjataan palautettavaan merkkijonooon. Tällöin pyyntö ohjautuu juuri luotua Person-oliota käsittelevälle sivulle. Toinen attribuutti, joka lisätään metodilla addFlashAttribute, on käytössä vain seuraavan pyynnön ajan. Attribuutti message asetetaan automaattisesti seuraavan pyynnön attribuutteihin.
// pakkaus ja importit
@Controller
public class PersonController {
@Autowired
private PersonService personService;
@RequestMapping(value = "person", method = RequestMethod.POST)
public String create(RedirectAttributes redirectAttributes,
@Valid @ModelAttribute(value="person") Person person,
BindingResult bindingResult) {
if(bindingResult.hasErrors()) {
return "form";
}
person = personService.create(person);
redirectAttributes.addAttribute("id", person.getId());
redirectAttributes.addFlashAttribute("message", "New person created!");
return "redirect:person/{id}";
}
// muut metodit
Nyt jos pyyntöä osoitteeseen person/{id} kuuntelee oma kontrollerimetodi, on sillä käytössä attribuutti messageensimmäisellä kerralla kun käyttäjä päätyy sivulle. Kontrollerimetodi, joka kuuntelee osoitetta person/{id} voi olla esimerkiksi seuraavanlainen.
// ...
@RequestMapping(value = "person/{personId}", method = RequestMethod.GET)
public String viewPerson(Model model, @PathVariable Long personId) {
Person person = personService.read(personId);
model.addAttribute("person", person);
return "person";
}
// ...
Itse sivu person.jsp voi näyttää esimerkiksi seuraavanlaiselta (huomaa mielikuvituksen puute):
Huomionarvoista tässä on se, että kun käyttäjä luo uuden Person olion, hänet ohjataan sivulle, joka näyttää käyttäjän tiedot. Sivun voi tallentaa kirjanmerkiksi, sillä sivu on aina olemassa. Kuitenkin ensimmäisellä kerralla käyttäjän tullessa sivulle, sivulla näkyy myös käyttäjäystävällinen viesti "New person created!".
Post/Redirect/Get
POST/Redirect/GET on yleinen web-suunnittelumalli, jonka avulla voidaan vältää osa toisteisista lomakkeiden lähetyksistä sekä helpottaa kirjanmerkkien käyttöä. Käytännössä ajatuksena on pyytää käyttäjä tekemään GET-pyyntö onnistuneen POST-pyynnön jälkeen. GET-pyynnössä palautetaan sivu, jossa näytetään muuttuneet tiedot, kun taas POST-pyynnöllä tehtiin pyyntö tiedon muuttamiseen.
Parannellaan tässä tehtävässä erään tilauspalvelun toimintaa.
Validointi
Tällä hetkellä käyttäjän syöttämiä tietoja ei validoida millään tavalla. Lisää sovellukseen tilauksen (Order) validointi seuraavasti:
Nimen (name) tulee olla vähintään 4 merkkiä ja enintään 30 merkkiä pitkä.
Osoitteen (address) tulee olla vähintään 4 merkkiä ja enintään 50 merkkiä pitkä.
Tilatut esineet (items) ei saa olla tyhjä.
Jos joku edelläolevista ehdoista ei täyty, näytä käyttäjälle lomake siten, että siinä näkyy virheviestit ja jo syötetyt tiedot. Käyttöliittymä on rakennettu puolestasi, joten sinun tarvitsee muokata vain luokkia OrderController ja Order. Huom! Kannattanee käyttää @NotEmpty-annotaatiota esineiden tyhjyyden tarkistamiseen.
Post, Redirect, Get
Muuta sovellusta siten, että lomakkeen lähetyksen onnistuessa käyttäjä ohjataan erilliseen osoitteeseen, jossa näkyy hänen juuri tekemänsä ostos. Käyttäjän tulee pystyä asettamaan osoite kirjanmerkiksi, eli sen tulee olla pysyvä. Kun käyttäjä ohjautuu sivulle ensimmäistä kertaa, sivulla tulee näkyä viesti Order placed!. Toteuta uudelleenohjaus käyttämällä RedirectAttributes luokkaa osana toteutusta: aseta attribuutiksi orderId luodun tilauksen id, sekä lisää pyyntöön flash-attribuutti message, joka sisältää viestin Order placed!. Joudut myös muokkaamaan metodin palauttamaa merkkijonoa sopivasti.
PUT ja DELETE HTML-lomakkeissa
HTML-lomakkeet tukevat tyypillisesti vain pyyntötyyppejä GET ja POST. Haluamme usein kuitenkin toteuttaa kontrollerin tarjoaman rajapinnan siten, että käytetyt metodit vastaavat todellista toiminnallisuutta. Esimerkiksi elementin poistaminen on hyvä toteuttaa DELETE-metodilla: tällöin saman toiminnallisuuden jakaminen myös erillisille palveluille on helpompaa.
Tyypillisesti sovelluskehykset tarjoavat tuen pyyntötyyppien muokkaukseen siten, että lomakkeisiin asetetaan pyynnön tyypin määrittelevä attribuutti. Tätä attribuuttia käytetään pyyntötyypin muokkaamiseen ennen sen päätymistä kontrollerille.
Springissä pyyntötyypin muuttaminen onnistuu Springin form-tägillä ja HiddenHttpMethodFilter-filtterillä. Käytännössä filtteri tulee käsittelemään kaikki Springille ohjautuvat pyynnöt, ja muuntamaan niiden pyyntötyypin tarvittaessa.
Kun filtteri on lisätty web.xml-tiedostoon konfiguroitu, voidaan Springin form-tägillä määriteltyjä lomakkeita muokata siten, että niissä käytetään PUT- tai DELETE-pyyntöjä. Normaalit GET- ja POST-pyynnöt toimivat kuten ennenkin. Esimerkiksi seuraavaa lomaketta voisi käyttää henkilön poistamiseen.
Huom! Kun luot lomakkeille kontrolleria, varmista että palautusarvot ovat kunnossa. Esimerkiksi DELETE-tyyppisen kutsun käsittelyn jälkeen käyttäjä tulee ohjata tekemään uusi GET-pyyntö.
Taking a REST
Tässä tehtävässä toteutetaan Unipalvelu, johon käyttäjä voi tallentaa tietoja nukkumisestaan. Tehtävässä halutaan harjoitella erityisesti REST-tyylisiä osoitteita ja pyyntöjä. Emme kuitenkaan vielä toteuta varsinaista rajapintaa vaan harjoittelemme osoitteita ja pyyntöjä tavallisilla HTML-näkymillä. Tehtävään on jo valmiiksi konfiguroitu web.xml tiedostoon HiddenHttpMethodFilter-filtteri, joka mahdollistaa DELETE-pyynnön.
Domain-luokka
Muokkaa pakkauksessa wad.rest.domain olevaa luokkaa Sleep niin, että se toteuttaa alla olevan rungon. Tee luokasta entiteetti ja määritä sille tietokantataulun nimi. Muista myös luoda getterit ja setterit attribuuteille.
import org.springframework.format.annotation.DateTimeFormat;
public class Sleep {
private Long id;
@DateTimeFormat(pattern = "d.M.y H.m")
private Date start;
@DateTimeFormat(pattern = "d.M.y H.m")
private Date end;
private String feeling;
}
@DateTimeFormat annotaatiolla Spring muuntaa tekstihahmon d.M.y H.m muotoisen merkkijonoesityksen päivämäärästä ja ajasta (kuten 23.9.2012 18.41) Date-olioksi. Voimme siis syöttää lomakkeessa merkkijonon, joka muutetaan suoraan Dateksi. Jotta @DateTimeFormat toimii, on pom.xmlään lisätty joda-time-riippuvuus.
Attribuuteista:
id - Automaattisesti generoituva Long-tyyppinen avain, käytä annotaatiota @GeneratedValue strategialla AUTO.
start - Käytä annotaatiota @Temporal tyypillä DATE. Haluamme myös validoida, ettei attribuutti voi olla null.
end - Kuten edeltävä attribuutti.
feeling - Halumme validoida, ettei attribuutti voi olla tyhjä tai null.
Muista myös nimetä jokaisen attribuutin tietokantataulun sarakkeiden nimet!
Repository-rajapinta
Tee entiteetille repository-rajapinta SleepRepository pakkaukseen wad.rest.repository. Rajapinnan tulee tuttuun tapaan periä Spring Data JPA:n rajapintaluokka CrudRepository siten, että tallennettava olio on tyyppiä Sleep ja avaimena on Long.
Palvelu
Haluamme nyt noudattaa kerrosarkkitehtuuria. Toteuta siis pakkaukseen wad.rest.service palveluluokka JpaSleepService, joka toteuttaa samassa pakkauksessa olevan rajapinnan SleepService. Toteuta rajapinnan määrittelemät metodit injektoimalla luokkaan @Autowired-annotaatiota käyttäen SleepRepositoryn toteuttava luokka. Injektoitavasta luokasta löytyy tarvittavat metodit JpaSleepServicen toteuttamiseen.
Muista määrittää luokan JpaSleepServicen metodeille @Transactional-annotaatiot. Määritä annotaatiolle myös boolean-tyyppiset parametrit readOnly sen mukaan muuttaako metodi tietokannassa olevaa tietoa vai ei.
Kontrollerit ja näkymät
Tehtävässä on valmiina jo yksi kontrolleri BaseController. Tämän sisältämä metodi getIndex kaappaa juuren (joka on edelleen /app/) osoitteen ja palauttaa näkymän index. Modeliin myös lisätään tyhjä Sleep-olio näkymään lisättävää lomaketta varten.
Muokkaa näkymää index.jsp. Lisää sinne Spring-lomake Sleep luokkaa varten. Lomakkeen commandName tulee olla sleep, action ohjaa polkuun /app/sleeps ja method on POST.
Lomakkeessa tulee olla Spring-lomakkeen tarjoamat tekstikentät poluille start, end ja feeling. Määrittele kentille myös id:t (start, end ja feeling vastaavasti). Lisää myös mahdolliset virhetulostukset kyseisille poluille.
Toteuta pakkaukseen wad.rest.controller kontrolleriluokka RESTSleepController. Luokan tulee toteuttaa samassa pakkauksessa sijaitseva rajapinta SleepController. Injektoi luokkaan @Autowired-annotaatiota käyttäen SleepServicenn toteuttava luokka. Luokan metodien tulee toimia seuraavanlaisesti:
public String create(Model model, Sleep sleep, BindingResult result)
Vastaa POST-pyyntöihin osoitteessa sleeps.
Parametrina saadaan lomakkeesta generoitu Sleep entiteetti. Käytä @ModelAttribute-annotaatiota ja varmista, että entiteetti on validi. @ModelAttributen arvona käytetään lomakkeeseen määriteltyä commandNamea.
Mikäli result oliossa on virheitä, lisää modeliin parametrissa saatu sleep entiteetti attribuutilla sleep. Tällöin metodin tulee palauttaa näkymä index virheiden näyttämistä varten.
Mikäli virheitä ei ole, metodi käyttää palvelukerroksesta tallentaakseen Sleep entiteetin tietokantaan ja ohjaa käyttäjän osoitteeseen /app/sleeps.
public String read(Model model, Long id)
Vastaa GET-pyyntöihin osoitteessa sleeps/{id}, polussa tulee haettavan Sleep entiteetin ID.
Hakee palvelukerroksesta vastaavan entiteetin ja lisää sen modeliin attribuutilla sleep.
Palauttaa näkymän sleep.
public String delete(Long id)
Vastaa DELETE-pyyntöihin osoitteessa sleeps/{id}, polussa tulee poistettavan Sleep entiteetin ID.
Käyttää palvelukerrosta kyseisen Sleep entiteetin poistamiseen.
Ohjaa käyttäjän osoitteeseen /app/sleeps.
public String list(Model model)
Vastaa GET-pyyntöihin osoitteessa sleeps.
Hakee palvelukerroksesta listan kaikista Sleep entiteeteistä ja lisää ne modeliin attribuutilla sleeps.
Palauttaa näkymän sleeps.
Muokkaa vielä näkymää sleep.jsp lisäämälle sinne Spring-lomake Sleep entiteetin poistoa varten. Lomakkeen tulee tehdä DELETE-pyyntö osoitteeseen /app/sleeps/{id}. Lomakkeessa ei tarvitse olla muuta kuin input submittausta varten.
Testaa nyt ohjelma vielä kokonaisuudessaan ja kun testit menevät läpi, lähetä sovellus TMC:lle.
HTTP on tilaton protokolla
HTTP on tilaton protokolla, eli se ei tarvitse jatkuvasti avoinna olevaa yhteyttä toimiakseen. Tämä tarkoittaa sitä, että HTTP ei osaa yhdistä samalta käyttäjältä tulevia pyyntöjä toisiinsa, jolloin jokainen tehty pyyntö käsitellään omana erillisenä pyyntönään. Käytännössä yhden web-sivustonkin hakeminen saattaa sisältää kymmeniä pyyntöjä, sillä jokaiseen sivuun liittyy joukko kuvia ja skriptitiedostoja, joista kukin on oma erillinen resurssinsa.
Vaikka HTTP on tilaton protokolla, on asiakkaan tunnistamiseen käytetty pitkään erilaisia kiertotapoja. Klassinen tapa kiertää HTTP:n tilattomuus on ollut säilyttää GET-muotoisessa osoitteessa parametreja, joiden perusteella asiakas voidaan identifioida palvelinsovelluksessa. Parametrien käyttö osoitteissa ei ole kuitenkaan ongelmatonta: osoitteessa olevia parametreja voi helposti muokata käsin, jolloin palvelinsovelluksesta saattaa löytyä tietoturva-aukkoja tai ei-toivottua käyttäytymistä.
Eräässä järjestelmässä verkkokaupan toiminnallisuus oli toteutettu siten, että GET-parametrina säilytettiin numeerista ostoskorin identifioivaa tunnusta. Käyttäjäkohtaisuus oli toteutettu palvelinpuolella siten, että tietyllä GET-parametrilla näytettiin aina tietyn käyttäjän ostoskori. Uusien tuotteiden lisääminen ostoskoriin onnistui helposti, sillä pyynnöissä oli aina mukana ostoskorin tunnistava GET-parametri. Ostoskorit oli valitettavasti identifioitu juoksevalla numerosarjalla. Henkilöllä 1 oli ostoskori 1, henkilöllä 2 ostoskori 2 jne.. Koska käytännössä kuka tahansa pääsi katsomaan kenen tahansa ostoskoria vain osoitteessa olevaa numeroa vaihtamalla, olivat ostoskorien sisällöt välillä hyvin mielenkiintoisia.
HTTP-protokollan tilattomuus ei pakota palvelinohjelmistoja tilattomuuteen. Palvelimella tilaa pidetään yllä jollain tietyllä tekniikalla, joka taas ei näy HTTP-protokollaan asti. Nykyään yleisin tekniikka tilattomuuden kiertämiseen on evästeiden käyttö.
HTTP on tilaton protokolla, eli käyttäjän toimintaa ja tilaa ei pysty pitämään yllä puhtaasti HTTP-yhteyden avulla. Käytännössä suurin osa verkkosovelluksista kuitenkin sisältää käyttäjäkohtaista toiminnallisuutta, jonka toteuttamiseen sovelluksella täytyy olla jonkinlainen tieto käyttäjästä ja käyttäjän tilasta. HTTP/1.1 tarjoaa mahdollisuuden tilallisten verkkosovellusten toteuttamiseen evästeiden (cookies) avulla.
Asettamalla käyttäjän tekemän pyynnön vastaukseen eväste, tulee käyttäjän jatkossa pyyntöä tehdessä aina palauttaa kyseinen eväste pyynnön otsaketietoina. Tämä tapahtuu automaattisesti selaimen toimesta. Evästeitä käytetään istuntojen (session) ylläpitämiseen: istuntojen avulla pidetään kirjaa käyttäjästä useampien pyyntöjen yli.
Evästeet toteutetaan otsakkeiden avulla. Kun käyttäjä tekee pyynnön palvelimelle, ja palvelimella halutaan asettaa käyttäjälle eväste, palauttaa palvelun vastauksen mukana otsakkeen Set-Cookie, jossa määritellään käyttäjäkohtainen evästetunnus. Set-Cookie voi olla esimerkiksi seuraavan näköinen:
Ylläoleva palvelimelta lähetetty vastaus ilmoittaa pyytää selainta tallettamaan evästeen. Selaimen tulee jatkossa lisätä eväste SESS57a5819a77579dfb1a1466ccceee22a0=0hr0aa2ogdfgkelogg jokaiseen helsinki.fi-osoitteeseen. Eväste on voimassa tunnin, eli tunnin kuluttua sen voi poistaa. Tarkempi syntaksi evästeen asettamiselle on seuraava:
Set-Cookie: nimi=arvo [; Comment=kommentti] [; Max-Age=elinaika sekunteina]
[; Expires=parasta ennen paiva] [; Path=polku tai polunosa jossa eväste voimassa]
[; Domain=palvelimen osoite (URL) tai osoitteen osa jossa eväste voimassa]
[; Secure (jos määritelty, eväste lähetetään vain salatun yhteyden kanssa)]
[; Version=evästeen versio]
Evästeet tallennetaan selaimen sisäiseen evästerekisteriin, josta niitä haetaan aina kun käyttäjä tekee kyselyn johonkin osoitteeseen. Evästeet lähetetään palvelimelle jokaisen viestin yhteydessä Cookie-otsakkeessa.
Evästeiden nimet ja arvot ovat yleensä monimutkaisia ja satunnaisesti luotuja niiden yksilöllisyyden takaamiseksi. Samaan osoitteeseen voi liittyä myös useampia evästeitä. Yleisesti ottaen evästeet ovat sekä hyödyllisiä että haitallisia: niiden avulla voidaan luoda yksiöityjä käyttökokemuksia tarjoavia sovelluksia, mutta niitä voidaan käyttää myös käyttäjien seurantaan ympäri verkkoa.
Kekseliästä
Painamalla F12 tai valitsemalla Tools -> Developer tools, pääset tutkimaan sivun lataamiseen ja sisältöön liittyvää statistiikkaa. Lisäneuvoja löytyy Google Developers -sivustolta.
Avaa developer tools, ja mene osoitteeseen http://www.hs.fi. Valitsemalla developer toolsien välilehden Resources, löydät valikon erilaisista sivuun liittyvistä resursseista. Avaa Cookies ja valitse vaihtoehto www.hs.fi. Kuinka moni palvelu pitää sinusta kirjaa kun menet Helsingin sanomien sivuille?
Sovellusten testaaminen
Kuten ohjelmistotuotannossa yleensä, myös web-palvelinohjelmistoja rakennettaessa niiden testaaminen on oleellista. Testit voi karkeasti jakaa kolmeen osaan: yksikkötestaus, integraatiotestaus ja järjestelmätestaus. Yksikkötestauksessa testataan sovellukseen kuuluvia yksittäisiä komponentteja ja varmistetaan että niiden tarjoamat rajapinnat toimivat kuten pitäisi. Integraatiotestauksessa testataan että komponentit toimivat yhdessä kuten niiden pitäisi, ja järjestelmätestauksessa varmistetaan, että järjestelmä toimii vaatimusten mukaan järjestelmän käyttäjille tarjotun rajapinnan (esim. selain) kautta.
Yksikkötestaus
Yksikkötestauksella tarkoitetaan lähdekoodiin kuuluvien yksittäisten osien testaamista. Termi yksikkö viittaa ohjelman pienimpiin mahdollisiin testattaviin toiminnallisuuksiin, kuten olion tarjoamiin metodeihin. Single responsibility principlen mukaisesti haluamme pilkkoa ohjelmiston pieniin yksittäisen vastuun omaaviin yksikköihin, joiden testaaminen on helppoa: niillä on vain yksi vastuu. Testaus tapahtuu yleensä testausohjelmistokehyksen avulla, jolloin luodut testit voidaan suorittaa automaattisesti. Yleisin Javalla käytettävä testauskehys on JUnit, jonka saa käyttöön lisäämällä siihen liittyvän riippuvuuden pom.xml-tiedostoon.
Yksittäisen riippuvuuden määre scope kertoo milloin riippuvuutta tarvitaan. Määrittelemällä scope-elementin arvoksi test on riippuvuudet käytössä vain testejä ajettaessa. Uusia testiluokkia voi luoda NetBeansissa valitsemalla New -> Other -> JUnit -> JUnit Test. Tämän jälkeen NetBeans kysyy testiluokalle nimeä ja pakkausta. Huomaa että lähdekoodit ja testikoodit päätyvät erillisiin kansioihin -- juurin näin sen pitääkin olla. Kun testiluokka on luotu, on projektin rakenne kutakuinkin seuraavanlainen.
.
|-- pom.xml
`-- src
|-- main
| |-- java
| | `-- wad
| | `-- ... oman projektin koodit
| |-- resources
| | `-- ... resurssit
| `-- webapp
| `-- ... jsp-tiedostot ja konfiguraatiotiedostot
`-- test
`-- java
`-- wad
`-- ... testikoodit!
Vaikka tällä kurssilla huomattava osa testeistä on ollut valmiina, usein ohjelmistoja kehitettäessä testejä kirjoitetaan samaan aikaan sovellusta kehitettäessä, esimerkiksi TDD-menetelmää käyttäen.
TDD-sykli tarkemmin: (1) Luo uusi testi joka testaa ei-olemassaolevaa toiminnallisuutta. (2) Aja olemassaolevat testit ja varmista että uusi testi ei mene läpi. Jos testi menee läpi testi on viallinen tai toivottu toiminnallisuus on jo toteutettu. (3) Kirjoita uutta toiminnallisuutta varten yksinkertaisin mahdollinen toteutus, joka läpäisee testin. Uuden toiminnallisuuden tulee olla toteutettu siten, että se läpäisee juuri kirjoitetun testin – ei muuta. (4) Suorita olemassaolevat testit ja varmista että ne menevät läpi. Jos testit eivät mene läpi, tarkista uuden toiminnallisuuden aiheuttamat muutokset. (6) Refaktoroi eli siisti koodia. Esimerkiksi toistuva koodi tulee siirtää omaan metodiinsa. (7) Palaa kohtaan (1)
Yksinkertainen Laskin-esimerkki (ohjelmistojen mallintaminen, kesä 2011):
Ensimmäinen testi: Halutaan että Laskin-olion voi luoda
import org.junit.Test;
public class LaskinTest {
@Test
public void testLaskimenLuonti() {
Laskin laskin = new Laskin();
}
}
Luodaan toiminnallisuus joka läpäisee testin
public class Laskin {
}
Testit ajetaan ja kaikki menevät läpi. Huomaa että testiluokan tulee olla samannimisessä pakkauksessa (joskin eri sijainnissa) kuin testattavan luokan. Tällöin testiluokka ei tarvitse erillistä import-käskyä testattavalle luokalle. Seuraava testi: Halutaan että laskin voi laskea laskun 1+1
import org.junit.Assert;
import org.junit.Test;
public class LaskinTest {
@Test
public void testLaskimenLuonti() {
Laskin laskin = new Laskin();
}
@Test
public void testYksiPlusYksi() {
Laskin laskin = new Laskin();
Assert.assertEquals(2, laskin.plus(1, 1));
}
}
Toteutetaan toiminnallisuus joka läpäisee testin. Huomaa että toiminnallisuuden tulee vain toteuttaa testin vaatima toiminnallisuus. Yksi plus yksi testille riittää hyvin toteutus joka palauttaa aina arvon 2.
public class Laskin {
public int plus(int ekaluku, int tokaluku) {
return 2;
}
}
Kun testit suoritetaan, ne menevät läpi. Seuraava testi: Halutaan että laskin voi laskea laskun 1+2
import org.junit.Assert;
import org.junit.Test;
public class LaskinTest {
@Test
public void testLaskimenLuonti() {
Laskin laskin = new Laskin();
}
@Test
public void testYksiPlusYksi() {
Laskin laskin = new Laskin();
Assert.assertEquals(2, laskin.plus(1, 1));
}
@Test
public void testYksiPlusKaksi() {
Laskin laskin = new Laskin();
Assert.assertEquals(3, laskin.plus(1, 2));
}
}
Toteutetaan toiminnallisuus joka läpäisee uuden testin. Jos plusmetodin toiminnallisuutta muutetaan siten, että se palauttaa aina luvun kolme, aikaisempi testi ei enää mene läpi. On mahdollista toteuttaa toiminnallisuus myös ehtolauseen avulla ("jos ekaluku on yksi, ja tokaluku on kaksi, palauta 3") – mutta myöhemmin joutuisimme refaktoroimaan koodin testit läpäiseväksi.
public class Laskin {
public int plus(int ekaluku, int tokaluku) {
return ekaluku + tokaluku;
}
}
Kun testit suoritetaan, ne menevät läpi – ja sykli jatkuu kunnes toiminnallisuus on valmis.
Testit ovat erittäin oleellisia sovelluksen ylläpitovaiheessa. Käytännössä uuden sovelluskehittäjän liittyessä ohjelmistotiimiin, on olemassaolevan sovelluksen muokkaus erittäin vaikeaa ilman testejä. Yksi muutos voi rikkoa useampia toiminnallisuuksia, joiden rikkoutumisesta olemassaolevat testit ilmoittavat.
Integraatiotestaus
Spring tarjoaa JUnit-kirjastolle tuen, jonka avulla saamme Autowired-annotaatiot toimimaan. Lisätään Spring-test -riippuvuus projektimme pom.xml-tiedostoon.
Springin oliokontekstia käyttävät yksikkötestit tarvitsevat kaksi annotaatiota alkuun. Annotaatio @RunWith(SpringJUnit4ClassRunner.class) kertoo että käytämme Springiä yksikkötestien ajamiseen ja annotaatiolle @ContextConfiguration annetaan konfiguraation sijainti. Testiluokan alku, johon injektoidaan automaattisesti MyService-rajapinnan toteuttava komponentti, näyttää seuraavalta.
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("file:src/main/webapp/WEB-INF/spring/spring-base.xml")
public class MyTest {
@Autowired
private MyService myService;
// ... testit jne
Käynnistämällä Springin osana testejä, saamme käyttöömme oliokontekstin, jonka avulla voimme asettaa testattavat oliot testiluokkiin testaamista varten. Testattavien olioiden riippuvuudet asetetaan myös automaattisesti, eli jos rajapinnan MyService toteuttava luokka riippuu jostain toisesta komponentista, on se myös automaattisesti asetettu.
Järjestelmätestaus
Järjestelmätestauksessa on tarkoitus varmistaa, että järjestelmä toimii toivotulla tavalla. Järjestelmää testataan ns. black-box -tyyppisesti, eli saman rajapinnan kautta, kuin mitä sen loppukäyttäjät käyttävät. Järjestelmän sisäisestä tilasta ei ole myöskään tietoa.
Järjestelmätestaukseen on monenlaisia työkaluja, joista eräs selainohjelmistojen testausta varten tarkoitettu väline on Selenium. Selenium on web-testauskehys, joka antaa sovelluskehittäjälle mahdollisuuden käydä läpi sovelluksen käyttöliittymää ohjelmallisesti samalla varmistaen että sivuilla on toivotut asiat. Se simuloi myös Javascript-komponenttien toiminnallisuutta, minkä avulla käyttöliittymän testaus helpottuu huomattavasti. Selenium on erittäin hyödyllinen esimerkiksi käyttötapausten läpikäynnissä. Saamme Seleniumin käyttöön lisäämällä sen osaksi pom.xml-tiedostoa.
Ajatellaan loppukäyttäjän haluamaa toiminnallisuutta "Käyttäjä voi ilmoittautua oppitunnille". Järjestelmä tarjoaa yksittäisen sivun, johon voi lisätä käyttäjän tiedot. Oletetaan, että sivulla on lomakekenttä nimeltä "name". Kun kenttään asetetaan arvo "Bob" ja kenttään liittyvä lomake lähetetään, tulee sivulla olla teksti "Ilmoittautuminen onnistui!".
public class SeleniumTest {
private WebDriver driver;
private String baseAddress;
@Before
public void setUp() {
this.driver = new HtmlUnitDriver();
this.baseAddress = "...";
}
@Test
public void onceBobSubmittedElementAgeIsAvailable() {
// haetaan haluttu osoite (aiemmin määritelty muuttuja)
driver.get(osoite);
// haetaan kenttä nimeltä tunnus
WebElement element = driver.findElement(By.name("name"));
// asetetaan kenttään arvo
element.sendKeys("Bob");
// lähetetään lomake
element.submit();
Assert.assertTrue(driver.getPageSource().contains("Ilmoittautuminen onnistui!"));
}
// ...
Yllä käytämme HtmlUnitDriver-oliota html-sivun läpikäyntiin. Haemme ensin määritellyn osoitteen, eli surffaamme haluttuun osoitteeseen. Haemme osoitteesta saadusta lähdekoodista kentän name-attribuutilla "name", ja lisäämme kenttään arvon "Bob". Tämän jälkeen lomake lähetetään. Kun lomake on lähetetty, haetaan sivun lähdekoodista tekstiä "Ilmoittautuminen onnistui!". Jos tekstiä ei löydy (eli palautettu arvo on null), testi epäonnistuu.
Selenium
Tehtäväpohjan mukana tulee testiluokka BeerSeleniumTest, joka alustaa Seleniumin WebDriver-olion. Tehtävänäsi on tässä lisätä luokalle kaksi testimetodia. Tässä tehtävässä ei ole paikallisia testejä. Huom! Seuraa ohjeita tarkasti. Jos olet varma että testisi ovat oikein, mutta TMC:ltä tuleva vastaus ilmoittaa virheen, lähetä vastauksesi TMC:lle vielä muutaman kerran -- testien testaus tapahtuu erillisten säikeiden avulla, jotka voivat toimia epädeterministisesti.
Kun testaat sovellusta, varmista että käytät sovelluksen juuriosoitetta testaamiseen -- testaamiseen käytetty jetty toimii (yleensä omassa tapauksessamme) osoitteessa http://localhost:8090/. Glassfishille tyypillinen erillinen sovelluksen juuriosoite http://localhost:8090/W5-W5E06... ei siis ole käytössä.
Jos testit eivät suoritu loppuun, voi olla että Jettyllä ei ole tarpeeksi muistia. Voit tällöin suorittaa testit esimerkiksi komentoriviltä ja lisätä Mavenille lisää muistia ennen testien suorittamista.
MAVEN_OPTS='-Xmx512m -Xms512m'
export MAVEN_OPTS
mvn test
Huom! Suosittelemme että tutustut tässä välissä Mozilla Firefoxille saatavilla olevaan Selenium IDE-projektiin.
submitAndVerify
Toteuta testimetodi public void submitAndVerify(), joka ensin menee sovelluksen sivulle ja tarkistaa ettei sivuilla ole olutta "Up Up Down Down Left Right Left Right BA Select". Tämän jälkeen olut "Up Up Down Down Left Right Left Right BA Select" lisätään kenttään, jonka tunnus on name, ja lomake lähetetään. Tämän jälkeen sinun tulee varmistaa, että olut on olemassa.
Toteuta testimetodi public void submitThreeAndVerify(), joka ensin menee sovelluksen sivulle ja tarkastaa ettei sivuilla ole oluita "Gargamel Ale", "Crazy Ivan" ja "Hoptimus Prime". Tämän jälkeen oluet "Gargamel Ale", "Crazy Ivan" ja "Hoptimus Prime" lisätään sivulle sivun lomaketta käyttäen. Lopulta testi testaa että lisätyt kolme olutta ovat list-sivulla.
Springin tarjoama spring-test-mvc tarjoaa tuen myös selainohjelmistojen black-box -testaamiseen ilman tarvetta erilliselle palvelimelle. Integraatiotestaamiseen liittyvässä osiossa käytettyä konfiguraatiota voi käyttää myös web-sovelluksen kontekstin injektoimiseen testille, jonka pohjalta voimme luoda pyyntöjä simuloivan MockMvc-olion. Web-sovelluksen kontekstin injektoimiseen tarvitsemme käytännössä edellisen esimerkin lisäksi @WebAppConfiguration-annotaation.
Alla oleva esimerkki käynnistää spring-web sovelluksen, ja tekee GET-pyynnön osoitteeseen message. Lopulta vastauksesta tarkistetaan, että se sisältää viestin "Awesome".
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("file:src/main/webapp/WEB-INF/spring/spring-base.xml")
@WebAppConfiguration
public class BlackboxTest {
@Resource
private WebApplicationContext waco;
private MockMvc mockMvc;
@Before
public void setup() {
mockMvc = webAppContextSetup(waco).build();
}
@Test
public void messageContainsAwesome() throws Exception {
MvcResult result = mockMvc.perform(get("/message"))
.andExpect(status().isOk())
.andExpect(content().contentTypeCompatibleWith(MediaType.APPLICATION_JSON))
.andReturn();
String content = result.getResponse().getContentAsString();
Assert.assertTrue(content.contains("Awesome"));
}
// ...
Lisäämällä käyttöön Jackson-kirjaston tarjoaman ObjectMapper-luokan, voimme testata myös JSON-dataa palauttavia ja vastaanottavia rajapintoja.
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("file:src/main/webapp/WEB-INF/spring/spring-base.xml")
@WebAppConfiguration
public class BlackboxTest {
@Resource
private WebApplicationContext waco;
private MockMvc mockMvc;
private ObjectMapper mapper;
@Before
public void setup() {
mockMvc = webAppContextSetup(waco).build();
mapper = new ObjectMapper();
}
@Test
public void afterPostObjectCanBeFound() throws Exception {
MyObject obj = createObject();
MyObject other = getObject(obj.getId());
Assert.assertEquals(obj.getName(), other.getName());
}
private MyObject getObject(String id) throws Exception {
MvcResult result = mockMvc.perform(get("/objects/{id}", id))
.andExpect(status().isOk())
.andExpect(content().contentTypeCompatibleWith(MediaType.APPLICATION_JSON))
.andReturn();
String content = result.getResponse().getContentAsString();
return mapper.readValue(content, new TypeReference<MyObject>() {
});
}
private MyObject createObject() throws Exception {
MvcResult result = mockMvc.perform(post("/objects"))
.andExpect(status().isOk())
.andExpect(content().contentTypeCompatibleWith(MediaType.APPLICATION_JSON))
.andReturn();
return mapper.readValue(result.getResponse().getContentAsString(), new TypeReference<MyObject>() {
});
}
}
Kehitys, Integraatio, QA, Tuotanto
Kun web-sovelluksia kehitetään suuremmassa ryhmässä, sovellus sijaitsee tyypillisesti neljässä eri paikassa.
Jokaisella ohjelmistokehittäjällä on oma "hiekkalaatikko", jossa koodiin voi tehdä muutoksia vaikuttamatta muiden tekemään työhön. Jokaisella ohjelmistokehittäjällä on yleensä samat tai samankaltaiset työkalut (ohjelmointiympäristö, ...), mikä helpottaa muiden kehittäjien auttamista. Tyypillisesti tehtävät on jaettu pieniksi erillisiksi kokonaisuuksiksi, joiden toteuttaminen kestää muutamia päiviä. Kun yksittäinen tehtävä on valmis, tehtävään liittyvä koodi ja muutokset lähetetään integraatiopalvelimelle esim. git-versionhallintaa käyttäen.
Integraatiopalvelimen tehtävänä on yhdistää ohjelmistokehitystiimin lähdekoodit ja suorittaa niihin liittyvät testit jokaisen muutoksen yhteydessä. Integraatiopalvelin kuuntelee käytännössä versionhallintajärjestelmässä tapahtuvia muutoksia, ja hakee uusimman lähdekoodiversion muutoksen yhteydessä. Integraatiopalvelimella on käytössä osajoukko tuotantopalvelimen käyttämästä datasta validointitarkoituksiin.
QA-ympäristö (Staging-palvelin) on lähes identtinen ympäristö tuotantoympäristöön verrattuna. QA-ympäristöön kopioidaan ajoittain tuotantoympäristön data, ja se toimii viimeisenä testaus- ja validointipaikkana (Quality assurance) ennen tuotantoon siirtoa. QA-ympäristöä käytetään myös demo- ja harjoitteluympäristönä. Kun QA-ympäristössä oleva sovellus on päätetty toimivaksi, siirretään sovellus tuotantoympäristöön.
Tuotantoympäristö voi olla yksittäinen palvelin, tai se saattaa olla joukko palvelimia, joihin uusin muutos propagoidaan hiljalleen. Tuotantoympäristö on tyypillisesti erillään muista ympäristöistä mahdollisten virheiden minimoimiseksi.
Integraatiopalvelin ja Continuous Integration
Jatkuvassa integroinnissa (Continuous integration) jokainen ohjelmistoprojektin jäsen lisää päivittäiset muutoksensa olemassaolevaan kokonaisuuteen.
Jatkuvaa integrointia seuraten ohjelmistokehittäjä hakee kehityksen alla olevan version versionhallinnasta aloittaessaan työn. Hän toteuttaa uuden pienen ominaisuuden testeineen, testaten uutta toiminnallisuutta jatkuvasti. Kun ohjelmistokehittäjä on saanut muutoksen tehtyä, ja kaikki testit menevät läpi hänen paikallisella työasemalla, hän lähettää muutokset versionhallintaan. Kun versionhallintaan tulee muutos, jatkuvaa integrointia suorittava työkalu hakee uusimman version ja suorittaa sille sekä yksikkö- että integraatiotestit.
Testejä sekä paikallisella kehityskoneella että erillisellä integraatiokoneella ajettaessa ohjelmistotiimi mahdollisesti huomaa virheet, jotka ovat piilossa kehittäjän paikallisen konfiguraation johdosta. Kehittäjä ei aina ota koko ohjelmistoa omalle koneelleen -- ohjelmisto voi koostua useista komponenteista -- jolloin kaikkien vaikutusten testaaminen paikallisesti on mahdotonta. Jos testit eivät mene läpi integraatiokoneella, korjataan muutokset mahdollisimman nopeasti.
Hyvin rakennetussa sovelluksessa ympäristön vaihtaminen ei aiheuta muutoksia sovelluksen lähdekoodiin, vaan sovellusten ympäristöstä toiseen siirtäminen tapahtuu erilaisten profiilien avulla. Luodaan seuraavaksi sovellus, jossa on erillinen tuotanto- ja kehitysympäristö. Kehitysympäristössä käytössä on muistiin ladattava H2-tietokanta, tuotantoympäristössä PostgreSQL-tietokantaa (oletetaan että pom.xml:ssä) on molempien tarvitsemat riippuvuudet.
Luodaan ensin persistence.xml-tiedostoon kaksi erillistä persistence-unit-konfiguraatiota. Toinen on tuotannolle, toinen kehitysympäristölle. Oleellisin ero konfiguraatioissa on se, että tuotantoympäristössä tietokantatauluja ei tuhota aina sovelluksen käynnistyessä.
Muokataan tämän jälkeen sovelluksen tietokantakonfiguraatiota. Konfiguraatioon määritellään profiilit "production" ja "dev,default", jotka sisältävät profiiliin liittyvän konfiguraation. Profiili "dev,default" sisältää käytännössä kaksi profiilia: profiili "dev" ja oletusprofiili "default". Profiilissa "production" asetetaan muuttujan persistenceUnitName arvoksi persistenceUnitProduction, luetaan konfiguraatiotiedosto production.properties, ja luodaan konfiguraatiotiedostosta luettujen parametrien pohjalta DataSource-olio. Profiilissa "dev,default" asetetaan muuttujan persistenceUnitName arvoksi persistenceUnitDev, luetaan konfiguraatiotiedosto development.properties, ja luodaan muistiin ladattava tietokanta.
Nyt kun sovellusta käynnistetään ilman erillisiä konfiguraatioita, on sovelluksessa käytössä muistiin ladattava tietokanta sekä tiedostosta development.properties ladatut konfiguraatiot. Konfiguraatioparametrit voi injektoida myös suoraan sovellukseen.
// ..
@Controller
public class DefaultController {
@Value("${deployment.location}")
private String location;
// ...
Käytännössä profiilien hallinta kannattaa toteuttaa esimerkiksi niin, että integraatio-, qa- ja tuotantoympäristöön määritellään ympäristömuuttuja, joka kertoo käytettävän profiilin. Springiä käytettäessä ympäristömuuttuja on SPRING_PROFILES_ACTIVE tai spring.profiles.active.
Ympäristömuuttujan asetus tapahtuu *nix-koneilla export-komennolla.
export SPRING_PROFILES_ACTIVE=production
Kun Springille on asetettu profiili, voidaan testiluokille määritellä myös käytettävä profiili annotaation ActiveProfiles avulla. Alla olevassa esimerkissä testiluokan testit suoritetaan siten, että käytössä on profiiliin "dev" liittyvä konfiguraatio.
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("file:src/main/webapp/WEB-INF/spring/spring-base.xml")
@WebAppConfiguration
@ActiveProfiles("dev")
public class BlackboxTest {
@Resource
private WebApplicationContext waco;
private MockMvc mockMvc;
private ObjectMapper mapper;
@Before
public void setup() {
mockMvc = webAppContextSetup(waco).build();
mapper = new ObjectMapper();
}
// ...
Yhteenveto paljon käyttämistämme annotaatioista
@Controller - kertoo Springille, että annotaatiolla merkityssä luokassa on metodeja, jotka käsittelevät HTTP-pyyntöjä.
@RequestMapping kertoo osoitteen ja datatyypit, joita annotaatiolla merkitty metodi käsittelee. Metodille voidaan antaa polku, metodin tyyppi (POST, GET, ..), sekä datatyypit (consumes, produces). Datatyyppiä määriteltäessä metodi asetetaan käsittelemään vain määriteltyjä datatyyppejä, jolloin metodi ei käsittele muita pyyntöjä.
@PathVariable ottaa @RequestMapping-annotaation määrittelemästä polusta aaltosuluilla merkityn alueen, ja asettaa alueen arvon @PathVariable-annotaatiota seuraavaan muuttujaan.
@RequestMapping(value="persons/{id}", method=RequestMethod.GET)
public String getPerson(@PathVariable Long id) {
// ...
@RequestParam ottaa pyynnöstä (joko osoitteesta .../osoite?parametri=arvo tai pyynnön rungosta) määrätyn nimisen parametrin arvon, ja asettaa sen annotaatiota seuraavaan muuttujaan. Esimerkiksi seuraava metodi käsittelisi esimerkiksi pyyntöjä, jotka ovat muodossa ../persons?id=42.
@RequestMapping(value="persons", method=RequestMethod.GET)
public String getPerson(@RequestParam Long id) {
// ...
@ModelAttribute ottaa pyynnöstä (joko osoitteesta .../osoite?parametri=arvo¶metri2=arvo2 tai pyynnön rungosta) kaikki parametrit, ja yrittää asettaa ne annotaatiota seuraavaan muuttujaan, joka voi olla esimerkiksi olio.
@RequestBody ottaa koko pyynnön rungon, ja asettaa sen annotaatiota seuraavaan muuttujaan. Jos projektiin on määritelty mvc:annotation-driven-konfiguraatio pyynnöstä, käytetään pyynnön muuntamisessa käytössä olevia komponentteja (esim. JSON-datan muuntaminen olioksi).
@ResponseBody asettaa annotoidun metodin palauttaman vastauksen selaimelle lähetettävän vastauksen runkoon. Muuttaa oliot olemassaolevien komponenttien mukaan esimerkiksi JSON-muotoon.
Tämän hetken trendi: Selainohjelmistot
Tällä hetkellä selainohjelmistoissa näkyy trendi, missä selainohjelmistot toteutetaan itsenäisinä JavaScript-komponenteista koostuvina sovelluksina, jotka tekevät pyyntöjä taustalla olevalle palvelimelle, jonka tehtävänä on (esimerkiksi) vastaanottaa ja palauttaa JSON-muotoista dataa. Sen sijaan, että pyyntöjen ja näkymien valinta tapahtuisi palvelimella, näytettävän datan ja näkymän päättäminen tehdään näissä ohjelmistoissa selainohjelmistossa. Perinteisemmät web-sivut, missä linkkejä klikattaessa palvelin päättää sivun, mihin siirrytään, eivät ole kuitenkaan vielä katoamassa mihinkään: oikeastaan selainpuolella käydään tällä hetkellä vastaavaa kilpailua, kuin mitä palvelinpuolen komponenteissa oli noin ~8 vuotta sitten.
Seuraavassa tehtäväsarjassa toteutetaan palvelintoiminnallisuus valmiille selainpuolen sovellukselle.
Tökkel
Tässä tehtävässä toteutetaan palvelinpuolen REST-rajapinta pienelle selaimessa toimivalle tehtävänhallintasovellukselle. Kuten huomaat ylläolevasta kuvakaappauksesta, sovelluksen käyttöliittymä muistuttaa jo enemmän nykyisiä web-sovelluksia pelkän mustan tekstin ja valkoisen taustan sijaan.
Sovelluksessa on kaksi eri näkymää: projektit (projects) ja tehtävät (tasks). Tehtäviä voi luoda tehtävälistaan täysin ilman projekteja tai luokitella niitä eri projektien alle. Tehtävän voi merkitä aloitetuksi, jolloin selain laskee sekunteja aloitusajankohdasta. Tehtävän lopettamisen jälkeen listauksessa näkyy tehtävän aloitus- ja lopetusaika.
Sovelluksen käyttöliittymä toimii siten, että käyttöliittymän JavaScript-koodi kommunikoi suoraan palvelimen REST-rajapinnan kanssa JSON-muotoisilla viesteillä. REST-rajapinnan ja JSON-tietomuodon käyttö onkin yleistä nykyaikaisissa web-sovelluksissa juuri sen takia, että JavaScript-koodilla on helppo käyttää tällaista rajapintaa. Lisäksi selaimessa näytettävää sivua ei koskaan vaihdeta tai ladata uudelleen -- selaimen näyttämän sivun sisältöä ainoastaan muutetaan käyttäjän tekemien toimintojen perusteella.
Tehtäväpohjassa on valmiina ainoastaan JavaScriptillä ja HTML:llä tehty käyttöliittymä, jota ei tarvitse muuttaa. Loppu tehtävä on jätetty avoimeksi siten, että palvelinpuolen tulee toteuttaa käyttöliittymän vaatima REST-rajapinta projektien ja tehtävien hallinnointiin.
Huom! Tämän tehtävän testit tarkistavat ainoastaan REST-rajapinnan toiminnan, joten (kuten jo useassa aiemmassakin tehtävässä) tehtävään kirjoitettua koodia ei tarkisteta mitenkään. Joudut siis käynnistämään sovelluksen itse ja kokeilemaan käyttöliittymää, jotta voit todeta mitkä ominaisuudet toimivat oikein ja saada tarvittaessa selkeitä virheilmoituksia poikkeustilanteista.
JavaScript- ja HTML-pohjaiset käyttöliittymät
Tökkel-sovelluksen käyttöliittymää ei suinkaan ole toteutettu kokonaan itse, vaan siinä käytetään lukuisia valmiita komponentteja:
jQuery - toimii apuvälineenä sivun sisällön muuttamiseen
Backbone.js - hallinnoi ohjelman logiikkaa, siirtymiä näkymien välillä ja kommunikaatiota palvelimen kanssa
Twitter Bootstrap - Twitterin kehittämä kirjasto, joka tarjoaa valmiita käyttöliittymäkomponentteja, kuten nappeja ja valikoita
Mustache.js - mahdollistaa selainpohjaisen käyttöliitymän kokoamisen lyhyistä HTML-kuvauskielen paloista (template)
Projektien hallinta
Tehtäväpohjassa on valmiina luokka Project, joka sisältää kuvauksen projektista. Valmis Spring-konfiguraatio etsii Spring Data JPA:n repository-luokkia pakkauksesta wad.tokkel.repositories.
Toteuta projektien hallintaan tarvittavat luokat, joiden avulla voit tarjota seuraavan REST-rajapinnan projektien käsittelyyn:
POST /app/projects luo uuden projektin JSON-datan pohjalta ja palauttaa luodun projektin tiedot JSON-muodossa. Asettaa projektille sen luontiajan.
GET /app/projects palauttaa listan projekteista JSON-muodossa.
GET /app/projects/{id} palauttaa yksittäisen projektin tiedot id-avaimen perusteella JSON-muodossa.
DELETE /app/projects/{id} poistaa id-avaimen mukaisen projektin ja palauttaa poistetun projektin tiedot JSON-muodossa
Uusi projekti luodaan JSON-muotoisella pyynnöllä esimerkiksi näin:
{"name": "Wadillinen projekti"}
Sovelluksen palauttama ja tallentama projekti näyttää esimerkiksi tältä:
POST /app/projects/{id}/tasks luo palvelimelle lähetetyn JSON-muotoisen datan pohjalta uuden tehtävän id-avaimen mukaiseen projektiin ja palauttaa luodun tehtävän tiedot JSON-muotoisena esityksenä
GET /app/projects/{id}/tasks palauttaa JSON-muotoisen listan kaikista tehtävistä, jotka liittyvät id-avaimen mukaisesta projektista
GET /app/projects/{projectId}/tasks/{taskId} palauttaa yksittäisen tehtävän JSON-muotoisen esityksen taskId-avaimen perusteella
DELETE /app/projects/{projectId}/tasks/{taskId} poistaa taskId-avaimen mukaisen tehtävän ja palauttaa sen JSON-muotoisen esityksen
Uusi tehtävä luodaan haluttuun projektiin JSON-muotoisella pyynnöllä esimerkiksi näin:
{
"description": "Muista nukkua!"
}
Huom! Käyttöliittymän toteutuksen takia REST-rajapintaan täytyy tehdä yksi poikkeusratkaisu, jolla tehtäviä tulee voida liittää projekteihin myös seuraavalla tavalla:
POST /app/tasks luo uuden tehtävän JSON-pyynnössä olevan projectId-avaimen mukaiseen projektiin ja palauttaa luodun tehtävän tiedot JSON-muotoisena
Tässä poikkeustapauksessa talletettavan tehtävän projektin avain tulee aina toimittaa JSON-pyynnössä kuten alla:
Sovelluksen tulee siis lukea mahdollisesti annettu projectId-attribuutti ja yhdistää tehtävä projectId-avaimen mukaiseen projektiin. Jos (kuten aiemmissa tehtävissä on neuvottu) käytät Springin @RequestBody-annotaatiota vastaanottamaan JSON-muotoisen pyynnön tiedot suoraan entiteettiolioon, asetetaan projektin avain paikalleen automaattisesti, jos entiteetillä on getter- ja setter-metodit id-avaimelle. Tällöin myös palvelimen vaste tulee automaattisesti sisältämään projektin avaimen. Tarkoitus ei ole kuitenkaan tallettaa avainta erikseen tietokantaan, koska viittaus projektiin tulee tehdä käyttämällä JPA-annotaatioita. Jotta tiettyä oliomuuttujaa ei talletettaisi tietokantaan, voidaan se merkitä @Transient-annotaatiolla:
public class Task {
// ...
@Transient
private Integer projectId;
public Integer getProjectId() {
return projectId;
}
public void setProjectId(Integer projectId) {
this.projectId = projectId;
}
// ...
}
Sovelluksen tallettama tehtävä näyttää esimerkiksi tältä (luotiin se kummalla tahansa tavalla yllämainituista):
Huom! Tiettyyn projektiin kuuluvan tehtävän JSON-esityksen tulee aina sisältääprojectId-attribuutti, myös tehtävälistausta tai yksittäisiä tehtäviä haettaessa.
Kokeile nyt sovelluksen käyttöliittymässä lisätä tehtäviä projekteihin!
Tehtävän aloittaminen ja lopettaminen
Lisätään sovellukseen lopuksi mahdollisuus merkitä tehtävä aloitetuksi ja lopetetuksi.
PUT /app/tasks/{taskId} aloittaa tai lopettaa taskId-avaimen mukaisen tehtävän riippuen pyynnön sisällöstä. Jos JSON-muotoisessa pyynnössä saadussa datassa on kenttä start, ja sillä arvo "true", kyseinen tehtävä tulee aloittaa. Vastaavasti, jos pyynnöstä löytyy arvo stop, ja sillä arvo "true", kyseinen tehtävä tulee lopettaa.
PUT /app/projects/{projectId}/tasks/{taskId} aloittaa tai lopettaa taskId-avaimen mukaisen tehtävän riippuen pyynnön sisällöstä, kts. yllä (projektin avainta ei ole pakko käyttää!)
Aiemmin luotu tehtävä aloitetaan JSON-muotoisella PUT-pyynnöllä esimerkiksi osoitteeseen /app/tasks/6:
Huom! Voit toteuttaa start- ja stop-pyyntöjen vastaanottamisen vastaavasti kuin tehtävän edellisen kohdan projectId-avaimen väliaikaisen talletuksen käyttämällä @Transient-annotaatiota entiteetissä.
Testaa lopuksi tehtävien aloitusta ja lopettamista sovelluksen käyttöliittymässä!
le end of wk4
Minkälaisia pyyntöjä kontrolleri ottaa vastaan, jos sen RequestMapping-annotaatiossa on attribuutti consumes arvolla "application/json". Minkälaisia pyyntöjä kontrolleri ei tällöin ota vastaan?
Minkälaisia vastauksia kontrolleri lähettää, jos sen RequestMapping-annotaatiossa on attribuutti produces arvolla "application/json". Minkälaista sisältöä kontrolleri ei tällöin esimerkiksi lähetä?
Mitä annotaatio @ModelAttribute tarkoittaa?
Mitä annotaatio @Valid tarkoittaa? Mitä tapahtuu jos annotaatiot @Valid ja @ModelAttribute asettaa kontrollerimetodin parametreiksi seuraavassa järjestyksessä: "@ModelAttribute @Valid"?
Mitä eroa on yksikkötestauksella, integraatiotestauksella, ja järjestelmätestauksella? Milloin näitä käytetään?
Mitä ovat tietokantatransaktiot, ja mitä ne tekevät? Milloin ja miksi niitä käytetään?
Minkälaiset sovellukset voivat käyttää JSON-dataa tuottavaa palvelinohjelmistoa? Keksi ainakin muutama esimerkki!
Käyttäjien määrän kasvaessa palveluiden tulee pystyä skaalautua mukana. Palveluiden ja sovellusten skaalautumiseen on käytännössä kaksi vaihtoehtoa: resurssien kasvattaminen (vertikaalinen skaalautuminen), sekä palvelinmäärän kasvattaminen (horisontaalinen skaalautuminen). Resurssien kasvattamiseen sisältyy lisämuistin hankinta, algoritmien optimointi ym, kun taas palvelinmäärän kasvattamisessa sovelluskehittäjän tulee luoda mahdollisuus pyyntöjen jakamiseen palvelinten välillä.
Sovellukset eivät skaalaannu lineaarisesti, ja skaalautumiseen liittyy paljon muutakin kuin resurssien lisääminen. Jos yksiytimisellä prosessorilla varustettu palvelin pystyy käsittelemään sata pyyntöä sekunnissa, emme voi laskea, että kahdeksanytiminen prosessori pystyy käsittelemään kahdeksansataa pyyntöä sekunnissa. Skaalautuminen ei ole vain palvelun tehon lisäämistä. Aivan kuten raketin lisääminen autoon vauhdin lisäämiseksi ei pakosti tuota hyvää lopputulosta, yksittäinen tehokas komponentti sovelluksessa ei takaa sovelluksen tehokkuutta.
Palvelinpuolen välimuisti (Caching)
Sovelluksen suorituskykyä ja toiminnallisuutta mitattaessa oleelliseen rooliin nousee sovelluksen profilointi. Esimerkiksi NetBeans sisältää valmiin sovelluksen profiloijan, jonka avulla voi tutkia eri sovelluksen osissa käytettyä aikaa. Profiloijan käyttäminen yhdessä kuormitustestaustyökalun kanssa (esim. Apache JMeter tai The Grinder) auttaa kyselyiden simuloinnissa, jolloin ongelmakohdat löytyvät helposti.
Kuormitustestauksessa tulee ottaa huomioon sovellukseen tulevien kyselyiden todellinen profiili. Sovelluksen profilointituloksissa on huomattavia eroja riippuen tehtyjen pyyntöjen tyypistä. Jos 99% sovellukseen kohdistuvista pyynnöistä on GET-tyyppisiä, ei kuormitustestaustyökalun tule testata 50% POST, 50% GET -tyyppisellä profiililla.
Tyypillisissä web-palvelinohjelmistoissa huomattava osa kyselyistä on GET-tyyppisiä pyyntöjä. GET-tyyppiset pyynnöt eivät muokkaa palvelimella olevaa dataa, vaan pyytävät tietoa. Esimerkiksi tietokannasta dataa hakevat GET-tyyppiset pyynnöt luovat yhteyden tietokantasovellukseen, josta data haetaan. Sovellusten skaalautumista pohtiva sovelluskehittäjä alkaakin miettimään että eikö uudestaan ja uudestaan haettavaa dataa voisi tallentaa välimuistiin.
Ovela ohjelmoija hyödyntää Javan valmista kalustoa välimuistin toteuttamiseen. Esimerkiksi Javan luokka LinkedHashMap tarjoaa mainion pohjan oman välimuistin toteutukseen. Luokan metodia removeEldestEntry kutsutaan aina uuttaa arvoa lisättäessä. Käytännössä välimuistin voi luoda perimällä luokan LinkedHashMap, ja korvaamalla metodin removeEldestEntry siten, että huomioon otetaan välimuistille määriteltävä parametrin cacheSize, joka määrittelee välimuistin koon.
public class SimpleCache<K, V> extends LinkedHashMap<K, V> {
private int cacheSize;
public SimpleCache(int cacheSize) {
super();
this.cacheSize = cacheSize;
}
@Override
public boolean removeEldestEntry(Map.Entry eldest) {
return size() > cacheSize;
}
}
Yllä olevan toteutuksen voi lisätä osaksi palveluluokkien metodeja. Pohditaan seuraavaa BeerService-rajapintaa, joka on tullut jo tutuksi. Luodaan sille seuraavaksi erillinen palvelu, joka käyttää Spring Data JPA:ta. Repository-luokkaa ei näytetä erikseen.
public class JpaBeerService implements BeerService {
@Autowired
private BeerRepository beerRepository;
private SimpleCache<Long, Beer> beerCache;
public JpaBeerService() {
// luodaan cache, johon voi varastoida 1000 oluen tiedot
this.beerCache = new SimpleCache<Long, Beer>(1000);
}
@Override
@Transactional(readOnly = false)
public Beer create(Beer beer) {
// tallennetaan cacheen vasta kun olut haetaan
return beerRepository.save(beer);
}
@Override
@Transactional(readOnly = true)
public Beer read(Long identifier) {
// jos olut on cachessa, palautetaan se sieltä
if(beerCache.containsKey(identifier)) {
return beerCache.get(identifier);
}
// muuten haetaan olut tietokannasta, ja tallennetaan se
// cacheen
Beer beer = beerRepository.findOne(identifier);
beerCache.put(identifier, beer);
return beer;
}
// ...
Melko ovelaa, eikö?
Ovelaa kyllä, muttei fiksua. Keksimme vaihteeksi taas pyörän uudestaan.
EHcache
Maailmalla on huomattava määrä valmiita cache-toteutuksia, joista yksi on EHcache. Vaikka tässä tutustumme EHcacheen vain pikaisesti, tarjoaa se toiminnallisuuden muun muassa hajautettujen välimuistien toteutukseen ja ns. big data -mittakaavan sovellusten tukemiseen.
Konfiguroidaan EHcache Springille. Spring tarjoaa erilaisten välimuistitoteutusten abstraktion osana sen context-support-komponenttia. Lisätään EHcache sekä Springin context-support pom.xml-tiedostoomme.
Tämän lisäksi EHCache tarvitsee oman konfiguraation, jossa sille määritellään mm. muistiin tallennettavien elementtien määrä, strategia elementtien poistamiseen (LRU=least recently used), automaattinen konfiguraation ajoittainen lataus (cache-strategiaa voi muuttaa lennosta) ym. Luodaan konfiguraatio kansioon src/main/resources, eli Other Sources, ja asetetaan sen nimeksi ehcache.xml.
Määrittelemme konfiguraatiossa käyttöön välimuistin, jonka nimi on "books".
Tarkempaa tietoa EHCachen konfiguraatiosta löytyy mm. EHcachen omasta dokumentaatiosta.
Kun käytettävän välimuistin konfiguraatio on lisätty, voimme lisätä sen myös Springin käyttöön. Luodaan erillinen cache.xml-tiedosto, johon tiedostosta spring-base.xml viitataan. Tiedoston spring-base.xml tiedoston sisältö tulee olemaan nyt seuraavanlainen.
Springin välimuistikonfiguraatioon liittyy oikean välimuistitoteutuksen valinta (EhCache), sekä sen konfiguraation lataaminen. Rivillä <cache:annotation-driven cache-manager="cacheManager" /> kerromme, että cachet konfiguroidaan annotaatioiden avulla.
Kun olemme konfiguroineet välimuistin, voimme toteuttaa välimuistin hieman eritavalla kuin aiemmin. Spring tarjoaa käyttöömme mm. @Cacheable- ja @CacheEvict-annotaatiot, joiden avulla voidaan määritellä välimuistin käyttö ja tyhjennys metodeille. Yllä olevan JpaBeerService-luokan toteutus hoituisi nyt seuraavasti.
Käytännössä annotaatio @Cacheable luo metodille read proxy-metodin, joka ensin tarkistaa onko haettavaa tulosta välimuistissa. Välimuistina käytetään välimuistia nimeltä "beers", joka on aiemmin konfiguroitu tiedostossa ehcache.xml. Jos tulos on välimuistissa, palautetaan se sieltä, muuten tulos haetaan tietokannasta ja tallennetaan välimuistiin.
Välimuistitoteutuksen vastuulla ei ole pitää kirjaa tietokantaan tehtävistä muutoksista, jolloin välimuistin tyhjentäminen muutoksen yhteydessä on sovelluskehittäjän vastuulla. Dataa muuttavat metodit tulee annotoida sopivasti annotaatiolla @CacheEvict, jotta välimuistista poistetaan muuttuneet tiedot. Yllä olevassa esimerkissä koko välimuisti tyhjennetään kun uusi olut lisätään tietokantaan.
Hyödyllistä tässä lähestymistavassa on se, että nyt käytettävää välimuistia voi muuttaa esimerkiksi konfiguraatioprofiilien avulla. Aiempi ohjelmallisesti tehty välimuisti ei skaalaudu, kun taas valmista cache-komponenttia käyttävä sovellus skaalautuu konfiguraatiosta riippuen. Alla on esimerkki cache.xml-konfiguraatiosta, jossa tuotantoympäristössä käytetään EHCachea, ja kehityskäytössä Springin tarjoamaa hajautustauluun perustuvaa välimuistia.
Kirjojen hakuun erikoistuva sovelluksesi on viimeisintä huutoa markkinoilla. Eräs kirjojen hakutoiminnallisuutta käyttävä yritys toivoo sovellukseen kuitenkin lisää tehoa. Haastattelujen pohjalta tiedät, että heillä on muutamia tyypillisiä kyselyjä, jotka toistuvat usein. Lisää kirjojen hakuun välimuistitoiminnallisuus, jonka avulla tehostat yleisiä hakuja.
Sinun ei tarvitse tässä välittää siitä, että välimuistitoiminnallisuuden saa rikottua melko helposti (esimerkiksi syöttämällä hakuun äärettömän määrän a-kirjaimia). Tehtävässä ei ole erillisiä testejä; palauta se kun olet saanut välimuistitoiminnallisuuden toimimaan, ja huomaat että toistuvat kyselyt nopeutuvat.
Oletuksena annotaatio @Cacheable luo välimuistiavaimen kaikista metodin parametreista. Avaimen voi myös määritellä käsin. Alla olevassa esimerkissä käytetään parametria #name välimuistin avaimena.
Yllä olevassa esimerkissä vain parametria name käytetään datan tallentamiseen välimuistiin, jolloin parametrista imNotUsed ei välitetä. Lisää tietoa erilaisista avainkombinaatioista löytyy Springin dokumentaation cache-osiosta.
Cached ItemStorage
Myös ItemStoragella on hieman tehokkuusongelmia. Palvelun kyselyprofiili on juuri lukemamme kannalta erittäin positiivinen, sillä noin 98.8% palveluun tehtävistä kyselyistä on GET-tyyppisiä. Lisää tässä tehtävässä GET-tyyppisiin metodeihin cache, ja dataa päivittäviin metodeihin cachen tyhjentäminen. Varmista myös että käytät oikeannimista cachea (tutki esim. ehcache.xml-tiedostoa).
Palvelinmäärän kasvattaminen
Käytännössä skaalautumisesta puhuttaessa puhutaan horisontaalisesta skaalautumisesta, jossa käyttöön hankitaan esimerkiksi lisää palvelimia. Vertikaalinen skaalautumisen harkinta on mahdollista tietyissä tapauksissa, esimerkiksi tietokantapalvelimen ja -kyselyiden toimintaa suunniteltaessa, mutta yleisesti ottaen horisontaalinen skaalautuminen on kustannustehokkaampaa. (vrt. kahden miestyökuukauden käyttö algoritmin optimointiin, joka aiheuttaa algoritmin 10% tehoparannuksen, vs. ylimääräisen palvelimen hankkiminen, josta saa saman hyödyn.)
Pyyntöjen määrän kasvaessa yksinkertainen ratkaisu on palvelinmäärän eli käytössä olevan raudan kasvattaminen. Tällöin pyyntöjen jakaminen palvelinten kesken hoidetaan erillisellä kuormantasaajalla (load balancer), joka ohjaa pyyntöjä palvelimille.
Jos sovellukseen ei liity tilaa (esimerkiksi käyttäjän tunnistaminen tai ostoskori), kuormantasaaja voi ohjata pyyntöjä käytössä oleville palvelimille round-robin -tekniikalla. Jos sovellukseen liittyy tila, tulee tietyn asiakkaan tekemät pyynnöt ohjata aina samalle palvelimelle. Tämän voi toteuttaa esimerkiksi siten, että kuormantasaaja lisää pyyntöön evästeen, jonka avulla käyttäjä identifioidaan ja ohjataan oikealle palvelimelle. Tätä lähestymistapaa kutsutaan usein termillä (sticky session).
Pelkkä palvelinmäärän kasvattaminen ja kuormantasaus ei kuitenkaan ole aina tarpeeksi. Kuormantasaus helpottaa verkon kuormaa, mutta ei ota kantaa palvelinten kuormaan. Jos yksittäinen palvelin käsittelee pitkään kestävää laskentaintensiivistä kyselyä, voi kuormantasaaja ohjata tälle palvelimelle lisää kyselyjä "koska eihän se ole vähään aikaan saanut mitään töitä". Käytännössä tällöin entisestään paljon laskentaa tekevä palvelimen saa lisää kuormaa. On kuitenkin mahdollista käyttää kuormantasaajaa, joka lisäksi pitää kirjaa palvelinten tilasta, mutta käytännössä kuorma vaihtuu usein hyvin nopeasti, ja reagointi ei aina ole nopeaa.
Parempi ratkaisu palvelinmäärän kasvattamiselle on palvelinmäärän kasvattaminen ja sovelluksen suunnittelu siten, että laskentaintensiiviset operaatiot käsitellään erillisillä palvelimilla. Tällöin käytetään käytännössä erillistä laskentaklusteria aikaa vievien laskentaoperaatioiden käsittelyyn, jolloin käyttäjän pyyntöjä kuuntelevan palvelimen kuorma pysyy alhaisena.
Riippuen pyyntöjen määrästä, palvelinkonfiguraatio voidaan toteuttaa jopa siten, että staattiset tiedostot (esim. kuvat) löytyvät erillisiltä palvelimilta, GET-pyynnöt käsitellään asiakkaan pyyntöjä vastaanottavilla palvelimilla, ja datan muokkaamista tai prosessointia vaativat kyselyt (esim POST) ohjataan asiakkaan pyyntöjä vastaanottavien palvelinten toimesta laskentaklusterille.
Rajoitettu määrä samanaikaisia pyyntöjä osoitetta kohden
Staattisten resurssien kuten kuvien ja tyylitiedostojen hajauttaminen eri palvelimille on oikeastaan fiksua. HTTP 1.1-spesifikaation yhteyksiin liittyvässä osissa suositellaan tiettyyn osoitteeseen tehtävien samanaikaisten pyyntöjen määrän rajoittamista kahteen.
Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. A proxy SHOULD use up to 2*N connections to another server or proxy, where N is the number of simultaneously active users. These guidelines are intended to improve HTTP response times and avoid congestion.
Käytännössä suurin osa selaimista tekee enemmän kuin 2 kyselyä kerrallaan samaan osoitteeseen, esimerkiksi Google Chromessa raja on kuudessa. Jos web-sivusto sisältää paljon erilaisia staattisita resursseja, ja ne sijaitsevat kaikki samalla palvelimella, voidaan tällöin Google Chromella hakea maksimissaan kuutta resurssia kerrallaan. Toisaalta, jos resurssit jaetaan useamman sijainnin kesken, ei tätä rajoitetta ole.
Pilvipalvelut
Pilvipalvelut ovat verkossa toimivia palveluita. Pilvipalveluissa maksetaan vain käytetyistä resursseista -- sovelluksesta (SaaS, Software as a Service), alustasta (PaaS, Platform as a Service) tai laskentakapasiteetista (IaaS, Infrastructure as a Service). Pilvipalveluille ominaista on skaalautuvuus, palveluita käytetään vain kun on tarve. Jos käyttäjiä on paljon, käytössä olevien resurssien määrää voi dynaamisesti lisätä -- jos käyttäjiä on vähän, resurssien määrää voidaan laskea.
Sovellusalustaa palveluna (PaaS, Platform as a Service) tarjoavat yritykset mahdollistavat järjestelmän nopeamman kehittämisen -- sovelluskehittäjän ei tarvitse välittää alustasta sillä se on jo valmiina. Kustannusten arviointi on helpompaa sillä pilvipalveluiden laskutus tapahtuu käytön mukaan -- sovelluskehittäjä voi lisätä oman ylläpitokurstannuksen. Sovellusalustat piilottavat taustalla olevan infrastruktuurin, jolloin sovelluskehittäjän ei tarvitse välittää taustalla toimivasta palvelusta. Osa PaaS-tarjoajista toimii IaaS-tarjoajien tarjoamien palveluiden päällä: Esimerkiksi kohta tutuksi tuleva Heroku pyörii Amazonin päällä.
Strato
Havaintopaikkojen ja säähavaintojen lisäys ja listaus.
Tämä tehtävä on avoin tehtävä jossa saat itse suunnitella huomattavan osan ohjelman sisäisestä rakenteesta. Osa sovelluksen toiminnallisuudesta on ohjelmoitu valmiiksi. Valmiina on mm. käyttöliittymä (jsp-sivut), domain-objektit, ja osa kontrollereiden toiminnallisuudesta. Myös ensimmäiseen osaan tarvittavat palveluluokat ja repository-luokat ovat valmiina.
Käyttöliittymään on määritelty EL-kielellä attribuutit, joita käyttöliittymän tulee näyttää. Tehtäväpohjassa on myös valmis konfiguraatio spring-projektille.
Tehtävästä on mahdollista saada yhteensä 4 pistettä.
Luo tehtävässä sovellus, joka toimii kuten osoitteessa http://rocky-woodland-4307.herokuapp.com oleva sovellus (koska sovellus sammutetaan silloin kun sitä ei käytetä, saattaa olla että joudut odottamaan hetken sen käynnistymistä). Sovelluksessasi ei tarvitse olla XSS-tarkastusta.
Huom! Viestijonojen tai erillisten REST-rajapintaa käyttävien palveluiden käyttäminen ei liene tarpeellista tehtävässä.
Pisteytys:
+ 1p: Havaintopisteiden (ObservationPoint) lisääminen ja näyttäminen onnistuu.
Havaintopisteiden hallintasivulle tulee päästä aloitussivulla olevan linkin ("Observation points") kautta. Kun uusi havaintopiste on lisätty, se näytetään Observation points-linkin avaamalla sivulla. Käytä havaintopisteiden sivuna points.jsp-sivua.
+ 1p: Havaintojen (Observation) lisääminen havaintopisteisiin ja niiden näyttäminen onnistuu.
Havaintojen lisäyssivulle tulee päästä aloitussivulla olevan linkin ("Observations") kautta. Kun uusi havainto on lisätty, se näytetään Observation-linkin avaamalla sivulla. Käytä havaintojen sivuna observations.jsp-sivua.
+ 2p: Havaintojen sivuttaminen. Tällä hetkellä kaikki havainnot näytetään samalla sivulla. Olisi kuitenkin hyvä, että havainnot olisi sivutettu, jolloin sivulla näytetään vain tietty määrä havaintoja kerrallaan. Toteuta sovellukseen sivutus siten, että havaintoja näytetään kerrallaan maksimissaan 5, ja havainnot ovat järjestetty lisäysajan (timestamp) mukaan laskevasti (DESC).
JSP-sivulla observations.jsp on valmiina käyttöliittymän tarvitsema toiminnallisuus sivutukseen. Jotta sivutus toimisi, sinun tulee lisätä pyyntöön sivujen kokonaismäärää kuvaava attribuutti totalPages, nykyistä sivunumeroa kuvaava attribuutti pageNumber, sekä tietenkin kyseisellä sivulla näkyvät havainnot. Tarvitset myös pyynnöstä parametrin pageNumber, joka kuvaa käyttäjän haluamaa sivunumeroa.
Seuraavasta koodinpätkästä ja Spring Data JPA:sta saattaa olla hyötyä, googlettamalla löydät varmasti lisää apua.
public Page<Observation> listObservations(Integer pageNumber, Integer pageSize) {
PageRequest request = new PageRequest(pageNumber - 1, pageSize,
Sort.Direction.DESC, "timestamp");
return observationRepository.findAll(request);
}
Sovellus Herokuun!
Tässä esitellään askeleet ylläolevan sovelluksen siirtämiseen Herokuun. Jotta onnistut, sinun tulee rekisteröityä osoitteessa https://api.heroku.com/signup ja asentaa Heroku-työvälineet koneellesi. Työvälineet löytyy osoitteesta https://toolbelt.heroku.com/.
Jotta sovellus toimisi Herokussa, tulee sitä muokata hieman. Ensimmäinen askel on maven-dependency-plugin-liitännäisen lisääminen pom.xml-tiedostoon. Heroku luo liitännäisen avulla sovelluksesta käynnistettävän ohjelman. Käytännössä pom.xml-tiedostoon tulee lisätä seuraavat rivit plugins-elementin sisälle.
Koska käytämme jo Jettyä testien ajamiseen, tulee meidän myös muokata aiempaa konfiguraatiota. Parameterisoidaan ensin Jettyn käyttämä portti, jolloin sen voi asettaa ulkoisesti.
<name>W5E03.Strato</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<jetty.port>8090</jetty.port> <!-- uusi rivi -->
</properties>
Jonka jälkeen muutamme jetty-maven-plugin konfiguraatiota siten, että käytämme porttiparametria ja lisäämme mahdollisuuden palvelimen sulkemiseen ulkoisesti.
Nyt heroku osaa luoda sovelluksestamme komentoriviltä käynnistettävän version. Tämän lisäksi sovelluksen juurikansioon tulee luoda tiedosto Procfile, joka sisältää sovelluksen käynnistämiseen tarvittavan komennon. Käytännössä sovellusta herokuun lisättäessä sovellus ensin paketoidaan herokun toimesta mvn package-komennolla, jonka jälkeen tiedoston Procfile-sisältö suoritetaan. Alla olevalla konfiguraatiolla käynnistetään Java-tyyppinen web-sovellus, jolle annetaan parametreina käytettävä profiili sekä Herokun valmiit java-konfiguraatiot ja sovelluksen portti.
Kun sovelluksen konfiguraatio on valmis, lisätään se seuraavaksi herokuun. Oletamme tässä että olet sovelluksen juurikansiossa (tiedosto pom.xml on samassa kansiossa), ja että olet asentanut heroku-toolbeltin koneellesi. Oletamme myös, että käytössäsi on *nix-järjestelmä. Kirjaudutaan ensin heroku-palveluun, ja lisätään herokuun ssh-avain.
sovelluksen-nimi$ heroku login
Enter your Heroku credentials.
Email: käyttäjätunnus (sähköpostiosoite)
Password (typing will be hidden): salasana
Authentication successful.
sovelluksen-nimi$ heroku keys:add
Tämän jälkeen suoritetaan komento mvn clean, joka poistaa target-kansion.
Tämän jälkeen sovellus siirretään herokuun, ja heroku alkaa käynnistämään sitä aiemmin automaattisesti luotuun osoitteeseen. Kun käynnistyminen onnistuu, sovellus on nähtävillä luodussa osoitteessa.
Jos sovelluksen polkua haluaa muuttaa, voi sen tehdä herokun hallintakäyttöliittymästä. Kirjaudu herokuun, valitse Apps -> sovellus -> Settings. Voit muuttaa sovelluksen nimeä vaihtamalla name-kohdassa olevan nimen ja klikkaamalla rename. Jos nimen vaihtaminen onnistuu (nimi ei esim. ole varattu), siirtää heroku sovelluksen uuteen paikkaan. Jos nimeksi valitaan esim high-five, tulee projektikansion .git/config -tiedostoa muokata siten, että se heroku-repo käyttää oikeaa osoitetta. Ylläolevassa esimerkissä config-tiedoston sisältö on aluksi seuraavanlainen.
Kun sovellus nimetään uudestaan, siirtyy myös sen osoite. Esimerkiksi high-five-sovelluksen osoite muuttuu muotoon git@heroku.com:high-five.git. Muunnetaan konfiguraatiota soveltuvasti.
Nyt voimme lisätä muutoksia herokuun. Muutokset käynnistävät palvelimen automaattisesti uudestaan, jolloin uusin versio on aina näkyvillä loppukäyttäjälle.
Ilman jettyä tarvitsevia testejä koko build-konfiguraatiomme voisi olla seuraava.
Lisää edellisessä tehtävässä tehty Strato-sovellus Herokuun (tai halutessasi toiseen pilvipalveluun). Kun palvelu toimii Herokussa (tai valitsemassasi pilvipalvelussa), lisää palvelun osoite tehtävän index.jsp-tiedostoon ja palauta tehtävä TMC:lle.
Skaalautuminen pilvessä
Pilvipalveluiden käyttäminen mahdollistaa sovelluksen skaalautumisen tarpeen mukaan. Kun sovellus on hyvin aktiivisessa käytössä, voidaan siitä luoda useampia kopioita. Toisaalta, jos sovelluksen käyttö pienenee, voidaan käytössä olevia kopioita vähentää. Tällä hetkellä pilvipalveluilla ei ole yhtenäistä skaalautumismallia; osa palveluista lisää palvelimia automaattisesti kuorman kasvaessa, osa taas olettaa että käyttäjä hoitaa skaalautumisen.
Kun pilvipalvelu huomaa resurssien lisätarpeen, se käynnistää uusia sovellusta pyörittäviä palvelimia. Käytännössä uusien palvelimien käynnistyksen tulee olla helppoa ja selkeästi määriteltyä, esimerkiksi Herokulla uuden sovelluksen käynnistämisen vaativat komennot on määritelty erilliseen Procfile-nimiseen tiedostoon, jonka pohjalta uusia palvelimia käynnistetään. Kun uusi palvelin käynnistetään, lisätään se automaattisesti sovellukseen liittyvälle (ohjelmistopohjaiselle) reitittimelle, joka alkaa ohjaamaan pyyntöjä myös uudelle palvelimelle. Reititin tarjotaan käytännössä aina pilvipalvelun puolesta.
Jos pyyntöjen määrä palvelulle vähenee, voidaan käynnissä olevia palvelimia ajaa alas. Esimerkiksi Heroku sammuttaa ylimääräisiä palvelimia jos niille ei ole ollut tarvetta viimeisen tunnin aikana. Maksullisissa pilvipalveluissa yksi palvelin on yleensä aina päällä, jolloin vasteajat ovat aina nopeita. Ilmaiset pilvipalvelut sammuttavat tyypillisesti viimeisimmätkin palvelimet jos pyyntöjä ei tule vähään aikaan. Tällöin palvelin käynnistetään vain tarpeen vaatiessa.
Useamman palvelimen pyörittäminen nostaa palvelun vikasietoisuutta. Käytännössä pilvipalveluissa palvelimet pyörivät erillisissa fyysisissä sijainneissa (joista meillä ei ole käytännössä tietoa), jolloin vikatapaukset tietyssä koneessa eivät vaikuta koko sovelluksen toimintaan.
Pilvipalvelut eivät ota kantaa sovelluksen sisäiseen rakenteeseen. Esimerkiksi sovelluksen arkkitehtuuria ei muuteta viestijonoja käyttäväksi tarvittaessa. Sovelluksen arkkitehtuurisuunnittelu on aina sovelluskehittäjän vastuulla. Jos palvelimia käynnistetään paljon sen takia, että sovelluksen suunnittelija ei ole ottanut huomioon erilaisia sovelluksen tarpeita (esim. raskaan prosessoinnin hoitaminen erillisellä palvelulla), tulee pilvipalvelun käyttämisen kustannukset myös olemaan korkeammat sillä palvelimia käynnistetään niiden kuorman perusteella. Raskas prosessointi kannattaa toteuttaa erillisellä palvelulla siten, että prosessointiin erikoistunut palvelu hakee työt erillisestä töitä varastoivasta viestijonosta.
Tähän asti toteuttamissamme sovelluksissa pyynnön suorittaminen on tapahtunut kutakuinkin seuraavasti:
Pyyntö lähetetään palvelimelle
Palvelin vastaanottaa pyynnön ja ohjaa pyynnön oikealle kontrollerille
Kontrolleri vastaanottaa pyynnön ja ohjaa pyynnön oikealle palvelulle
Palvelu vastaanottaa pyynnön, suorittaa pyyntöön liittyvät operaatiot mahdollisesti muiden palveluiden kanssa, ja palauttaa vastauksen kontrollerille
Kontrolleri ohjaa pyynnön sopivalle näkymälle, joka palautetaan käyttäjälle.
Tietokantaoperaation tai palvelukutsun valmistumisen odottaminen ei ole aina tarpeen. Jos sovelluksemme suorittaa esimerkiksi raskaampaa laskentaa, tai tekee pitkiä tietokantaoperaatioita joiden tuloksia käyttäjän ei tarvitse nähdä, kannattaa pyyntö suorittaa asynkronisesti.
Asynkroniset metodikutsut tapahtuvat seuraavasti:
Pyyntö lähetetään palvelimelle
Palvelin vastaanottaa pyynnön ja ohjaa pyynnön oikealle kontrollerille
Kontrolleri vastaanottaa pyynnön ja ohjaa pyynnön oikealle palvelulle
Palvelu asettaa pyynnön suoritusjonoon ja palvelukutsusta palataan heti (palvelun tyyppi on void)
Kontrolleri ohjaa pyynnön sopivalle näkymälle, joka palautetaan käyttäjälle.
Ohjelmistokehykset toteuttavat asynkroniset metodikutsut luomalla palvelukutsusta erillinen säie, jossa pyyntöä käsitellään. Käytännössä sovelluskehykset, tai sovelluskehyksiä varten kehitetyt komponentit tarjoavat tähän tuen.
Lisätään seuraavaksi Spring-sovellukseen tuki asynkronisten metodikutsujen käyttöön. Käytännössä tarvitsemme Lisää ensin Springin konfiguraatiotiedostoon nimiavaruusmäärittely spring-task-nimiavaruudelle.
Kun nimiavaruus on konfiguroitu, lisätään konfiguraatiotiedostoon rivi, jolla sanomme että tehtävien hallinta hoidetaan annotaatioiden avulla.
<task:annotation-driven />
Kun konfiguraatio on paikallaan, voimme toteuttaa palvelutason metodeja asynkronisesti. Jotta palvelutason metodi olisi asynkroninen, sen tulee olla void-tyyppinen, sekä sillä tulee olla annotaatio @Async.
Tutkitaan kahta erilaista tapausta, jossa tallennetaan Item-olioita. Item-olion sisäinen muoto ei ole niin tärkeä. Ensimmäisessä tapauksessa Item-olion tunnuksen generoinnin vastuu on tietokannalla. Kun tietokanta on generoinut tunnuksen ja tallentanut olion tietokantaan, palautetaan siihen viite.
Palvelutason metodi create palauttaa ylläolevassa tapauksessa viitteen luotavaan olioon. Tarkastellaan toisenlaista tapausta, jossa Item-oliolle generoidaan viite kontrollerimetodissa. Palvelutason metodi on void-tyyppinen, eikä tallennuksen tapahtumisen ajankohta ole niin oleellinen.
@RequestMapping(method = RequestMethod.POST, value = "item")
public String create(RedirectAttributes redirectAttributes,
@Valid @ModelAttribute Item item, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
return "form";
}
item.setId(UUID.randomUUID().toString());
itemService.create(item);
redirectAttributes.addAttribute("itemId", item.getId());
return "redirect:item/{itemId}";
}
Kahden yllä esitetyn kontrollerimetodin ero on hyvin pieni, mutta vain toisessa palvelutason toteutus asynkronisesti on mahdollista (Spring tukee myös rinnakkaisohjelmoinnissa erittäin käteviä Future-tyyppisiä palautusarvoja).
Oletetaan että ItemService-olion metodi create on void-tyyppinen, ja näyttää seuraavalta:
public void create(Item item) {
itemRepository.save(item);
}
Metodin muuttaminen asynkroniseksi vaatii @Async-annotaation.
@Async
public void create(Item item) {
itemRepository.save(item);
}
Voila! Käytännössä asynkroniset metodikutsut toteutetaan asettamalla metodikutsu suoritusjonoon, josta se suoritetaan kun sovelluksella on siihen mahdollisuus. Yleensä tämä tapahtuu erittäin nopeasti.
Heavy Calculations
Kumpulan kampuksella sijaitseva sisennyksen tutkimusyksikkö SIIT on kehittänyt tutkimussiivessään mullistavan merkkijonoalgoritmin ja haluavat demonstroida sen toiminnallisuutta web-sivulla. Muutaman yrityksen jälkeen he ovat huomanneet, että algoritmi on hieman hitaahko. Tehtävänäsi on tässä tehtävässä muuttaa demoamiseen käytettävää sovellusta siten, että algoritmin prosessointi tehdään taustalla. Älä kuitenkaan muuta itse algoritmin toimintaa.
Lisää sovellukselle konfiguraatio asynkronisten metodien suorittamiseen ohjelmallisesti, sekä muuta algoritmin sisältävää palveluluokkaa InMemoryDataProcessor siten, että prosessoinnin sisältävä metodi sendForProcessing suoritetaan asynkronisesti. Älä muuta metodin sendForProcessing sisältöä!
Toistuvat metodikutsut
Springin task-toiminnallisuuden avulla voimme toteuttaa myös palveluita, joihin kytketyt toiminnallisuudet suoritetaan tietyin aikavälein. Tyypillisiä sovelluksia ovat esimerkiksi uutisten tai muiden sivuun liittyvien tietojen päivittäminen kerran tietyssä aikavälissä. Annotaatio @Scheduled mahdollistaa tietyin aikavälein tapahtuvat pyynnöt. Sille voidaan määritellä ajastuksia esimerkiksi cron-formaatissa. Seuraavan komponenttiluokan metodi executeOnceInAMinute suoritetaan kerran minuutissa.
@Component
public class CronService {
@Scheduled(cron = "1 * * * * *")
public void executeOnceInAMinute() {
// ...
}
}
Joissain tapauksissa entiteettien avainarvot halutaan saada tietoon jo ennen tietokantaan tallentamista. Tällöin avainarvoina käytetään sovelluksen itse luomaa avainta. Jos avainarvoja ei luoda tietokannan toimesta, on kuitenkin mahdollista että useammalla entiteetillä on sama avainarvo. Tällöin pyritään siihen, että saman avainarvon kahdesti luomisen todennäköisyys on mahdollisimman pieni.
Yleinen ratkaisu satunnaisen avaimen luomiseen on satunnaisen merkkijonon käyttäminen avaimena. Javalla hyvin satunnaisen merkkijonon saa luotua esimerkiksi UUID-luokan avulla. UUID-luokka arpoo merkkijonon joukosta, jossa on noin 2128 vaihtoehtoa.
Avaimen generointi voi tapahtua esimerkiksi luokan parametrittomassa konstruktorissa tai osana luokkaa käyttävää palvelua.
Tyypillinen sovelluskehittäjien jossain vaiheessa kohtaama vaatimus on palvelu käyttäjän tiedostojen vastaanottamiseen ja tallentamiseen. Toteutetaan tässä palvelu, johon voi lähettää tiedostoja. Tiedostot tallennetaan tietokantaan, josta ne voi listata.
Jotta tiedostojen lähettäminen palvelimelle olisi mahdollista, tarvitsemme Apache Commons-projektin fileupload-komponentin käyttöömme. Fileupload-komponentti tarvitsee käyttöönsä commons-io -projektin, joten lisätään molemmat pom.xml-tiedostoomme:
Tämän lisäksi lisätään spring-base.xml-tiedostoon erillinen Apache Commonsia käyttävä bean, jonka tehtävänä on käsitellä tiedostoja sisältävät pyynnöt.
Huom! Jos käytät GlassFishin versiota 3.1.2, törmännet bugiin bugi, joka aiheuttaa ongelmia tiedostojen käsittelyssä. Ongelman voi onneksi kiertää vaihtamalla palvelimen vanhempaan tai uudempaan versioon.
Kun lähetämme lomakkeen, palvelimen logeissa näkyy lomakkeella lähetetyt arvot.
Seuraava askel on tiedostoja tallentavan olion suunnittelu. Luodaan entiteetti DataObject, sekä palvelu DataService. Tallennetaan entiteettiin data oliomuuttujaan content, joka on byte-taulukko, ja jolla on @Lob-annotaatio. Tällä ilmoitamme kentän sisältävän binääridataa. Oliomuuttujaan liittyvään @Column-annotaatioon lisätään myös tallennettavan tiedon koko (length). Koska tiedostoja ladattaessa palvelimen tulee pystyä kertomaan ladattavan tiedoston tyyppi, otamme tiedoston mediatyypin (mimetype) ja nimen talteen. Tämän lisäksi, koska datan tallentamista tietokantaan ei tarvitse odottaa, luomme id:n jo oliota luodessa.
Luodaan seuraavaksi palvelurajapinta tiedostojen tallentamiselle. Rajapinta DataStorageService tarjoaa perus CRUD-toiminnallisuuden sekä listauksen. Huomaa, että rajapinta on itseasiassa hyvin tuttu. Huomattava osa web-sovelluksista perustuvat CRUD-toiminnallisuuteen.
Rajapinnan toteuttavan luokan create-metodi asetettaisiin asynkroniseksi, jolloin sen suorittamista ei tarvitse eriseen odottaa. Käytämme tietokantaan tallennukseen Spring Data JPA:ta, joten tietokantatoteutuksemme on kevyt.
public interface DataStorageRepository extends JpaRepository<DataObject, String> {
}
Palvelukerrokselle toteutetaan transaktiot, sekä tiedostojen tallennus. Palvelun toteutus jätetään lukijalle. Lisätään vielä kontrolleriin toiminnallisuus, jossa data lähetetään palvelutasolle, sekä ylimääräinen view-metodi, jossa näytetään yksittäisen tiedoston tiedot.
// pakkaus
import java.io.IOException;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.multipart.MultipartFile;
import org.springframework.web.servlet.mvc.support.RedirectAttributes;
@Controller
public class BinaryDataController {
@Autowired
private DataStorageService dataStorageService;
@RequestMapping(method = RequestMethod.GET, value = "data/{objectId}")
public String view(Model model, @PathVariable Long objectId) {
model.addAttribute("dataObject", dataStorageService.read(objectId));
return "view";
}
@RequestMapping(method = RequestMethod.GET, value = "data")
public String view() {
return "form";
}
@RequestMapping(method = RequestMethod.POST, value = "data")
public String post(
RedirectAttributes redirectAttributes,
@RequestParam("name") String name,
@RequestParam("description") String description,
@RequestParam("file") MultipartFile file) throws IOException {
// mahdollinen validointi, datan voi kytkeä myös olioon suoraan
DataObject dataObject = new DataObject();
dataObject.setName(name);
dataObject.setDescription(description);
dataObject.setMimetype(file.getContentType());
dataObject.setContent(file.getBytes());
dataObject.setFilename(file.getOriginalFilename());
dataStorageService.create(dataObject);
redirectAttributes.addAttribute("objectId", dataObject.getId());
return "redirect:data/{objectId}";
}
}
Toiminnallisuus datan lähettämiseen ja katsomiseen on nyt kunnossa. Toteutetaan vielä erillinen kontrolleri dataobjektien lataamiseen palvelimelta. Ensimmäinen versio, DownloadController-luokassa oleva metodi download, kuuntelee pyyntöjä osoitteeseen download/{objectId}. Pyynnön polussa tulevan tunnuksen perusteella tietokannasta haetaan haluttu olio. Oliosta haetaan siihen liittyvä data, ja lisätään se osaksi vastausta. Vastaukseen lisätään myös tiedot vastauksen sisällöstä (content type), pituudesta (content length), ja pakotetaan selain lataamaan tiedosto asettamalla otsake Content-Disposition. Tämän jälkeen data kopioidaan käyttäjälle vastaukseksi.
// pakkaus ja importit
@Controller
public class DownloadController {
@Autowired
private DataStorageService dataStorageService;
@RequestMapping(method = RequestMethod.GET, value = "download/{objectId}")
public void download(@PathVariable Long objectId, HttpServletResponse response) throws Exception {
DataObject object = dataStorageService.read(objectId);
if (object == null) {
response.setStatus(HttpServletResponse.SC_NOT_FOUND);
return;
}
byte[] content = object.getContent();
response.setContentType(object.getMimetype());
response.setContentLength(content.length);
response.setHeader("Content-Disposition", "attachment; filename=" + object.getFilename());
InputStream inputStream = new ByteArrayInputStream(content);
OutputStream outputStream = response.getOutputStream();
IOUtils.copy(inputStream, outputStream);
response.flushBuffer();
}
// ...
Tyylikkäämpi tapa juuri toteutetun tiedoston lataamisen toteuttamiseen on ResponseEntity-luokan käyttäminen. ResponseEntity-luokan luominen on käytännössä eriyttänyt HTTP-vastauksen sisältämän datan erilliseksi single responsibility principle-periaatetta seuraavaksi luokaksi.
// ...
@RequestMapping(method = RequestMethod.GET, value = "download/{objectId}")
@ResponseBody
public ResponseEntity<byte[]> download(@PathVariable Long objectId) throws Exception {
DataObject object = dataStorageService.read(objectId);
if (object == null) {
return new ResponseEntity<byte[]>(HttpStatus.NOT_FOUND);
}
byte[] content = object.getContent();
// otsakkeiden luonti
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.parseMediaType(object.getMimetype()));
headers.setContentLength(content.length);
headers.set("Content-Disposition", "attachment; filename=\"" + object.getFilename() + "\"");
// datan palautus
return new ResponseEntity<byte[]>(content, headers, HttpStatus.OK);
}
// ...
Family Album
Pelkän tekstimuotoisen tiedon esittäminen ei aina riitä. Koska olemme jo tutustuneet hieman tiedostojen lähettämiseen ja lataamiseen, tehdään seuraavaksi verkkopalvelu, jonne voi koota kuvista oman albumin. Jokaiselle kuvalle voi tallettaa myös tekstikommentin.
Tehtäväpohjan mukana tulee yksinkertainen käyttöliittymä, jonka avulla voi lähettää palveluun uusia kuvia sekä selata aiemmin lähetettyjä kuvia. Tehtäväpohjassa on myös valmis Spring-peruskonfiguraatio.
Huom! Tämä tehtävä on avoin tehtävä, eikä sen mukana tule muita luokkia kuvaa kuvaavan Image-luokan lisäksi (jota sitäkin joutunet täydentämään). Pääset siis koodaamaan ohjelman taas lähes täysin itsenäisesti, ja ohjelman täytyy vain toteuttaa vaadittu HTTP-rajapinta.
Projekti on konfiguroitu siten, että Spring Data JPA-luokkia haetaan oletuksena pakkauksesta wad.familyalbum.repository, lähdekooditiedostojen oletetaan olevan pakkauksessa wad tai sen alipakkauksissa.
Kuvatiedoston vastaanottaminen selaimelta ja lähettäminen selaimelle
Sovelluksen varastoimilla kuvilla (eli kuvan entiteetillä) tulee olla seuraavat attribuutit:
id - merkkijonoavain, joka luodaan oliota luodessa
description - käyttäjän antama tekstimuotoinen kuvaus
contentType - kuvatiedoston mediatyyppi
fileName - kuvatiedoston alkuperäinen nimi
timestamp - aikaleima, jolloin kuvatiedosto on talletettu
Kuvan varsinainen binääridata, jonka attribuutin nimellä ei ole väliä
Tallenna kuvat tietokantaan. Tiedostojen vastaanottamiseen käytettävä multipartResolver-bean on konfiguroitu valmiiksi käyttöösi.
Tehtäväpohjan mukana annetun käyttöliittymän tulee toimia osoitteessa /app/album. Tämän sivun avulla voit testata ohjelmaasi.
Sovelluksen tulee toteuttaa seuraavat HTTP-pyynnöt:
GET /app/album asettaa Model-instanssiin attribuutin images, joka sisältää listan kaikista kuvista, ja näyttää näkymän album.
POST /app/images vastaanottaa yksittäisen tiedoston ja sen tekstikuvauksen HTTP multipart/form-data muodossa. Tiedoston parametrin nimi on file ja kuvauksen description. Sovelluksen tulee tallettaa tiedoston kuvaus, mediatyyppi sekä alkuperäinen tiedostonimi. Tiedostolla tulee olla merkkijonoavain ja uudelle tiedostolle annettu avain täytyy palauttaa HTTP-vasteen otsakkeessa X-Image-Id, jotta asiakasohjelmisto tietää mikä on uuden kuvan avain. Pyyntö tulee lopuksi uudelleenohjata osoitteeseen /app/album.
GET /app/images/{imageId}/download lähettää avaimella imageId löytyvän tiedoston asiakasohjelmistolle. HTTP-vasteeseen tulee asettaa tiedoston mediatyyppi (Content-Type) sekä tiedoston koko tavuina (Content-Length), jotta asiakasohjelmisto, kuten selain, osaa tulkita tiedoston sisällön oikein.
Tässä vaiheessa kuvien lähettämisen ja selaamisen pitäisi onnistua mukana tulevan käyttöliittymän avulla. Download-linkit eivät vielä toimi, keskitymme niihin seuraavaksi.
Käyttöliittymässä listattavia kuvia voi tarkastella yksitellen klikkaamalla kuvaa. Tällä tavoin näytettävän kuvatiedoston tallentaminen selaimella tietokoneelle ei kuitenkaan ole suoraviivaista, vaan vaatii mm. tiedoston nimeämisen, sillä selain ei tiedä tiedoston nimeä.
Selain voidaan "pakottaa" tallentamaan tiedosto palvelimen tarjoamalla nimellä asettamalla HTTP-vasteeseen otsake Content-Disposition. Otsaketiedossa tiedoston nimi tulee lainausmerkkien sisälle, eli lainausmerkit kuuluvat otsakkeeseen:
Laajenna sovellusta siten seuraavalla HTTP-pyynnöllä:
GET /app/images/{imageId}/download/attachment toimii muutoin samalla tavalla kuin edellisen kohdan tiedoston lähetys asiakasohjelmistolle, mutta HTTP-vasteeseen tulee asettaa otsake Content-Disposition edellämainittujen ohjeiden mukaisesti.
Nyt voit kokeilla ladata tiedostoja käyttöliittymän Download-linkkien avulla.
JSON-rajapinta kuvien tietojen lukemiseen
Jotta kuvien tekstimuotoisia kuvauksia ja muita tietoja voisi käyttää asiakasohjelmissa, täytyy sovelluksen tarjota pääsy näihin tietoihin esim. JSON-muotoisen tiedon avulla.
Huom! Spring (tai oikeastaan JSON-kirjasto Jackson) muodostaa JSON-muotoisen HTTP-vasteen domain-olioista (tässä tapauksessa kuvan entiteetistä) sen getter-metodien perusteella, joten kuvan binääridata päätyy myös JSON-vasteeseen, koska binääridatallekin on luonnollisesti oltava getter-metodi. Emme kuitenkaan halua binääridataa JSON-vasteeseen, koska kuvan sisältö on tarkoitettu ladattavaksi erillisestä osoitteesta. Yksittäisen getterin sulkeminen pois JSON-vasteesta onnistuu getter-metodille asetettavan annotaation org.codehaus.jackson.annotate.JsonIgnore avulla.
@JsonIgnore-annotaatiota käytetään esimerkiksi näin:
@JsonIgnore
public byte[] getData() {
return data;
}
Laajenna vielä sovellusta siten, että se palauttaa JSON-muotoisia vastauksia seuraaville HTTP-pyynnöille:
GET /app/images/{imageId} palauttaa yksittäisen kuvan JSON tiedot ilman kuvan varsinaista binääridataa
GET /app/images palauttaa JSON-listan, jossa on kaikkien talletettujen kuvien tiedot ilman binääridataa
Yksittäisen kuvan JSON-esitys tulisi näyttää esimerkiksi tältä (sisennykset ja rivinvaihdot on lisätty selkeyden vuoksi):
Kun palvelinohjelmistoja skaalataan siten, että osa laskennasta siirretään erillisille palvelimille, on oleellista että palveluiden välillä kulkevat viestit (pyynnöt ja vastaukset) eivät katoa, ja että käyttäjän pyyntöjä vastaanottavan palvelimen ei tarvitse huolehtia toisille palvelimille lähetettyjen pyyntöjen perille menemisestä tai lähetettyjen viestien vastausten käsittelystä. Eniten käytetty lähestymistapa viestien säilymisen varmentamiseen on viestijonot (messaging, message queues), joiden tehtävänä on toimia viestien väliaikaisena säilytyspisteenä. Käytännössä viestijonot ovat erillisiä palveluita, joihin viestien tuottajat (producer) voivat lisätä viestejä, joita viestejä käyttävät palvelut kuluttavat (consumer).
Viestijonoja käyttävät sovellukset kommunikoivat viestijonon välityksellä. Tuottaja lisää viestejä viestijonoon, josta käyttäjä niitä hakee. Kun viestin sisältämän datan käsittely on valmis, prosessoija lähettää viestin takaisin. Viestijonoissa on yleensä varmistustoiminnallisuus: jos viestille ei ole vastaanottajaa, jää viesti viestijonoon ja se tallennetaan esimerkiksi viestijonopalvelimen levykkeelle. Viestijonojen konkreettinen toiminnallisuus riippuu viestijonon toteuttajasta.
Viestijonosovelluksia on useita, esimerkiksi ActiveMQ ja RabbitMQ. Viestijonoille on myös useita standardeja, joilla pyritään varmistamaan sovellusten yhteensopivuus. Esimerkiksi Javan melko pitkään käytössä ollut JMS-standardi määrittelee viestijonoille APIn, jonka viestijonosovelluksen tarjoajat voivat toteuttaa (vrt. JDBC). Nykyään myös AMQP-protokolla on kasvattanut suosiotaan.
Aivan kuten esimerkiksi REST-tyylisen rajapinnan käyttö osana palveluorientoitunutta arkkitehtuuria, myös viestijonot mahdollistavat eri sovellusten helpon integroimisen. Viestejä tuottava sovellus voi olla toteutettu esimerkiksi COBOLilla, kun taas viestejä vastaanottava sovellus voidaan toteuttaa esimerkiksi Perlillä.
JMS ja ActiveMQ
Tutustutaan seuraavaksi hieman tarkemmin JMS-rajapintaan ja sen käyttöön. Käytetään JMS-rajapinnan toteutuksena ActiveMQ-toteutusta. ActiveMQ:n käyttöön tarvittavat kirjastot saa käyttöön lisäämällä projektiin liittyvään pom.xml-tiedostoon seuraavan riippuvuuden.
ActiveMQ-palvelimen saa lataamalla sen ActiveMQ:n kotisivuilta http://activemq.apache.org. Yleinen *nix-versio käy hyvin. Kun ActiveMQ on ladattu, se puretaan sopivaan kansioon. ActiveMQ käynnistyy sen alikansiossa bin olevan activemq-tiedoston avulla seuraavasti:
apache-activemq $ ./bin/activemq start
Komento start käytännössä tämä käynnistää viestijonopalvelimen oletuksena paikallisen koneen porttiin 61616 (osoite "tcp://localhost:61616"). Viestijonopalvelin on erillinen sovellus, joka sisältää joukon viestijonoja. Jokaiseen viestijonoon voi sekä asettaa viestejä, että niistä voi hakea viestejä. Luodaan seuraavaksi sovellus viestien lisäämiseksi viestijonoon. Lisätään viestijonoon nimeltä "messages"TextMessage-tyyppisiä olioita, jotka sisältävät tekstiä.
// avataan yhteys
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616");
Connection connection = connectionFactory.createConnection();
connection.start();
// luodaan sessio viestien lähettämiseen, ei käytetä transaktioita
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
// haetaan viestijono nimeltä "messages"
Destination destination = session.createQueue("messages");
// luodaan messageproducer-olio, jota käytetään viestien lähetykseen
MessageProducer producer = session.createProducer(destination);
// luodaan lähetettävä viesti, viesti sisältää merkkijonon "Hello World!"
TextMessage message = session.createTextMessage("Hello World!");
// lähetetään viesti
producer.send(message);
// suljetaan yhteys
connection.close();
Luodaan seuraavaksi sovellus, joka vastaanottaa viestejä.
// avataan yhteys
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616");
Connection connection = connectionFactory.createConnection();
connection.start();
// luodaan sessio viestien vastaanottamiseen, ei käytetä transaktioita
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
// haetaan viestijono nimeltä "messages"
Destination destination = session.createQueue("messages");
// luodaan messageconsumer-olio, jota käytetään viestien lukemiseen
MessageConsumer consumer = session.createConsumer(destination);
// haetaan viesti jonosta -- jos viestiä ei ole, jäädään odottamaan
// kaikille viestityypeille on yhteinen Message-rajapinta, joka
// tulee muuttaa halutuksi tyypiksi
Message message = consumer.receive();
// tulostetaan viestin sisältö
TextMessage textMessage = (TextMessage) message;
System.out.println(textMessage.getText());
// suljetaan yhteys
connection.close();
Hello World!
Viestinjonon saa sammutettua komennolla stop.
apache-activemq $ ./bin/activemq stop
Käytännössä viestien lähettäjän ja vastaanottajan vastuulla on yhteyden luominen, viestijonon valinta, viestin luominen tai hakeminen ja yhteyden sulkeminen. Huomattava osa koodista on kuitenkin toisteista, ja viestien prosessoinnin helpottamiseksi on kehitetty muutamia apuvälineitä. Esimerkiksi Spring tarjoaa oman JMS-tukikirjaston. Saamme sen käyttöön lisäämällä projektimme pom.xml-tiedostoon seuraavan riippuvuuden.
Spring JMS tarjoaa käyttöömme muun muassa JmsTemplate luokan. JmsTemplate tarjoaa apuvälineitä JMS-pyyntöjen tekemiseen. JmsTemplate hoitaa muun muassa yhteyden avaamisen ja sulkemisen, ja sen voi konfiguroida osana sovelluksen konfiguraatiota. Automaattisesti injektoitavan JmsTemplate-beanin voi luoda sovellukseen määrittelemällä beanin osana front-controller-servlet.xml-konfiguraatiota.
<!-- ... -->
<!-- viestijono "messages" -->
<bean id="destination" class="org.activemq.message.ActiveMQQueue">
<constructor-arg value="messages" />
</bean>
<!-- yhteyden luomiseen tarvittu tehdas -->
<bean id="connectionFactory" class="org.activemq.ActiveMQConnectionFactory">
<property name="brokerURL" value="tcp://localhost:61616" />
</bean>
<!-- JmsTemplate, joka käyttää viestijonoa ja aiemmin määriteltyä yhteystehdasta -->
<bean id="jmsTemplate" class="org.springframework.jms.core.JmsTemplate">
<property name="connectionFactory" ref="connectionFactory" />
<property name="defaultDestination" ref="messages" />
</bean>
<!-- ... -->
Nyt aiemmin esitetyn viestin lähetyksen voi hoitaa helpommin. Oletetaan että käytössämme on rajapinta MessageSender:
public interface MessageSender {
void enqueue(final String message);
}
Rajapinnan toteuttaa luokka JmsMessageSender:
@Service
public class JmsMessageSender implements MessageSender {
@Autowired
private JmsTemplate jmsTemplate;
@Override
@Async
public void enqueue(final String message) {
jmsTemplate.send(new MessageCreator() {
@Override
public Message createMessage(Session session) throws JMSException {
return session.createTextMessage(message);
}
});
}
}
Vastaavasti aiemmin esitetyn viestin vastaanottamisen voi toteuttaa myös hieman helpommin. Oletetaan että käytössämme on rajapinta MessageReceiver:
public interface MessageReceiver {
String dequeue();
}
Rajapinnan toteuttaa luokka JmsMessageReceiver:
@Service
public class JmsMessageReceiver implements MessageReceiver {
@Autowired
private JmsTemplate jmsTemplate;
@Override
public String dequeue() {
TextMessage textMessage = (TextMessage) jmsTemplate.receive();
return textMessage.getText();
}
}
Kummankin ylläolevista luokista voi injektoida automaattisesti palveluksi esimerkiksi kontrolleriluokkaan. Oikeastaan fiksumpi tapa viestin vastaanottamiseen olisi toteuttaa MessageListener-rajapinta, jolloin Spring kutsuu vastaanottajan metodia aina tarvittaessa. Luodaan toinen versio luokasta JmsMessageReceiver:
@Component
public class JmsMessageReceiver implements MessageListener {
// ...
@Override
public void onMessage(Message message) {
TextMessage textMessage = (TextMessage) message;
// tee jotain vastaanotetulla viestillä, esimerkiksi
// lähetys erilliseen (injektoituun) palveluun tai tietokantaan
}
}
MessageListener-toteutukset tulee konfiguroida Springiin. Jotta ylläoleva luokka toimisi, tulee spring-base.xml-tiedostoon (tai muualle kofiguraatioon) erillinen varasto viestien kuuntelijoille.
Tietokanta-abstraktioita tarjoavat komponentit kuten Eclipselink päättävät jollain periaatteella mitä tehdään haettavaan olioon liittyville viitteille. Yksi vaihtoehto on hakea viitatut oliot automaattisesti kyselyn yhteydessä ("Eager"), toinen vaihtoehto taas on hakea viitatut oliot vasta kun niitä pyydetään eksplisiittisesti esimerkiksi get-metodin kautta ("Lazy").
EclipseLink hakee oletuksena one-to-many ja many-to-many -viitteet vasta niitä tarvittaessa, ja one-to-one ja many-to-one viitteet heti. Oletuskäyttäytymistä voi muuttaa FetchType-parametrin avulla. Esimerkiksi alla ehdotamme, että aircrafts-lista noudetaan heti.
// pakkaus
@Entity
public class Airport implements Serializable {
@Id
private Long id;
private String location;
private String identifier;
private String name;
@OneToMany(fetch=FetchType.EAGER)
@JoinColumn
private List<Aircraft> aircrafts;
// getterit ja setterit
}
Käytännössä tietokannasta tarvittaessa haku toteutetaan luomalla get-metodista ns. proxy, jota kutsuttaessa tapahtuu tietokantakysely, joka palauttaa get-metodiin liittyvän olion. Staattisesti tyypitetyissä ohjelmointikielissä tämä käytännössä vaatii sitä, että luokkien rakennetta muutetaan joko ajonaikaisesti tai lähdekooditiedostojen kääntövaiheessa (weaving).
Oma konfiguraatiomme
Omassa persistence.xml-konfiguraatiossamme luokkien rakenteen muuttaminen on otettu pois käytöstä, jolloin kyselyt tehdään automaattisesti EAGER-tyylisesti. Ylläoleva weaving-linkki tarjoaa opastuksen siihen, miten luokkien rakenteen muuttamisen saa päälle.
N+1 Kyselyn ongelma
Viitattujen olioiden lataaminen vasta niitä tarvittaessa on yleisesti ottaen hyvä idea, mutta sillä on myös kääntöpuolensa. Pohditaan tilannetta, missä kirjalla voi olla monta kirjoittajaa, ja kirjoittajalla monta kirjaa -- ManyToMany. Jos haemme tietokannasta listan kirjoja (1 kysely), ja haluamme tulostaa kirjoihin liittyvät kirjoittajat, tehdään jokaisen kirjan kohdalla erillinen kysely kyseisen kirjan kirjoittajille (n kyselyä). Tätä ongelmaa kutsutaan N+1 -kyselyn ongelmaksi.
Jos kirjoja tarvitaan sekä ilman kirjoittajaa että kirjoittajan kanssa, on FetchType-parametrin asettaminen EAGER-tyyppiseksi yksi vastaus. Tällöin kuitenkin osassa tapauksista haetaan ylimääräistä dataa tietokannasta. Toinen vaihtoehto on luoda erillinen kysely yhdelle vaihtoehdoista, ja lisätä kyselyyn vinkki (QueryHint, Spring Data JPA, applying query hints) kyselyn toivotusta toiminnallisuudesta.
public interface AirportRepository extends JpaRepository<Airport, Long> {
@Query("SELECT a FROM Airport a WHERE a.name like %?1")
@QueryHints(value = { @QueryHint(name = "eclipselink.join-fetch", value = "a.aircrafts")},
forCounting = false)
Page<Airport> findByNameLike(String name, Pageable pageable);
Page<Airport> findByNameContaining(String name, Pageable pageable);
}
Yllä määrittelemme kaksi kyselyä. Ensimmäinen kysely on annettu JPA-muodossa siten, että kyselylle on annettu myös vinkki: kaikki lentokenttään liittyvät lentokentät tulee hakea saman JOIN-kyselyn avulla. Toinen kysely hakee lentokentät oletusmuodossa.
Indeksit
Indeksit ovat tietokantatauluihin määriteltäviä hakurakenteita, joiden avulla kyselyiden nopeutta voidaan mahdollisesti nopeuttaa. JPA 2-spesifikaatio ei ota kantaa indeksien toteuttamiseen, joten niiden määrittely on jäänyt ORM-toteuttajien vastuulle. Käytännössä indeksit ovat tietokantakohtaista; suurin osa tietokannoista luo automaattisesti indeksin ainakin avainkentälle (id) sekä viittauskentille, ja toisaalta jotkut tietokannat eivät tue indeksejä ollenkaan. Yleisesti ottaen indeksien luonti on sovelluskehittäjän vastuulla.
Tyypillinen käyttötapaus indeksille on henkilön nimen perusteella tapahtuva täsmähaku tietokannasta (osa tietokannoista tulee myös tekstikenttien indeksointia siten, että myös "contains"-haut tehdään nopeasti). Jos tietokantataululla ei ole indeksiä nimi-kentälle, käydään kaikki tietokannan nimi-sarakkeessa olevat arvot läpi arvoa haettaessa.
EclipseLink tarjoaa tuen indeksien luomiseen. Yksinkertaisimmillaan indeksin luominen tietylle kentälle tapahtuu annotaation @Index-avulla.
// pakkaus
@Entity
public class Airport implements Serializable {
@Id
private Long id;
private String location;
@Index
private String identifier;
private String name;
@OneToMany(fetch=FetchType.EAGER)
@JoinColumn
private List<Aircraft> aircrafts;
// getterit ja setterit
}
Ylläolevassa esimerkissä lentokentän tunnukseen on lisätty indeksi. Tällöin tunnukseen perustuvat haut toimivat huomattavasti nopeammin.
Donald Knuth : Premature optimization is the root of all evil (or at least most of it) in programming.
Klassikkoartikkeli osuu hyvin teemaamme vaikka web ei 1970-luvulla ollut kovin kovassa huudossa.
There is no doubt that the grail of efficiency leads to abuse. Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
Yet we should not pass up our opportunities in that critical 3%. A good programmer will not be lulled into complacency by such reasoning, he will be wise to look carefully at the critical code; but only after that code has been identified. It is often a mistake to make a priori judgements about what parts of a program are really critical, since the universal experience of programmers who have been using measurement tools has been that their intuitive guesses fail...
Optimoi koodiasi siis vasta tarvittaessa, silloinkin vasta kun tiedät kohdan jota oikeasti tulee optimoida.
Index-em!
Olet tehnyt työtä jonkin aikaa järjestelmän kanssa, joka indeksoi kirjoja. Se on myyty jo useampaan paikkaan, ja yhdessä paikoista käytössä on skanneri, jolla saa oleellisimmat kirjan tiedot täydettyä täsmällisesti hakukenttään. Tuotantokäytössä ohjelmiston hakutoiminnallisuus on kuitenkin todettu hitaaksi, ja sovelluksen käyttäjät toivovat ohjelmistoon lisää nopeutta. Tehtävänäsi tässä tehtävässä on parantaa ohjelmiston hakutoiminnallisuutta lisäämällä indeksit tietokantaobjekteihin.
le end of wk5
Mikä on välimuisti ja mihin sitä käytetään? Mihin kohtaan palvelinohjelmistoa välimuistin voi asettaa? Mitä hyötyjä ja haittoja eri vaihtoehdoissa on?
Mitä hyötyjä ja haittoja liittyy HTTP-protokollan rajoitteeseen "rajoita osoitteeseen tehtävien samanaikaisten pyyntöjen määrä kahteen"? Miten näitä voi kiertää?
Mitä ovat SAAS, PAAS ja IAAS? Miten ne liittyvät toisiinsa?
Miten asynkronisten metodikutsujen käyttäminen osana palvelinohjelmiston rakennetta voi muuttaa palautettavan datan muotoa? Mitä tällöin tehdään?
Miksi tietokannoissa käytetään silloin tällöin merkkijonoavaimia? Mitä hyötyä niistä on?
Mitä ovat viestijonot ja mihin niitä käytetään?
Mikä on N+1 kyselyn ongelma? Miten se ilmenee ja voiko sen kiertää? Jos kyllä, miten?
le start of wk6
Muutama sana tietoturvasta
Autentikointi ja autorisointi
Autentikoinnilla tarkoitetaan sitä, että käyttäjän identiteetti varmistetaan. Autentikointi tapahtuu esimerkiksi käyttäjätunnuksen ja salasanan avulla. Autorisoinnilla taas tarkoitetaan sen varmistamista, että käyttäjä saa tehdä hänen yrittämiään asioita.
HTTP-protokolla vaatii sen toteuttajilta kaksi autentikointitapaa: "Basic autentikoinnin" ja "digest autentikoinnin". Emme käsittele niitä tässä, lisätietoa niistä löytää täältä.
Autentikointi, eli käyttäjän identiteetin varmistaminen, on yksi web-sovellusten oleellisista ominaisuuksista. Käyttäjän identiteetti tarkistetaan yleisimmin käyttäjätunnus-salasana -parin avulla siten, että käyttäjä lähettää ne HTTP-yhteyden yli palvelimelle. Kiitettävä osa nykyaikaisista sovelluskehyksistä tarjoaa autentikointimekanismin osana tietoturvakomponenttiaan. Autentikointisovellukset toimivat yleensä erillisinä filttereinä tarkistaen sovellukselle tehtäviä pyyntöjä.
Käyttäjän identiteetin varmistaminen vaatii käyttäjälistan, joka taas yleensä ottaen tarkoittaa käyttäjän rekisteröintiä palveluun. Käyttäjän rekisteröitymisen vaatiminen heti sovellusta käynnistettäessä voi rajoittaa käyttäjien määrää huomattavasti, joten rekisteröitymistä kannattaa pyytää vasta kun siihen on tarve.
Erillinen rekisteröityminen ja uuden salasanan keksiminen ei ole aina tarpeen. Web-sovelluksille on käytössä useita kolmannen osapuolen tarjoamia keskitettyjä identiteetinhallintapalveluita. Esimerkiksi OpenAuth:n avulla sovelluskehittäjä voi antaa käyttäjilleen mahdollisuuden käyttää jo olemassaolevia tunnuksia.
Autentikoinnin lisäksi tulee varmistaa, että käyttäjät pääsevät käsiksi vain heille oikeutettuihin resursseihin. Käyttäjät määritellään yleensä joko yksilöllisesti tai roolien kautta. Yleisin lähestymistapa käyttöoikeuksien määrittelyyn on käyttöoikeuslistat (ACL, Access Control List), joiden avulla määritellään käyttäjien (tai käyttäjäroolien) pääsy resursseihin. Käytännössä käyttöoikeuslistat määritellään osoitteille tai metodeille.
Autentikaatio ja autorisointi Springissä
Spring tarjoaa erillisen tietoturvakomponentin, jota voi käyttää myös web-sovelluksissa. Koska Spring on komponenttipohjainen sovelluskehys, myös tietoturvaan liittyvät komponentit tulee lisätä käyttöä varten. Lisätään ensin pom.xml-tiedostoon tietoturvaan liittyvät riippuvuudet. Otamme tässä vaiheessa myös käyttöön muutamia myöhemmin tarvitsemiamme palasia. Koska Spring Securityn omaan konfiguraatioon on määritelty hieman vanhemmat Spring-riippuvuudet, pidämme sen riippuvuudet melko alhaalla pom.xml-tiedostoa. Tällöin aiemmin määritellty riippuvuudet hakevat nykyaikaiset versiot, ja vanhemmat versiot jäävät hakematta.
Spring tarjoaa oman filtterin tietoturvan lisäämiseksi pyyntöihin. Konfiguroidaan se web.xml-tiedostoon. Jotta filtterille voidaan ladata tietoturvakonfiguraatio, lisätään web.xml-tiedostoon erillinen kuuntelija konfiguraation latausta varten. Käytännössä filtteri on erillinen muusta palvelinohjelmistosta, joten sitä ei konfiguroida osana spring-base.xml-tiedostoa.
Tiedosto web.xml on kokonaisuudessaan seuraavanlainen kun se sisältää konfiguraatiokontekstin lataamisen, pyyntöjen kuljettamisen springin tarjoaman tietoturvafiltterin kautta, pyynnöissä käytettävän merkistön automaattisen muuntamisen UTF-8:ksi, DELETE- ja PUT-pyyntöjen tuen lisäämisen lomakkeisiin, sekä Springin tarjoaman front-controller -servletin lataamisen.
Tämän lisäksi tarvitsemme erillisen tietoturvakonfiguraation. Lisätään kansioon WEB-INF tiedosto security.xml, jossa on tietoturvakonfiguraatio. Alla olevassa konfiguraatiossa määrittelemme pääsynvalvonnan osoitteisiin, sekä käyttäjätunnusten hallinnan. Polkuun pub ja sen alipolkuihin on pääsy kaikilta, kun taas polku hidden ja sen alipolut vaativat autentikoitumista (isAutenticated()). Juuripolku on kaikille sallittu, ja loput poluista on kielletty kaikilta. Lisäksi määrittelemme että Spring security hoitaa kirjautumissivun ja logout-osoitteen. Kirjautumissivu on automaattinen, sovelluksesta voi poistua tekemällä (oletuksena) pyynnön osoitteeseen http://osoite-ja-sovellus/j_spring_security_logout.
Tämän lisäksi tiedostossa määritellään kaksi käyttäjätunnusta, "kasper" ja "heikki" sekä niiden salasanat. Käyttäjätunnuksille määritellään lisäksi roolit authorities-attribuutilla. Esimerkiksi käyttäjätunnuksella el_barto on sekä admin-rooli, että ope-rooli. Polkuihin voi määritellä autentikoinnin lisäksi pääsyn myös roolien perusteella. Esimerkiksi intercept-url-elementille lisätty attribuutti access="hasRole('admin')" vaatii, että roolina on admin. Vastaavasti useita rooleja voi määritellä sanomalla access="hasAnyRole('admin','ope')".
Elementin sec:http parametri use-expressions kertoo, että käytämme Spring EL-tyyppisiä komentoja konfiguraatiossa. Elementti sec:form-login kertoo, että spring luo automaattisesti kirjautumislomakkeen, ja sec:logout kertoo, että sivulta voi kirjautua ulos. Lisätietoja täältä (mm. avainsanat "Getting Started with Security" ja "Expression-Based Access Control" ovat hyödyllisiä).
You Shall Not Pass!
Projektin pohjaan on konfiguroitu Spring Securityn vaatima filtteritoiminnallisuus. Kansion WEB-INF alla olevassa spring-kansiossa on tiedosto security.xml, jossa on määritelty pääsyrajaukset ja käyttäjätunnukset. Nykyisessä konfiguraatiossa sekä juuripolku että tiedosto index.jsp on sallittu kaikille. Tiedostossa on myös määritelty käyttäjä mikael, jonka salasana on rendezvous.
Muokkaa lisäksi konfiguraatiota siten, että aiemman konfiguraation lisäksi osoitteeseen public ja sen alipolkuihin on pääsy kaikilta. Osoitteiden app ja secret alipolkuihin vaaditaan käyttäjärooli user. Pääsy kaikkiin muihin polkuihin tulee kieltää.
Lisää sovellukseen myös käyttäjä kasper roolilla user. Käyttäjän kasper salasana on spring.
Kun olet muokannut konfiguraatiota, testaa sovellustasi ja lähetä se TMC:lle.
Näkymätason autorisointi
Autorisointi pelkkien polkujen perusteella ei aina riitä. Käyttöliitymissä halutaan usein tarjota käyttäjäroolikohtaista toiminnallisuutta. Aiemmin lisäämämme riippuvuus spring-security-taglibs tarjoaa näkymissä käytettävän tägikirjaston, jonka perusteella sivun eri osa-alueiden näkymistä voidaan rajoittaa käyttäjäkohtaisesti.
Nyt JSP-sivuilla voi määritellä alueita, joiden näkyminen vaatii tietyn roolin. Esimerkiksi vain admin-roolille näkyvä linkki määritellään sec-nimiavaruudessa olevan elementin authorize avulla seuraavasti:
<!-- sivun muuta sisältöä -->
<sec:authorize access="hasRole('admin')">
<a href="${pageContext.request.contextPath}/admin/">Admin pages</a>
</sec:authorize>
<!-- sivun muuta sisältöä -->
Attribuutti access määrittelee käytössä olevat roolit. Attribuutille käy mm. arvot isAuthenticated(), hasRole('...') ja hasAnyRole('...').
Metoditason autorisointi
Näkymätason autorisointi ei myöskään aina riitä. Usein toimintaa halutaan rajoittaa siten, että tietyt operaatiot (esim. poisto tai lisäys) mahdollistetaan vain tietyille rooleille. Käyttöliittymän näkymää rajoittamalla ei voida rajoittaa kutsuja polkuihin, ja aiemmin luotu polkuihin tehtävien kutsujen rajoitus ei auta esimerkiksi REST-tyyppisissä osoitteissa, varsinkin jos GET-pyyntöihin halutaan oikeus kaikille.
Sovelluskehykset tarjoavat usein myös metoditason autorisoinnin. Esimerkiksi Springissä metoditason autorisointi hoidetaan annotaatioilla: metodeille määritellään annotaatiot, jotka kertovat käytetyt rajoitukset. Komento sec:global-method-security pre-post-annotations="enabled" lisää käyttöömme annotaatiot, joilla voimme rajata metodien käyttöä esimerkiksi käyttäjäroolien perusteella. Koska konfiguraatio on ladattu kontekstin kautta, tietoturvatoiminnallisuuden voi lisätä tiedostoon security.xml.
Kun konfiguraatiotiedostoon on lisätty rivi sec:global-method-security pre-post-annotations="enabled", on käytössämme mm. annotaatio @PreAuthorize, jolla voidaan määritellä roolit, jotka käyttäjällä tulee olla metodin suorittamiseen. Esimerkiksi annotaatio @PreAuthorize("hasRole('ope')") vaatii, että käyttäjän tulee olla kirjautunut roolissa ope, jotta annotoidun metodin suoritus onnistuu. Annotaatioon @PreAuthorize voidaan määritellä parametrina samoja komentoja kuin aiemminkin. Esimerkiksi arvot isAuthenticated(), hasRole('...') ja hasAnyRole('...') ovat käytössä. Koska samalla komponentilla voi olla useita toteutuksia, asetetaan annotaatiot tyypillisesti osaksi rajapintaa.
Tiitinen List
Tiitisen lista on Supon 1990-luvulla saama lista henkilöistä, joiden uskotaan olleen vuorovaikutuksessa Stasin edustajan kanssa. Jatkokehitämme tässä Supon tietojärjestelmää, jotta saamme listan näkyville myös medialle.
Medialle näytettävä sivu
Lisää konfiguraatiotiedostoon security.xml käyttäjätunnus media jonka salasana on media, ja jonka rooli on media.
Muokkaa tämän jälkeen kansiossa WEB-INF/jsp olevaa sivua page.jsp siten, että käyttäjäroolissa media sivulla page.jsp nähdään oikean listan tilalla kovakoodattu lista (myös lisäyslomake on piilossa):
<ul>
<li>Susanna Reinboth</li>
</ul>
Kun käyttäjä kirjautuu sivulle rooleissa admin tai supo sivu käyttäytyy kuten ennen, eli käyttäjälle näytetään tiitisen listan sisältö. Jos käyttäjällä on rooli admin, voi listalla olevia asioita myös poistaa.
Tarkempi pääsynvalvonta
Huomaat järjestelmää jatkokehittäessäsi, että vaikka roolille supo ei näytetä DELETE-nappia, voi kuka tahansa sivuille kirjautunut tehdä HTTP-pyynnön listaelementtien poistamista hallinnoivaan osoitteeseen onnistuneesti. Kun lisäsit media-käyttäjätunnuksen, myös media voi lisätä tai poistaa listan elementtejä sopivia HTTP-pyyntöjä tekemällä -- vaikkakaan itse listan sisältö ei heille näy.
Korjataan tämä ongelma.
Muokkaa security.xml-tiedostoa siten, että annotaatioilla toimiva metoditason pääsynvalvonta kytketään päälle.
Lisää tämän jälkeen listapalveluun annotaatiot, joilla rajoitetaan metodien kutsuoikeuksia. Metodia create kutsuttaessa tulee olla kirjautunut joko roolilla admin tai supo, metodin remove tulee toimia vain jos käyttäjä on kirjautunut roolilla admin.
Kun olet valmis, testaa sovellustasi ja lähetä se TMC:lle.
Käyttäjien hakeminen tietokannasta
Käyttäjien hakeminen tietokannasta tai muusta palvelusta onnistuu muuttamalla security.xml-tiedostossa olevaa konfiguraatiota. Esimerkiksi jos käytössämme on USERS- ja ROLES-taulut, voimme käyttää erillistä JDBC-yhteyttä käyttäjätunnusten hakemiseen. Kysely tulee toki muokata vastaamaan käytössä olevaa tietokantarakennetta.
<!-- ... -->
<sec:authentication-manager>
<sec:authentication-provider>
<sec:jdbc-user-service data-source-ref="dataSource"
users-by-username-query="SELECT name,password,enabled FROM USERS WHERE name=?"
authorities-by-username-query="SELECT u.name, r.authority from USERS u, ROLES r
where u.user_id = r.user_id and u.name =? "/>
</sec:authentication-provider>
</sec:authentication-manager>
<!-- ... -->
Jos pääsynhallinnan haluaa toteuttaa itse, tarjoaa Spring Security useita rajapintoja, joihin toteutuksen voi tehdä. Yksi vaihtoehto on toteuttaa AuthenticationProvider-rajapinta, ja ottaa se käyttöön. Alla olevassa esimerkissä on KlownAuthenticationProvider, jossa kirjautuminen onnistuu käyttäjätunnuksella "lol". Jos käyttäjä kirjautuu tunnuksella "lol", hänelle asetetaan rooli "krusty". Muulloin heitetään poikkeus, ja Spring tietää, että kirjautuminen epäonnistui.
Springin autentikointipalvelu tutustuu toteutukseen lennosta, ja katsoo tuetut autentikaatiotyylit metodilla supports.
@Service
public class KlownAuthenticationProvider implements AuthenticationProvider {
@Override
public Authentication authenticate(Authentication auth) throws AuthenticationException {
String username = auth.getName();
String password = auth.getCredentials().toString();
if("lol".equals(username)) {
List<GrantedAuthority> grantedAuths = new ArrayList<GrantedAuthority>();
grantedAuths.add(new SimpleGrantedAuthority("krusty"));
return new UsernamePasswordAuthenticationToken(username, password, grantedAuths);
}
throw new AuthenticationException("Incorrect information entered.");
}
@Override
public boolean supports(Class authType) {
return authType.equals(UsernamePasswordAuthenticationToken.class);
}
}
Toteutuksen voi ladata käyttöön muokkaamalla security.xml-tiedostoa siten, että käytämme siellä viitettä KlownAuthenticationProvider-luokasta automaattisesti luotuun klownAuthenticationProvider-olioon.
Toteuta pakkaukseen wad.auth luokka WadAuthenticationProvider, joka toteuttaa rajapinnan AuthenticationProvider ylläolevaa esimerkkiä mukaillen.
Kovakoodaa luokkaan WadAuthenticationProvider käyttäjät "nsa" (salasana "nsa"), jonka rooli on "superuser", sekä "jack" (salasana "random"), jonka rooli on "user". Jos käyttäjä kirjautuu muilla tunnuksilla, älä heitä poikkeusta, vaan aseta käyttäjän rooliksi "anonymous".
Muokkaa tämän jälkeen luokkaa ContentController, ja lisää kontrollerimetodille getContent annotaatio, joka rajaa metodiin pääsyn vain rooleille "user" ja "superuser".
Kun olet valmis, testaa sovelluksesi toimintaa manuaalisesti, ja palauta se lopulta TMC:lle. Tarvitut konfiguraatiot ovat jo (todennäköisesti) paikallaan.
Ylläolevaa esimerkkiä voi käyttää myös käyttäjätunnusten lataamiseen tietokannasta. Sen sijaan, että käyttäjätunnukset olisivat kovakoodattu, voimme injektoida palveluun pääsyn tietokantaan. Osannet tehdä sen jo :). Spring security tarjoaa pääsyn myös muihin autentikaatiomekanismeihin, kts. esim LDAP ja OpenId. Toisaalta, autentikointi esimerkiksi Facebookin, Twitterin tai LinkedInin kautta onnistuu (esim.) Spring Social-projektin avulla.
HTTPS
Usein kommunikointi selaimen ja palvelimen välillä halutaan salata, erityisesti salasanojen lähetyksen yhteydessä.
HTTPS on HTTP-pyyntöjä SSL (nykyisin myös TLS)-rajapinnan yli. HTTPS mahdollistaa sekä käytetyn palvelun verifioinnin sertifikaattien avulla että lähetetyn ja vastaanotetun tiedon salauksen.
HTTPS-pyynnöissä asiakas ja palvelin sopivat käytettävästä salausmekanismista ennen varsinaista kommunikaatiota. Käytännössä selain ottaa ensiksi yhteyden palvelimen HTTPS-pyyntöjä kuuntelevaan porttiin (yleensä 443), lähettäen palvelimelle listan selaimella käytössä olevista salausmekanismeista. Palvelin valitsee näistä parhaiten sille sopivan (käytännössä vahvimman) salausmekanismin, ja lähettää takaisin salaustunnisteen (palvelimen nimi, sertifikaatti, julkinen salausavain). Selain ottaa mahdollisesti yhteyttä sertifikaatin tarjoajaan -- joka on kolmas osapuoli -- ja tarkistaa onko sertifikaatti kunnossa.
Selain lähettää palvelimelle salauksessa käytettävän satunnaisluvun palvelimen lähettämällä salausavaimella salattuna. Palvelin purkaa viestin ja saa haltuunsa selaimen haluaman satunnaisluvun. Viesti voidaan nyt lähettää salattuna satunnaislukua ja julkista salausavainta käyttäen.
Käytännössä kaikki web-palvelimet tarjoavat HTTPS-toiminnallisuuden valmiina, joskin se täytyy ottaa palvelimilla käyttöön. Esimerkiksi Herokussa HTTPS:n saa käyttöön komennolla heroku addons:add piggyback_ssl. Lisätietoa Herokun SSL-tuesta osoitteessa https://devcenter.heroku.com/articles/ssl-endpoint.
OWASP
OWASP (Open Web Application Security Project) on verkkosovellusten tietoturvaan keskittynyt kansainvälinen järjestö. Sen tavoitteena on tiedottaa tietoturvariskeistä ja sitä kautta edesauttaa turvallisten web-sovellusten kehitystä. OWASP-yhteisö pitää mm. yllä listaa merkittävimmistä web-tietoturvariskeistä. Vuoden 2013 lista on seuraava:
Eräs askelista, jota emme vielä ole ottaneet, on näytettävän datan siistiminen (ei liity kohtaan 6, mutta ainakin kohtiin 1, 3, 8). Tähän asti JSP-sivuillamme näytetty data on oikeastaan voinut sisältää myös HTML-koodia, mikä on mahdollistanut erilaistan kiusojen (hyökkäysten) suorittamisen. JSP-sivujen jstl-tägikirjasto tarjoaa tähän helpon ratkaisun: käyttämällä elementtia c:out datan tulostamiseen, muunnamme mm. kaikki <-merkit muotoon ∧lt;, jolloin ne näkyvät sivulla oikein, mutta niiden sisältämää koodia ei suoriteta.
Käytännössä JSP-sivuilla tulee siis muuntaa tulostukset "${data}" muotoon <c:out value="${data}"/>.
MovieDatabaseRevisited
Muokkaa sivuja actors.jsp, actor.jsp, ja movies.jsp siten, että estät tietokantaan jotain kautta lisätyn XSS-hyökkäyksen. Muokkaa tässä vain JSP-sivuja.
Kun olet valmis, palauta tehtävä TMC:lle.
CORS
HTML-sivuilla olevien JavaScript-koodien tekemiä pyyntöjä rajoittaa ns. "Same origin policy", jolla pyritään rajoittamaan muunmuassa pyynnön mukana lähetettävän datan (evästeet, kirjautumistiedot ym.) päätymistä vääriin käsiin. Sivustot, jotka koostavat useampia palveluita yhteen kuitenkin tarvitsevat pääsyn ulkopuoliseen dataan.
W3C työskentelee CORS (Cross-origin resource sharing)-spesifikaation kanssa parhaillaan. CORS-spesifikaation tavoitteena on määritellä tuki domain-riippumattomalle resurssien jakamiselle. Käytännössä tuki vaatii sen, että palvelinohjelmiston vastauksessa on otsakkeet, jotka kertovat osoitteet, joissa haettua dataa voi käyttää.
Toistaiseksi Spring ei tarjoa komponenttia CORS-kyselyjen sallimiseksi, mutta esimerkiksi Jetty tarjoaa filtterin CORS-tuen asettamiseen, joka sopii kaikille Java-palvelinohjelmistoille.
Internationalisointi ja lokalisointi
Internationalisoinnilla (i18n) tarkoitetaan sovelluksen rakentamista siten, että sen toteuttaminen usealla kielellä on mahdollista. Lokalisoinnilla (l10n) taas tarkoitetaan yksttäiselle kieli- tai kulttuurialueelle tehtävää kielitoteutusta.
Sovellusta internatinalisoidessa luodaan oletuskieli, joka ylikirjoitetaan erillisillä lokalisaatioilla. Sovelluksessa lopulta käytettävän kielen valinta tapahtuu ympäristön tai erillisen parametrin avulla. Esimerkiksi Javassa on käytössä Locale-luokka, joka sisältää määrittelyt eri maiden kielille.
Käytännössä internationalisaatio alkaa määrittelemällä sovellukseen viestikohtaiset tägit. Tägeille tehdään kielikohtaiset resurssitiedostot, josta kielikohtaiset tekstit haetaan tägien paikalle. Lokalisoidun käyttöliittymän luominen tapahtuu siis käytännössä tägien ja resurssitiedostojen perusteella.
Javassa on valmiina ResourceBundle-luokka, jota voi käyttää resurssien hakemiseen. Käytännössä resurssit ovat kielikohtaisissa properties-tiedostoissa. Esimerkiksi luokan ResourceBundle staattisella metodilla getBundle haetaan resursseja tietyllä kielellä.
ResourceBundle resources = ResourceBundle.getBundle("resources", new Locale("fi", "FI"));
Hakee suomenkielisiä resursseja resources-tiedostosta. Käytännössä käytettävän tiedoston nimi yritetään päätellä annettavista parametreista, tarkempi sopivan tiedoston päättelyn kuvaus löytyy getBundle-metodin API-kuvauksesta.
Lokalisaatiotiedoston resources_fi.properties sisältö voi olla esimerkiksi seuraavanlainen:
welcome=Tervetuloa {0}!
currentTime=Tänään on {0} ja kello on {1}.
Aaltosuluilla merkityillä tägeillä merkitään kohdat, johon voidaan lisätä muita parametreja. Esimerkiksi viestin welcome näyttäminen onnistuu Java-ohjelmassa MessageFormatter-luokan avulla seuraavasti.
Koska dependency injection on jees, ja tämänkin voi tehdä hieman helpommin, käytämme jatkossa Springiä.
Spring-sovellusten lokalisointi
Spring tarjoaa erillisen luokan viestien hakemiseen. Luokka ResourceBundleMessageSource osaa hakea tarvittavat resurssitiedostot sille konfiguroitavasta polusta. Esimerkiksi alla määrittelemme, että lokalisaatiotiedostot alkavat sanalla resources ja sijaitsevat sovelluksen juuripolussa. Käytännössä lokalisaatiotiedostot (esim. resources_fi.properties) asetettaisiin kansioon src/main/resources, josta ne kopioidaan sovellusta käännettäessä oikeaan paikkaan.
Nyt Springillä on käytössä viestien lataamiseen tarvittava luokka. Jos sovellus ladataan oliokontekstin kautta, voi sen injektoida osaksi sovellusta.
@Component
public class MyApplication {
private Locale locale;
@Autowired
private MessageSource messageSource;
public void setLocale(Locale locale) {
this.locale = locale;
}
// ...
}
Itse viestien käyttäminen on myös hieman helpompaa. Sovellus lataa käynnistyessään kaikki lokalisoidut tiedostot ja käytettävän tekstin päättely tapahtuu koodissa. Esimerkiksi aiemman welcome-tekstin tulostus tapahtuu seuraavasti:
// ...
String name = "Arto";
System.out.println(messageSource.getMessage("welcome", new Object[] { name }, locale));
// ...
Tulostettaville viesteille määritellään siis oma tägi, käytettävät parametrit, ja käytettävä kieli.
Web-sovellusten internationalisointi
Web-sovellusten internationalisointi tapahtuu samalla lähestymistavalla kuin komentorivisovelluksen lokalisointi. Käyttöliittymätekstit muutetaan tageiksi, ja lokalisoidut tekstit tallennetaan niille sopivaan paikkaan. Web-sovellusten lokalisointiin käytetään usein luokkaa ReloadableResourceBundleMessageSource, joka toimii lähes samoin kuin aiemmin näkemämme ResourceBundleMessageSource. Itse konfiguraatio asetetaan esimerkiksi osaksi spring-base.xml-tiedostoa.
Alla on määritelty konfiguraatio, joka hakee resources-nimisiä resurssitiedostoja sovelluksen juuripolusta. Tiedostot kopioidaan juuripolkuun kansiosta src/main/resources. Tämän lisäksi konfiguraatiolle on määritelty oletusmerkistöksi UTF-8.
Jotta web-sovellus osaisi pitää kirjaa käytettävästä kielestä, tallennetaan valittu kieli evästeeseen. Spring tarjoaa tähän tarkoitukseen valmiin luokan CookieLocaleResolver. Alla olevassa konfiguraatiossa on lisäksi määritelty oletuskieleksi englanti.
Sovelluksen kielen vaihtaminen onnistuu lisäämällä ylimääräinen käsittelijä. Web-sovelluksiin kohdistuviin pyyntöihin voidaan määritellä (Javan standardilähestymistavan, eli filttereiden) lisäksi interceptor-olioita. Luokka LocaleChangeInterceptor prosessoi palvelimelle tulevat pyynnöt, ja vaihtaa kieltä tarvittaessa. Käytännössä kielen vaihto tapahtuu esimerkiksi lisäämällä polkuun parametri locale. Esimerkiksi pyyntö osoitteeseen http://..sovellusjne../polku?locale=fi vaihtaa kieleksi suomen.
Tägikirjastoa käytetään seuraavasti. Attribuutin code arvo on aina näytettävän viestin avain. Attribuutille code lisätään argumentteja attribuutin arguments avulla.
Euroopan Unionin kielikomissio haluaa selvittää kuinka monta EU-jäsenmaan kansalaista osaa puhua ranskaa. Web-sovellusta varten on luotu prototyyppi, johon on kovakoodattu englanninkielinen versio sovelluksesta. Hyvä ystäväsi Jean-Jacques-Antoine Courtois Van Damme on ystävällisesti suunnitellut kielitiedostoissa käytettävät avaimet ja tehnyt ranskankielisen käännöksen sovellukseen vaadittavista ranskankielisistä ja englanninkielisistä viesteistä. Löydät tiedostot Netbeansistä Other Sources-kansion alta polusta src/main/resources/bundles/.
Konfiguraatio
Muokkaa konfiguraatiotiedostoa spring-base.xml ja lisää sinne seuraavat konfiguraatiot:
Konfiguroi bean org.springframework.web.servlet.i18n.CookieLocaleResolver ja aseta sille defaultLocale:ksi englanti
Tiedostossa valmiina oleva konfiguraatio mahdollistaa uudestaan ladattavien property-tiedostojen (tässä tapauksessa kielitiedostojen) käytön. Ensimmäiseksi lisättävä konfiguraatio asettaa nykyisen lokaalin evästeen avulla ja toinen konfiguraatio vaihtaa lokaalin (ja evästeen) kun sovelluksessa mihin tahansa polkuun lisätään parametri ?locale=KIELIKOODI.
Näkymien internationalisointi
Sinun täytyy tehdä lokalisaatiotiedostot suomenkielistä lokalisaatiota varten. Katso mallia tarjotusta ranskankielisestä (tai englanninkielisestä) lokaalisaatiotiedostosta. Lokalisoi nyt näkymät question.jsp, yes.jsp ja no.jsp käyttämään tiedostoissa määritettyjä viestejä.
Testaa lopuksi sovellus huolellisesti selaimessa. Voit vaihtaa kielen lisäämällä mihin tahansa polkuun parametrin ?locale=KIELIKOODI. Asetus muistetaan evästeen avulla.
Omat siivet (ThymeSiivet)
Tässä vaiheessa pystyt hyvin todennäköisesti käymään läpi webissä olevia (Spring-)tutoriaaleja. Tässä tehtävässä tutustutaan kolmannen osapuolen näkymäkomponenttiin, sekä laajennetaan hieman heidän tarjoamaa pohjaa. Tehtävä on kokonaisuudessaan viiden (5) pisteen arvoinen -- testejä ei ole, joten kun palautat tehtävän, vakuutat että olet tehnyt sen ohjeiden mukaisesti ja että se toimii.
Tehtäväpohjassa on ladattuna viimeiseen dokumenttiin liittyvä projektipohja.
Muokkaa projektia siten, että istutustoiminnallisuuden sijaan projektissa pidetään kirjaa oluiden maistelusta.
Kirjauksissa tulee tallentaa jokaisesta maistelusta seuraavat tiedot:
Päivämäärä
Oluen tyyppi, vaihtoehtoina seuraavat:
Ale
Kvass
Lager
Sahti
Wheat Beer
Makuominaisuudet (yksi tai useampi seuraavista):
Pronounced malt
Roasted
Chocolate
Coffee
Sweet
Bitter
Silky Thin
Chewy Thick
Pullotettu vai ei
Arvosana (asteikolla 1-5)
Tehtävästä ei ole myöskään yksittäistä mallivastausta, mutta vaihtoehtoisista ratkaisuista voi keskustella vastuuhenkilön kanssa esimerkiksi koetilaisuudessa.
Voit palauttaa tehtävän myös siten, että toteutat vain ensimmäiset kolme osaa (3p) (käyttöliittymässä vain päivämäärä, oluen tyyppi ja makuominaisuudet). Kirjoita tällöin tehtävää palautettaessa kommentteihin osat, jotka toteutit.
le end?
Far from it
Kurssi on oikeastaan ollut vain pikainen katsaus palvelinohjelmointiin, ja seuraavat askeleet tulee ottaa itse (tai esimerkiksi keväällä järjestettävällä Web-palvelinohjelmointi: Ruby on Rails -kurssilla (vink vink)). Kurssille olisi voinut ottaa vielä paljon sisältöä, mutta tässä pyrittiin hakemaan tasapainoa, jolla perusteista tulee jotakuinkin kokonainen kuva. Muunmuassa seuraaviin asioihin olisi voinut käyttää reilusti lisää aikaa (kannattaa etsiä webistä lisätietoa):
WebSocketit (ei vieläkään täysin toimiva konsepti, mutta komponentit kuten SockJS helpottavat toimintaa).
Erilaiset komponentit luokkien korvaamiseen ajonaikaisesti (esimerkiksi JRebel, Spring-Loaded, DCEVM)
Harjoitustyötä voi alkaa tekemään heti kun harjoitustehtäväpohja tulee TMC:hen (ensi viikon alkupuolella). Huom! Pidä TMC:n "Send Snapshots of my Progress of Study"-valintaa päällä -- ohjelmointidatasi päätyy vain tutkimuskäyttöön, eikä omia tietojasi voida yhdistää mahdollisiin tuloksiin.
Koe
Vaihtoehto 1
Kurssilla voi osallistua joko normaaliin (paperimuotoiseen) kurssikokeeseen, joka järjestetään 16.10 klo 9:00 salissa A111. Tällöin tehtävistä saa pisteitä seuraavasti:
Viikko 1, max 4 pistettä
Viikko 2, max 4 pistettä
Viikko 3, max 5 pistettä
Viikko 4, max 5 pistettä
Viikko 5, max 6 pistettä
Viikko 6, max 6 pistettä
Maksimipistemäärän saa keräämällä 90% kunkin viikon tehtäväpisteistä. Kokeesta voi saada 30 pistettä, ja läpipääsyyn vaaditaan vähintään puolet kokeen pisteistä. Arvosanaan 5 vaaditaan noin 55 pistettä, arvosanan 1 saa noin 30 pisteellä.
Vaihtoehto 2
Toinen vaihtoehto on suorittaa kurssi tehtävillä ilman paperikoetta. Tällöin arvosanan 1 saa keräämällä 60% kaikista jaossa olevista tehtäväpisteistä, ja arvosanaan 4 vaaditaan 90% jaossa olevista tehtäväpisteistä. Jos olet tehnyt tehtävistä yli 80%, ja haluaisit korottaa arvosanaasi yhdellä, se on mahdollista osallistumalla erilliseen suulliseen kuulusteluun / keskusteluun. Kuulustelussa keskustellaan kurssin aihepiirin asioista, mahdollisista onnistumis- ja epäonnistumiskokemuksista, sekä siitä, miten kurssia voisi parantaa.
Kurssiteemoista keskustellessa osallistujan tulee näyttää että hän ymmärtää kurssin aihealueet hyvin; esimerkiksi materiaalissa viikkojen välissä olevat kysymykset ovat hyvää pohdittavaa. Kuulustelu kestää noin 30 minuuttia, ja siihen voi varata ajan osoitteessa: https://docs.google.com/spreadsheet/ccc?key=0ArQghZeM1C8wdHlvRFhNd2Jxb1VmdWZXS1N4WjdzN0E&usp=sharing#gid=0. Jos haluat tulla kaverin kanssa, tai teitä on kolme, se on myös ok -- varatkaa tällöin yhteensä tunti.
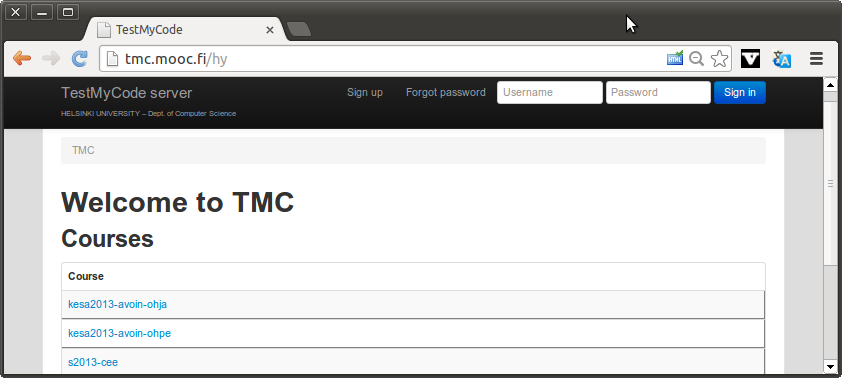
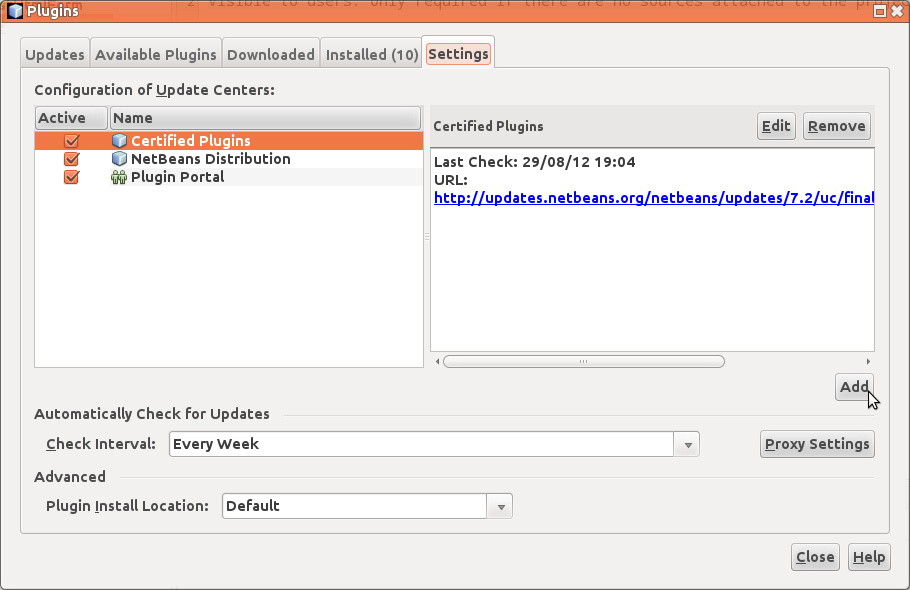
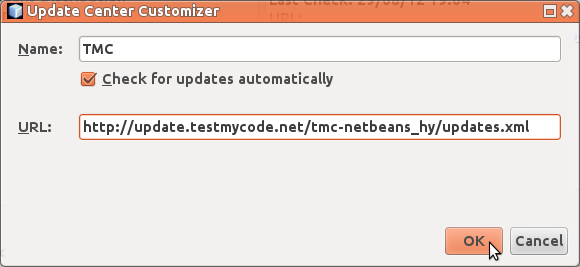
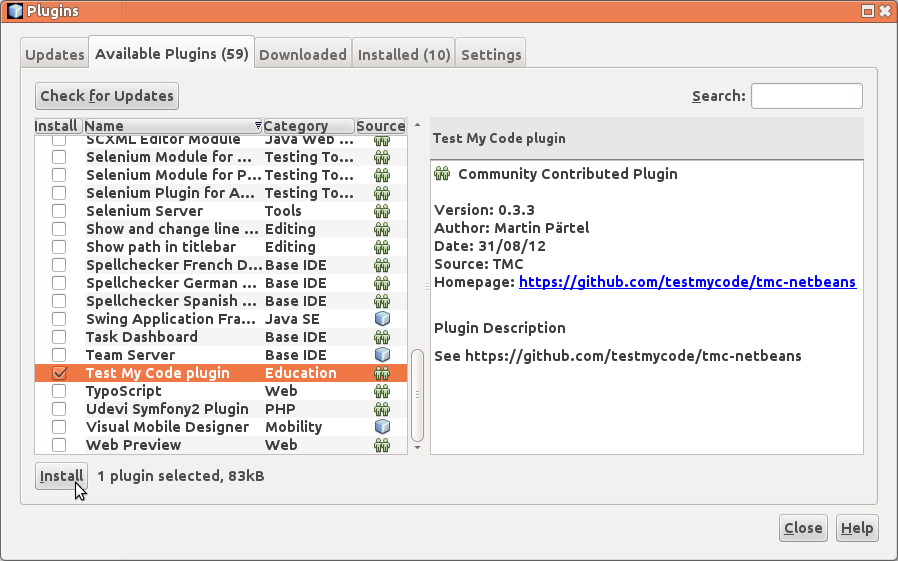
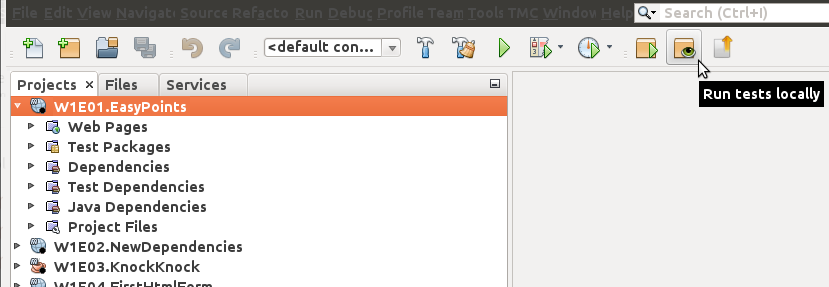
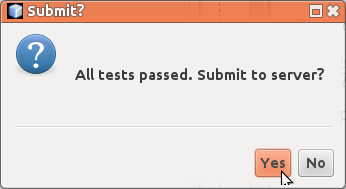
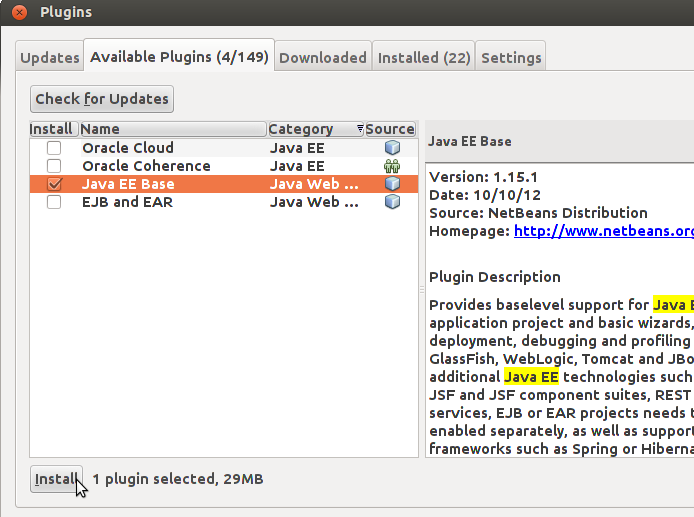
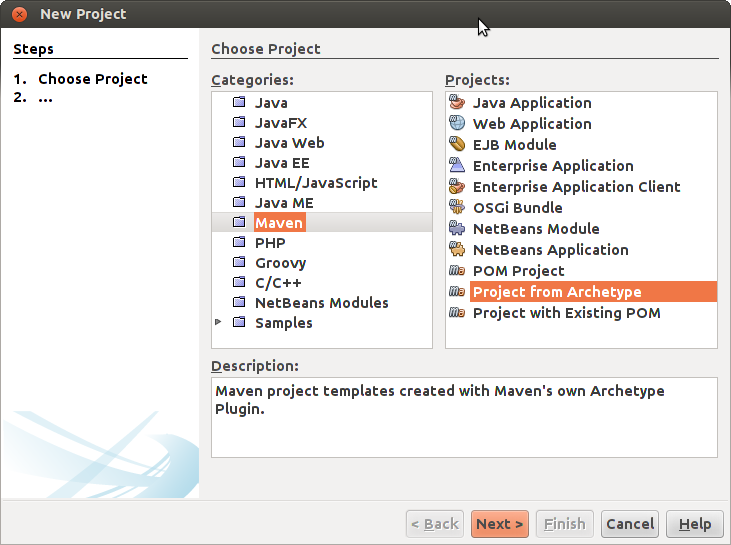

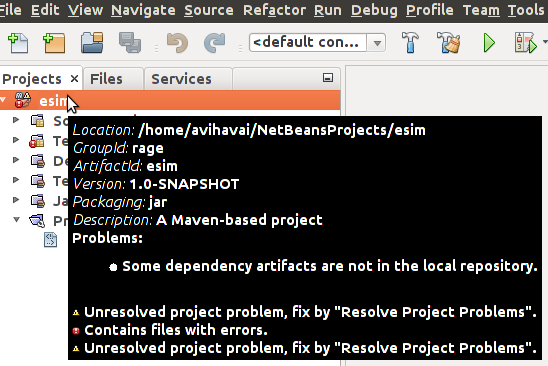
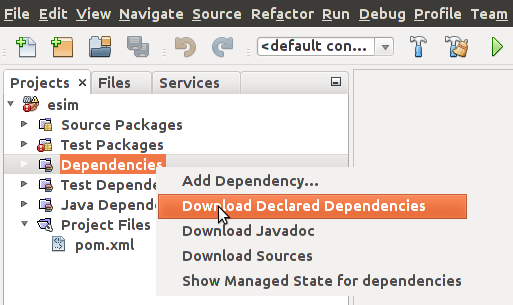
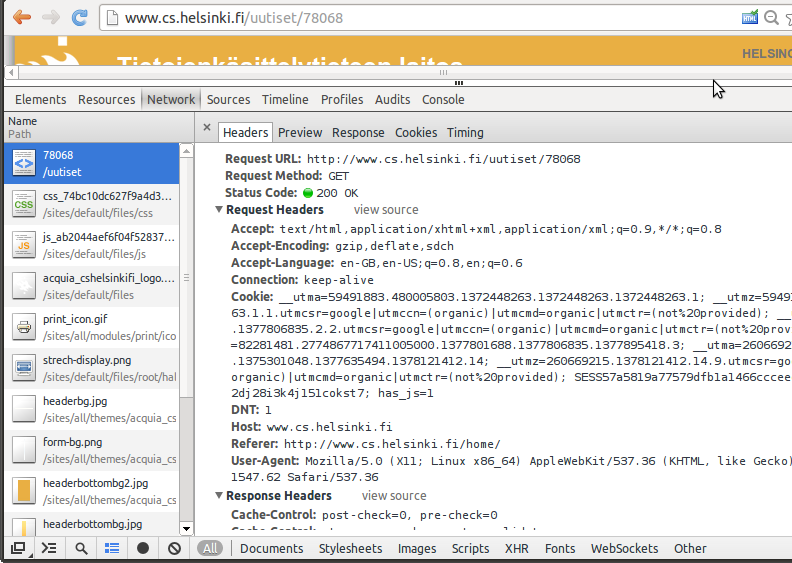

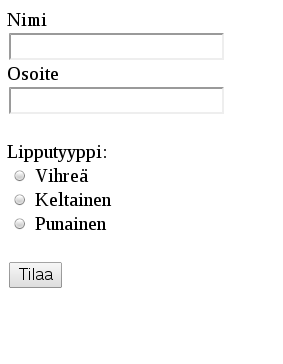
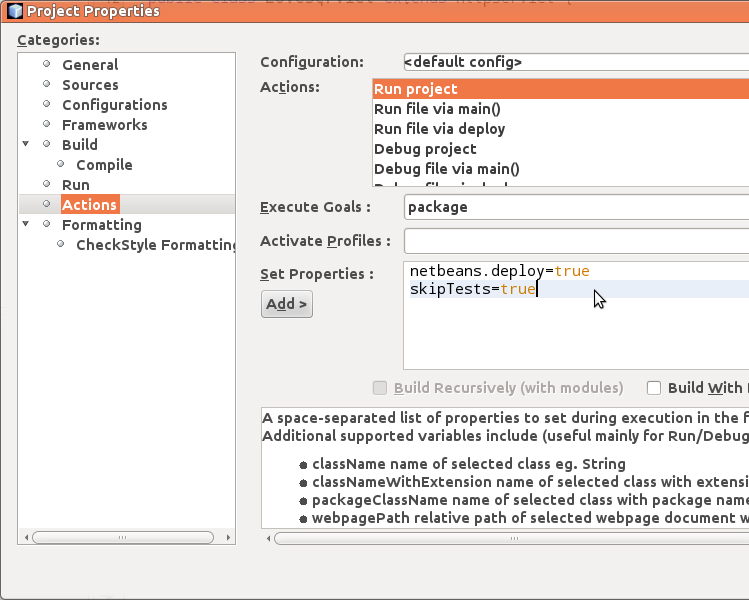
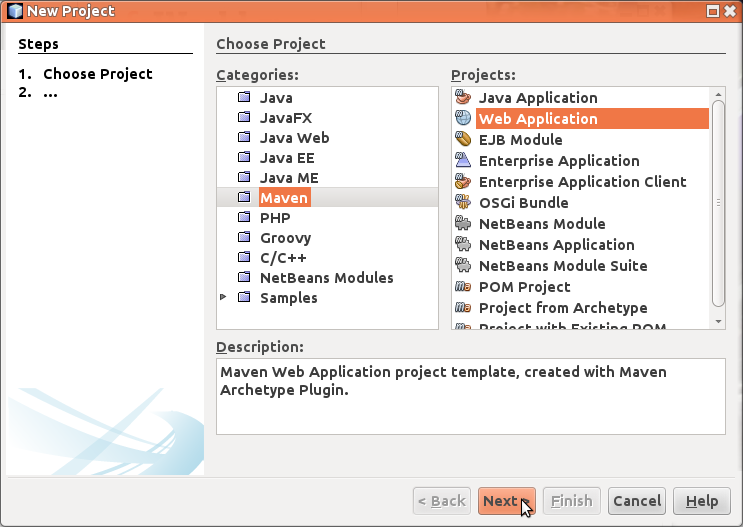
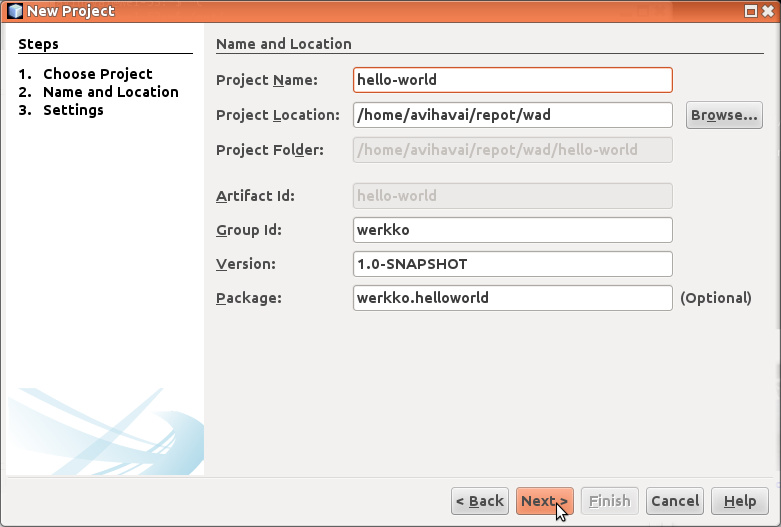
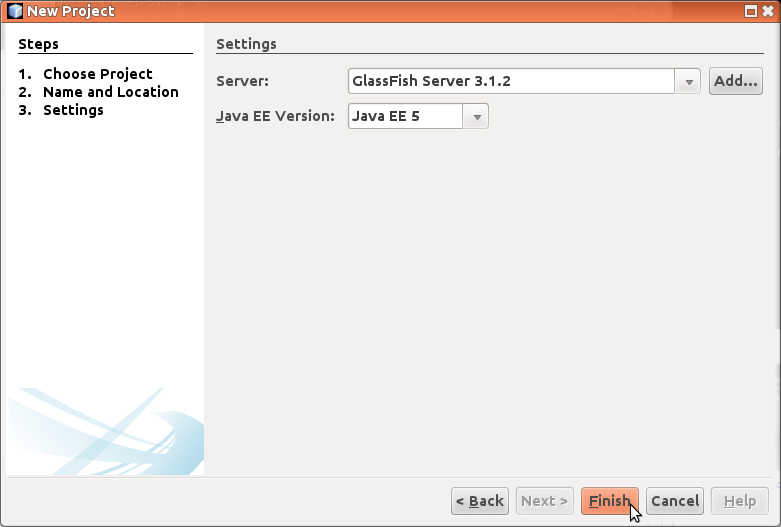
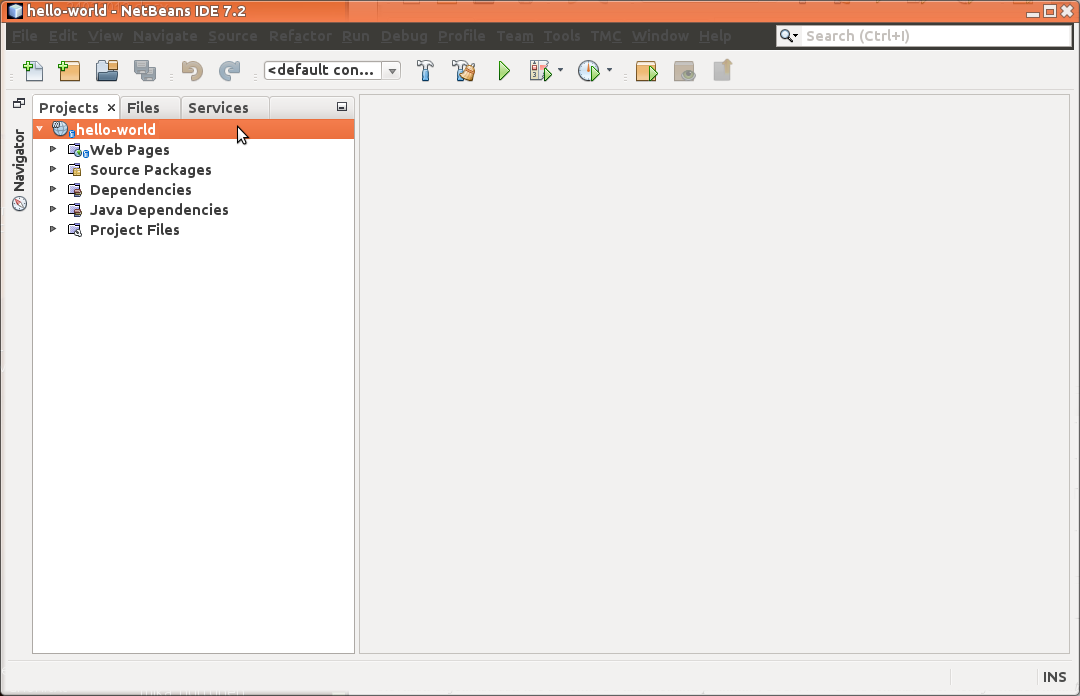
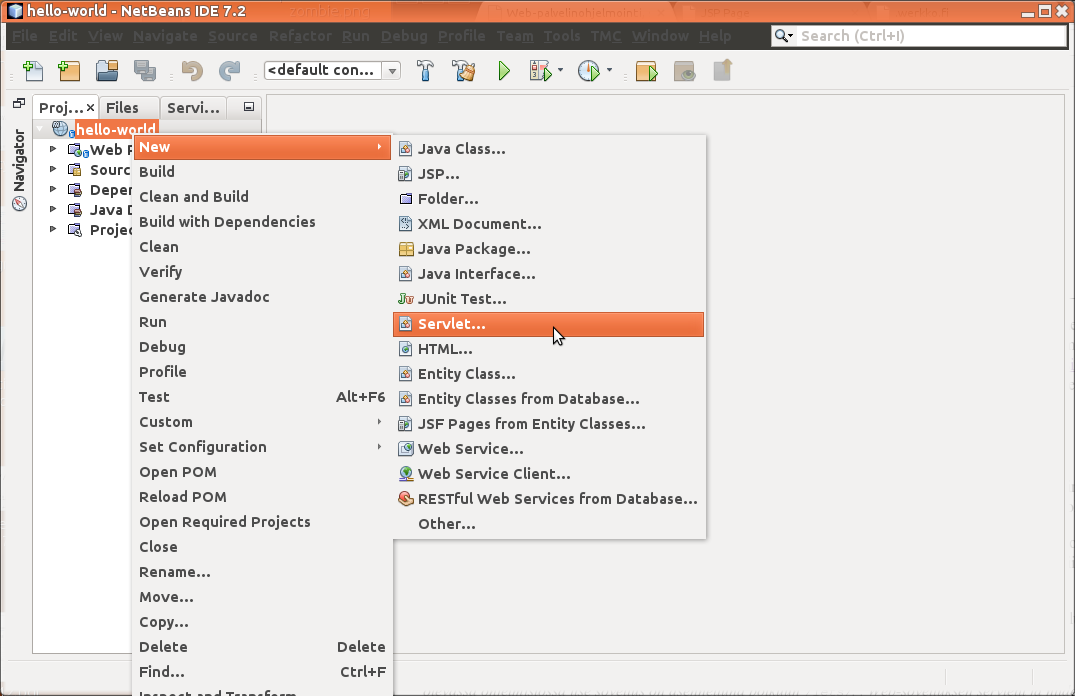
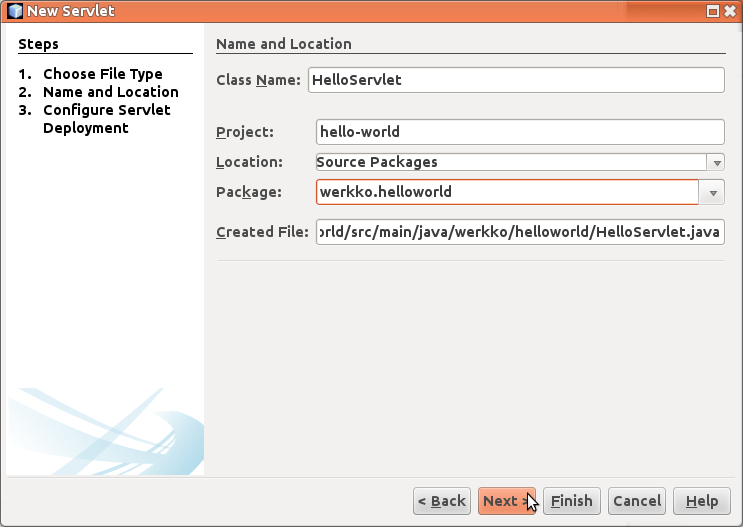
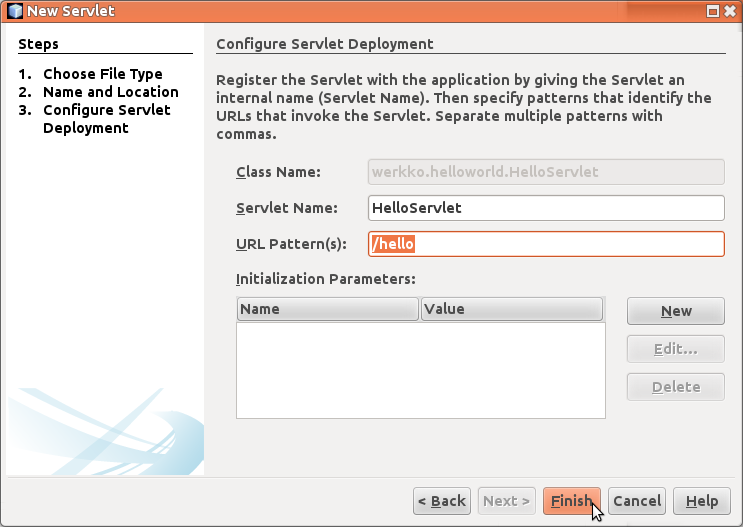
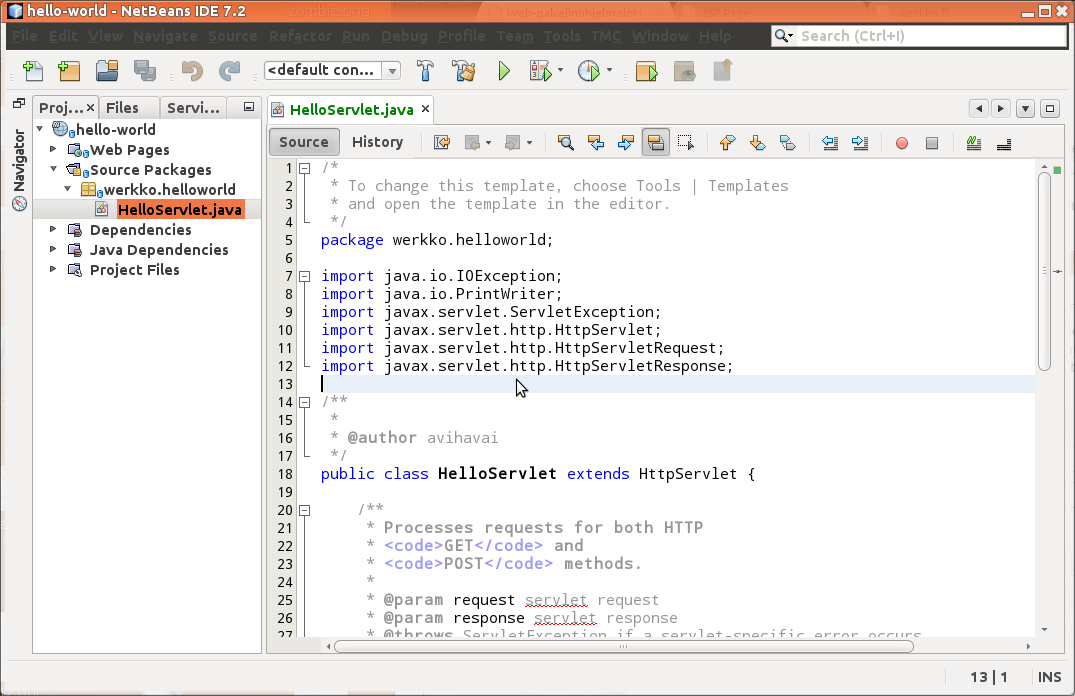
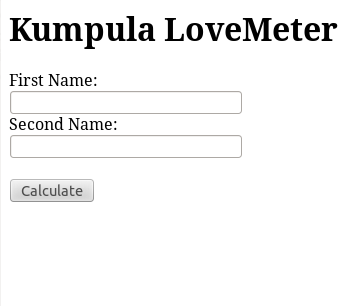



 Donald Knuth : Premature optimization is the root of all evil (or at least most of it) in programming.
Donald Knuth : Premature optimization is the root of all evil (or at least most of it) in programming.