Well, that's the same reasoning behind the hashfn that everybody using
linux computes at every read syscall. I didn't invented it, I only told
you what's the reasoning behind it.
btw, some year back also Chuck Lever did an very interesting extensive
research on hashing and he just evaluated the multiplicative hash
method.
The critical thing that araised from Chuck's extensive research on the
hashes is been the dynamic sizing of the hashes as boot. the hashfn
weren't changed. If we could have exploited a huge performance
optimization and if the current hashfn would been flawed how could you
explain that the hashfn are still unchanged? Because Linus dropped the
email with the patches and those emails weren't resent? Then why didn't
somebody piked them up in a different benchmark tree?
Said that I agree that for the pagecache hash, there could be
interesting patterns in input. If the inodes are allocated at nearly the
same time after boot, and you work on large files, then you'll likely
generate lots of collisions that may be avoided by the multiplicatve
hash. So it's not optimal for the big files handling only a few inodes.
But note that this email thread is about the wait_table hash, not the
pagecache hash, they're two completly different beasts, even if the
reasoning behind them is the same one.
> programmer, not a schoolteacher. I'll drop a hint: "randomness" is not
I studied the multiplicative hashes (i recall the div method) in
Introduction to Algorithms and what I think about them is that those
hashfns are been designed to work well in presence of non random
patterns in input. One example of an hashfn in linux that doesn't get
significantive random input, is the buffer cache hash. That's indexed
by offset and the blkdev. the blkdev is just fixed, no matter if it's a
pointer or a major/minor. The offset will definitely have huge patterns
that can lead to bad distribution (just like the "offset" in the
pagecache hash). I recall Chuck noticed that, and infact the hashfn of
the buffercache is the only one that I'm sure it's been replaced because
it was bad.
See what it become now:
#define _hashfn(dev,block) \
((((dev)<<(bh_hash_shift - 6)) ^ ((dev)<<(bh_hash_shift - 9))) ^ \
(((block)<<(bh_hash_shift - 6)) ^ ((block) >> 13) ^ \
((block) << (bh_hash_shift - 12))))
For the pagecache hashfn similar collisions can happen with big files and
only a few inodes allocated right after boot. The current pagecache hash
is optimal on the small files, like simultaneous kernel compile + kde
compile + gcc compile etc....
Also note that one thing that math doesn't contemplate is that it may be
faster to handle more collisions on a hot L2/L1 cache, rather than not
having collisons but to constantly run at the speed of the DRAM and the
current hashes definitely cares a lot about this bit. I only see you
looking at the distribution on the paper and not at the access pattern
to memory and cache effects.
But anyways we're not talking about the pagecache has here, the
randomness of the input of the wait_table isn't remotely comparable to
the randomness of the input of the pagecache hash: after load the free
pages in the freelists will become completly random, and if there's a
probability, the probability is that they're contigous (for example when
a kernel stack gets released for example, and two page of pagecahce gets
allocated while reading a file, and then we wait on both, and we want
both waitqueues in the same cacheline). It's not like with the
pagecacache that you can artificially generate collisions easily by
working on big files with two inodes allocated right after boot. Here
the pages are the random input and we can't ask for something better in
input for an hashfn.
If you assume a pure random input, I don't see how can you distribute it
better with a simple mul assembler instruction. That's my whole point.
Now if intuition doesn't work here, and you need a complex math
demonstration to proof it, please give post a poiner to a book or
pubblication and I will study it, I definitely want to understand how
the hell could a "mul" distribute better a pure random input because
intuitions tells me it's not possible.
> the right word to use. The way to make a meaningful statement is a
> statistical measurement of how close the resulting bucket distributions
> are to uniform, as uniform distributions across buckets minimize collisions.
> I suggest the usual chi^2 and Kolmogorov-Smirnov (and variants) tests.
>
> The results of these tests are simple: they will compute the
> probability that the difference between the measured distribution and a
> true uniform distribution could not have occurred by chance (i.e.
> whether its difference from the uniform distribution is statistically
> significant). With these things in hand you should be able to make more
> meaningful assertions about your hashing algorithms.
>
>
> Cheers,
> Bill
>
> P.S.: The quality (or lack thereof) of this hash function is already
> visible in histograms of the pagecache bucket distribution on
> larger systems. Statistical measurements of its quality reflect
> this very clearly as well. Someone needs to move the stable out
> of the Sahara and closer to a lake.
>
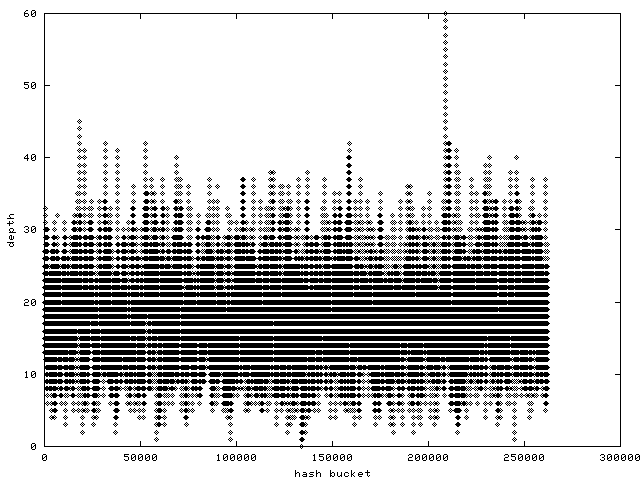
> http://www.samba.org/~anton/linux/pagecache/pagecache_before.png
>
> is a histogram of the pagecache hash function's bucket distribution
> on an SMP ppc64 machine after some benchmark run.
>
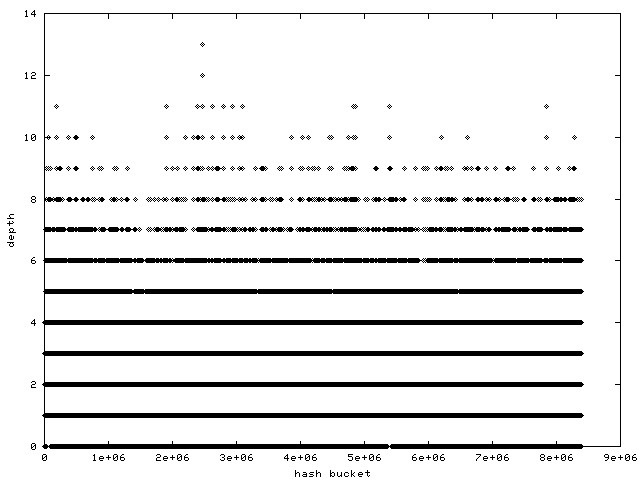
> http://www.samba.org/~anton/linux/pagecache/pagecache_after.png
>
> has a histogram of a Fibonacci hashing hash function's bucket
> distribution on the same machine after an identical benchmark run.
>
> (There is more to come from the hash table analysis front.)
from the graphs it seems the "before" had 250000 buckets, and the
"after" had 8 million buckets. Is that right? Or were all the other
8millions - 250000 buckets unused in the "before" test, if yes, then you
were definitely not monitorning a misc load with small files, but of
course for such a kind of workload the fibonacci hashing would very well
be better than the current pagecache hash, I completly agree. the
"after" graph also shows the hash is sized wrong, that's because we're
not using the bootmem allocator, Dave has a patch for that (but it's
highmem-not-aware still). btw, it's amazing that the hash is almost as
fast as the radix tree despite the fact the hash can at max be 2M in
size currently, on a >=4G box you really need it bigger or you'll be
guaranteed having to walk a bigger depth than the radix tree.
Andrea
-
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to majordomo@vger.kernel.org
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
{kind=link}
{kind=link}