I'm sorry, this reasoning is too flawed to address in detail. I'm a
programmer, not a schoolteacher. I'll drop a hint: "randomness" is not
the right word to use. The way to make a meaningful statement is a
statistical measurement of how close the resulting bucket distributions
are to uniform, as uniform distributions across buckets minimize collisions.
I suggest the usual chi^2 and Kolmogorov-Smirnov (and variants) tests.
The results of these tests are simple: they will compute the
probability that the difference between the measured distribution and a
true uniform distribution could not have occurred by chance (i.e.
whether its difference from the uniform distribution is statistically
significant). With these things in hand you should be able to make more
meaningful assertions about your hashing algorithms.
Cheers,
Bill
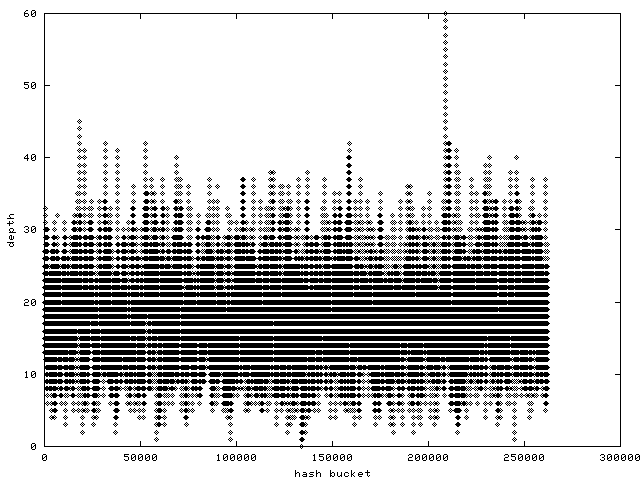
P.S.: The quality (or lack thereof) of this hash function is already
visible in histograms of the pagecache bucket distribution on
larger systems. Statistical measurements of its quality reflect
this very clearly as well. Someone needs to move the stable out
of the Sahara and closer to a lake.
http://www.samba.org/~anton/linux/pagecache/pagecache_before.png
is a histogram of the pagecache hash function's bucket distribution
on an SMP ppc64 machine after some benchmark run.
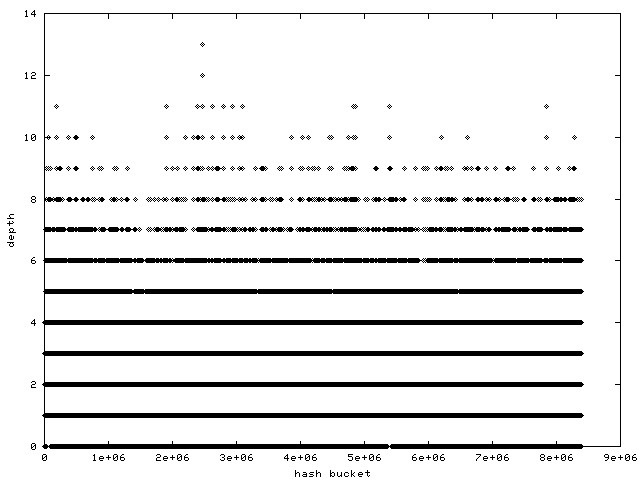
http://www.samba.org/~anton/linux/pagecache/pagecache_after.png
has a histogram of a Fibonacci hashing hash function's bucket
distribution on the same machine after an identical benchmark run.
(There is more to come from the hash table analysis front.)
-
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to majordomo@vger.kernel.org
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
{kind=link}
{kind=link}