582651 Project in Information-Theoretic
Modeling (2 cr)
Department of Computer Science, University of Helsinki
This is a project following the course Information-Theoretic Modeling.
The course is a pre-requisite so you either need to have taken
the course, or explain convincingly where you have learned the
equivalent skills.
|
- Instructor
- Teemu Roos, A332,
teemu.roos at cs.helsinki.fi
- Teaching assistant
- Anupam Arohi, anupam.arohi at cs.helsinki.fi
Language: All course material and lectures will be in English.
Time: Period II: 3.11.–8.12. Tue 10–12 in C222.
We will have regular meetings on Tuesdays to discuss your progress so far. The meetings are not obligatory unless otherwise stated.
Prerequisites:
- The Information-Theoretic Modeling course
- Good programming skills (no specific language required)
Task
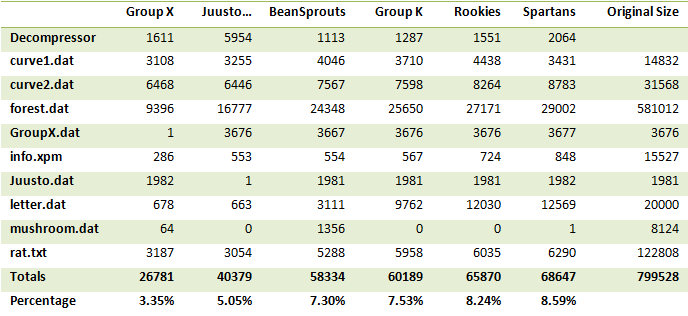
| Compress data. We will give the files to compress, your task is to squeeze them into as small as possible. The catch is that we also count the size of the decompressor program into the total score. |
Your task is to design, document, and implement a compressor and a decompressor program. All imaginable lossless compression methods are allowed. The compression rate of the program will be evaluated with a given set of data files. However, scoring will not be based solely on compression rate. Instead the size of the decompressor program is added to the size of the compressed files. Using too complex a decompressor program (e.g., a la style ''print "data...";'') will not generally be a good idea.
As a special feature, in some cases both the compressor and the decompressor programs have access to side information related to the file to be compressed. Using the side information is not obligatory, but it makes compression significantly easier, thus reducing the size of the compressed file.
Deliverables
Your documentation, due December 11, should describe
the ideas/observations/principles underlying the compressor and the
decompressor algorithms. A complete project is a tar-file (all links
should be relative and all files in the directory returned)
including
» high-level description (in English) of the algorithms,
» program source for both compressor and
decompressor programs.
The documentation can be delivered as a separate tar-file that can be extracted in the same directory as the programs.
You can use any programming language you like, as long as we can run your program on the CS department Linux workstations. You can deliver source code or binaries or a combination of both — as you find best — but it must be possible to run the whole think using the script decompress.sh, as described in the project template.
The form of the report is a WEB-page (the HTML template is included in the project template).
» Download the project template
» Download extra Data for 2nd Round
» Download Updated Project Template with new Data for 3rd Round
» Download extra Data for 3rd Round
If you run into problems, email questions to both the instructor and the teaching assistant.
Evaluation
The performance of your algorithm will be evaluated with the given set of data files. The loss-function is given by:
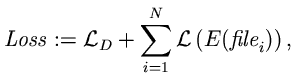
where N is the number of data files,
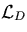 is the size of the decompressor program, and
is the size of the decompressor program, and
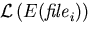 is the size of the compressed version of the ith file.
is the size of the compressed version of the ith file.
The competition is iterative, meaning that there are several deadlines. After each deadline your success is evaluated and scores are published. After each round you are also allowed to submit your own data which will be used in the competition on the remaining rounds. Each group is allowed a variable amount of data, the amount depending on your success on earlier rounds. Because you can probably compress your own data better than other groups it pays off to try to do well already on the first rounds. Project points will be based only on the final round scores though. Details of the data submission procedure are annouced later.
Frequently Asked Questions
- How big can the groups be?
- Groups shouls be 2–3 persons.
- Can we use existing compressors such as gzip or bzip in the script?
- Yes but then you must explain how they work in the report.
- Can I use &mdash library?
- You can use it if it is available in the standard Computer Science Department Linux system. Again, if it is related to compression, you'll need to explain it in the report.
- Can my decompress.sh script access the network?
- No.
- How do we deliver our solution?
- Say "tar czvf groupX_roundY.tgz itmProject" to create a compressed tar file, and send it to Anupam by e-mail. Remember to keep only the required files in folder decompressor.
- Should we deliver source code or binaries in folder decompressor?
- You can decide — whichever is smaller is better. The decompress.sh can include compilation of source code into binary as a preliminary step if you prefer to deliver source code. In either case, remember to deliver the source code in folder src.
- How about the project report?
- You should write the project report as an HTML page (index.html in the template). You only need to deliver the final version of the report after the final deadline, by December 11.
Additional Material
- Compression algorithms
-
- Witten, Neal & Cleary, "Arithmetic coding for data compression", Communications of the ACM, Vol. 30, No 6, pp. 520–540, 1987.
- Cover & Thomas, Elements of Information Theory, Chapter 5
- (see course folder, C127)
- Lelewer & Hirschberg, "Data compression", ACM Computing Surveys, Vol. 19, No. 3, pp. 261–296, 1987.
- David Solomon, Data Compression: The Complete Reference, Springer, 2004, 926 pages
- the title says it all: a comprehensive reference; more recent editions available

|
|
November 3 First meeting (C222); participation obligatory.
November 16 (12 o'clock noon) First deadline. November 23 (12 o'clock noon) Second deadline. November 30 (12 o'clock noon) Third deadline. December 7 (12 o'clock noon) Final code deadline. December 17 (12 o'clock noon) Project Report deadline. |