| Contents |
|
||||
| Reading Material | Elmasri&Navathe: Chapter 8.3.5 (pages 269-274) |
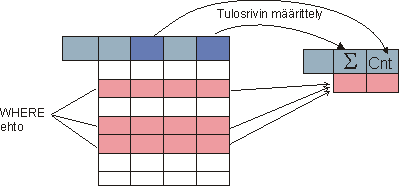
SQL makes it possible to compute summary data over the rows that satisfy the conditions given in the WHERE-part of the query. In summaries this row population may be treated as a single unit or it can be groupped so that summaries are counted for each group.
SQL provides aggregate funcvtions for computing summaries.The traditional ones are listed in the table below. SQL-99 provides more functions, for example standard deviation
| AVG(expression) | average value |
| SUM(expression) | sum |
| MIN(expression) | minimum value |
| MAX(expression) | maximum value |
| COUNT(expression) | count of values |
| COUNT(*) | size of population |
Aggregate functions have an expression as their argument. Sum and average value presuppose an arithmetic expression. The value for the argument expression is counted for each row of the population. If the value is NULL it is ignored.Thus for example COUNT gives the number of rows for which the expression evaluates to some non-null value..
DISTINCT clause may be attached in front of the argument. In this case each distinct value is counted only one in the computation of the summary. This is most useful when used together with the COUNT-function. Then the result will be the number of the distinct values of the expression.. Let's consider the table EXAMPLE below
| A | B | C | D |
| 3 | ABC | NULL | 5 |
| 4 | NULL | NULL | 1 |
| 4 | DEF | 5 | 5 |
| 4 | DEH | 8 | 3 |
| 2 | NULL | NULL | 2 |
| 7 | HUP | 2 | 1 |
| 2 | PUH | 1 | 1 |
This data gives the following values for aggregate functions:
| COUNT(A) | 7 |
| COUNT(DISTINCT A) | 4 |
| COUNT(B) | 5 |
| COUNT(DISTINCT B) | 5 |
| COUNT(C+D) | 4 |
| SUM(C) | 16 |
When summaries are made over the whole population the result of the query will contain only a single row of summary data.
Next example gives the number of deliveries in January 2002.
select count(*) from from delivery wwhere whenDelivered betwen '2002-01-01' and '2002-01-31' |
Column TotalPrice in table Ordered indicates the price of an Order. The following example query, in Oracle SQL, retrieves the number of orders made on January 1st 2002, the total revenue on that date and the percentage of orders paid in cash. Function decode gives the value 1 if payment is by cash and otherwise 0. Thus sum over these values gives the number of orders that have been paid by cash..
select count(*) amount, sum(price) revenue, round(100*sum(to_number(decode(PaymentBy,'cash','1','0')))/count(*),2) pct from ordered where whenMade>'2001-12-31' and whenMade<'2002_01-02; |
It is not possible to retrieve in the same query both summary data computed over the whole population and detail data from some row of the population. The following query fetches the price of the most expensive product.
select max(price) biggest from product |
However, the following query does not give us information on what this most expencive product is. Instead is gives an error message because the query tries to retrieve both detail data and summary data.
select productId, modelId, max(price) biggest from product |
On correct way to find out what the most expensive product is, is to use the following query:
select productId, modelId, price
from product
where price =
(select max(price) from product)
|
Here computing of the summary information is done in a subquery. Althoug bot the outer query and the subquery are based on the table product these are considered as different row populations. Another way to produce the same result is to embed the subquery in the FROM-part of the query. The result table of this subquery is called expensive and it will contain at most one row.
select productID, modelID, biggest
from product,
(select max(price) biggest
from product) as expensive
where product.price = expensive.biggest;
|
The rows that satisfy the query conditions may be divided into groups and summaries counted for each group. The result will then contain one row for each group. The figure below has two groups and thus the number of rows in the result is two.
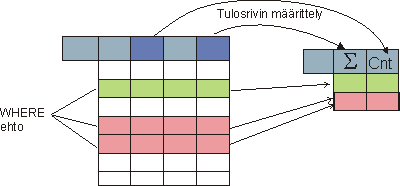
The population for the ummaries iss constructed by first applying the conditions in the WHERE-part. THe groupping is then done on the basis of the columns listed in the GROUP BY -part. Each value combination for the listed columns that existst in the rows of the population determines a group. Let's considet the following table as the population:
| A | B | C | D |
| 3 | ABC | NULL | 5 |
| 4 | NULL | NULL | 1 |
| 4 | DEF | 5 | 5 |
| 4 | DEH | 8 | 3 |
| 2 | NULL | NULL | 2 |
| 7 | HUP | 2 | 1 |
| 2 | PUH | 1 | 1 |
Grupping criterium 'GROUP BY A' divides the population in 4 groups based on the values of column A
| A | B | C | D |
| 2 | NULL | NULL | 2 |
| 2 | PUH | 1 | 1 |
| 3 | ABC | NULL | 5 |
| 4 | NULL | NULL | 1 |
| 4 | DEF | 5 | 5 |
| 4 | DEH | 8 | 3 |
| 7 | HUP | 2 | 1 |
Next table shows the results of tho summary functions apllied on this grouped population.
| count(C) | min(C) |
| 1 | 1 |
| 0 | NULL |
| 2 | 5 |
| 1 | 2 |
Grouping criterium 'GROUP BY C' divides the population into 5 groups:
| A | B | C | D |
| 2 | PUH | 1 | 1 |
| 7 | HUP | 2 | 1 |
| 4 | DEF | 5 | 5 |
| 4 | DEH | 8 | 3 |
| 3 | ABC | NULL | 5 |
| 4 | NULL | NULL | 1 |
| 2 | NULL | NULL | 2 |
and the summary functions give the following results
| MIN(B) | MAX(B) | SUM(D) |
| PUH | PUH | 1 |
| HUP | HUP | 1 |
| DEF | DEF | 5 |
| DEH | DEH | 3 |
| ABC | ABC | 8 |
When grouping is used the result may contain on symmary data and the values of those columns that are used as groupping criteria.
The following query gives information on how many orders each customer has made.
select Name, CustomerId, count(*) from Ordered,Customer where Ordered.Customer=Customer.CustomerID group by Name, CustomerID |
Columns Name and CustomerId form the grouping criterium. Using CustomerID as the criterium would produce the same groups. However, if we use that criteria, we are not able to include customers's name in the result. There is one problem in this query. We do not get any information about such customers who have not made any orderes. This is because the join condition is evaluated first and customers without orders are not included in the result population. We may get rid of this problem by using outer join:
select Name, CustomerId, count(orderID)
from Ordered right outer join Customer on
Ordered.Customer=Customer.CustomerID
group by Name, CustomerID
|
We cannot use count(*) in this query because there is now one row also for those customers taht have not ordered anything. The orderID in these rows is NULL and thus count(OrderID) gives the correct value 0.
Grouping is usually implemented so that the row population is sorted using the columns of the grouping criteria as the sorting key. Thus rows that belong to the same group form a sequence of which it is easy to count the summaries. If we want to be sure that the result is always in the same order we must include the ORDER BY -clause in the query. The following query sorts the customers in descending order by their number of orders.
select Name, CustomerId, count(orderID)
from Ordered right outer join Customer on
Ordered.Customer=Customer.CustomerID
group by Name, CustomerID
order by count(OrderID) descending
|
It is posible to restrict which groups are included in the result. This is done with the HAVING structure. Usually the restriction is based on the value of summary information, for example on the size of the qroup. In the following query we include in the result only such customers that have made orders with more than 100 euros.
select Name, CustomerId, count(orderID)
from Ordered right outer join Customer on
Ordered.Customer=Customer.CustomerID
group by Name, CustomerID
having sum(TotalPrice)>100 order by count(OrderID) descending |
Suppose we want to include only those customers that have used more money for their orders than customers in average. Let's first find out the amount of money used per customer:
select Name, CustomerId, sum(TotalPrice)
from Ordered right outer join Customer on
Ordered.Customer=Customer.CustomerID
group by Name, CustomerID
|
To get the average of these sums we must include this query as a subquery if the from-part of an outer query.
select avg(money_used) from ( select Name, CustomerId, sum(TotalPrice) as money_used
from Ordered right outer join Customer on
Ordered.Customer=Customer.CustomerID
group by Name, CustomerID
) |
The above query may be used in HAVING -part of the query.
select Name, CustomerId, count(OrderID)
from Ordered right outer join Customer on
Ordered.Customer=Customer.CustomerID
group by Name, CustomerID
having sum(TotalPrice)> (select avg(money_used) from ( select Name, CustomerId, sum(TotalPrice) as money_used
from Ordered right outer join Customer on
Ordered.Customer=Customer.CustomerID
group by Name, CustomerID
) ) |