
Perf. Eval., Homework 4 (due 10.4.2002)
- Prove that formula 7-1 in Lecture 7 is correct:
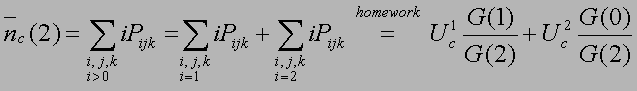
- Give examples on when normalization constant G could overflow/underflow.
How can you avoid this problem?
- Assume that your system has a dual-processor CPU. How does that change the
ABA and BJB bounds computations?
- [2 htp] A computer system has one CPU and two disks (disk1 and
disk2). System was monitored for one hour and utilization of CPU and disk1
were found to be 32% and 60%, respectively. Each transaction makes 5 I/O
requests to disk1, and 8 I/O requests to disk2. Average service time to
disk1 is 30 msec, and to disk2 25 msec. [Men 94, p. 173].
- Find the system throughput.
- Find disk2 utilization.
- Find average service demands at each device.
- With MVA, find system throughput, response time and average queue lengths at each device with mpl=0, 1, 2, 3, and 4.
- What was the average mpl during the original 1 hour measurement interval?
For MVA solution you should use PMVA[Brumfield 81].
An executable copy of PMVA is available as /home/fs/kerola/bin/pmva and it can be executed from most deparmental Linux machines (E.g., melkki, melkinkari). For example, to run model /home/fs/kerola/pmva/ex1.pmva in PMVA you need to login to such machine and execute command
/home/fs/kerola/bin/pmva </home/fs/kerola/pmva/ex1.pmvaA copy of the PMVA manual is available in the course folder in A412.
- [2 htp] Use PMVA to solve the following model exactly.
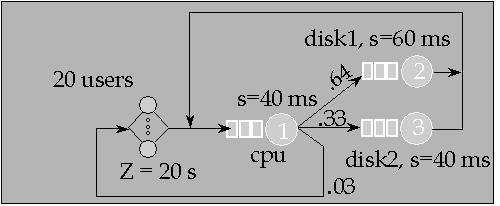
Aggregate I/O subsystem (devices disk1 and disk2) to one load dependent device and solve the aggregate model with PMVA. Compare results to those of exact model. What is good/bad in your aggregate solution?
What does it mean that aggregate model solution is "good"?
Repeat the experiment with just 4 users. Is aggregate solution with this population level better or worse than with population 20? Why?
Teemu Kerola