WWW ja tiedonhaku
Henri Block
Helsinki 10.5.1996
Tieteellisen kirjoittamisen harjoitus 3 (tutkielma)
HELSINGIN YLIOPISTO
Tietojenkäsittelytieteen laitos
Tiivistelmä
WWW ja tiedonhaku
Henri Block
Tieteellisen kirjoittamisen harjoitus 3 (tutkielma)
Tietojenkäsittelytieteen laitos
Helsingin yliopisto
10.5.1996
Hyperteksti mahdollistaa suurten tietomäärien säilyttämisen
tiiviissä muodossa ja tarjoaa menetelmän hakea teksti- ja
visuaalista tietoa nopeasti. Tutkielmassa esitellään tiedonhaun
peruskäsitteet ja kuvataan tärkeimmät etsintämenetelmät, selaus
ja analyyttinen tiedonhaku. Selaus soveltuu paremmin
aloitteleville tiedonhakijoille ja satunnaiseen tiedonhakuun,
mutta World Wide Webin suurten tietomäärien vuoksi analyyttiseen
hakuun pitää turvautua mikäli kaivataan tarkkoja tuloksia.
Suositellaan, että tietoa WWW:stä hakiessa yritetään ensin
löytää tieto hierarkisen hakemiston (esim. Yahoo) avulla ja
täydennetään hakua hakurobotin (esim. Alta Vista) tietokannasta.
Sisältö
- Johdanto
- Peruskäsitteet
- Tiedonhaku
- Käyttöliittymäsuunnittelun periaatteet
- Sijainnin ilmaiseminen
- Erilaiset linkkityypit
- Samankaltaisten artikkelien etsiminen
- Selaus ja erilaiset käyttäjät
- Selaus tiedonhakumenetelmänä
- Aloittelevat tiedonhakijat
- Tietosisältöä tuntemattomat käyttäjät
- Tietosisällön hyvin tuntevat käyttäjät
- Analyyttinen tiedonhaku ja kokeneet tiedonhakijat
- Analyyttisen haun menetelmät
- Kyselyt
- Perinteiset kyselyt
- Sumeat kyselyt ja kynnysmalli
- Vektoriavaruus- ja todennäköisyysmallit
- Kokeneet tiedonhakijat
- Menetelmien vertailu
- Malli tiedonhaulle WWW:stä
- Hierarkiset hakujärjestelmät - Yahoo
- Hakurobotit - Alta Vista
- Vertailu
- Yhteenveto
- Lähteet
1 Johdanto
Jo World Wide Webin (WWW, Web) räjähdysmäisen kasvun vuoksi
hyperteksti on yksi tulevaisuuden tärkeimpiä tiedon
talletusmuotoja. Onkin syytä tarkastella miten tätä tietoa
voidaan hypertekstistä ja WWW:stä erityisesti hakea. Mitkä ovat
tärkeimmät erilaiset hakustrategiat, mitkä ovat syyt niiden
käyttöön ja minkälaisille käyttäjille ne soveltuvat?
Esittelen sekä selausta että analyyttisempaa, täsmällisiin
hakuehtoihin perustuvaa hakua. Lähtökohtana on se, että selaus
soveltuu paremmin kokemattomammille käyttäjille ja analyyttinen
tiedonhaku kokeneille, ammattimaisille hakijoille. Selaus on
myös selvästi epämuodollisempaa ja sopii näinollen paremmin
viihteellisempään, satunnaiseen ja päämäärättömään tiedonhakuun.
Vertailen selaamista tietosisällön kannalta kokemattomien ja
kokeneitten käyttäjien osalta. Lopuksi esittelen mallin
WWW-tiedonhausta ja siihen liittyviä apuvälineitä, kuten
hierarkista hakemistoa ja hakurobottia.
2 Peruskäsitteet
Hyperteksti mahdollistaa suurten tietomäärien säilyttämisen
tiiviissä muodossa ja tarjoaa menetelmän hakea teksti- ja
visuaalista tietoa nopeasti. Hypertekstijärjestelmät tarjoavat
apua ihmisen tiedonhakuun ja -käsittelyyn liittyvien
ajatusmallien tehostamiselle, mikä on tärkeää nykyisen tiedon
sekä määrän, että monimutkaisuuden kasvaessa nopeasti.
Hyperteksti parantaa oleellisesti perinteisten
tekstitietokantojen ja painettujen teosten saantikohtien kuten
hakemistojen ja viitteiden toteuttamista. Hyperteksti tarjoaa
myös runsaasti uusia saantikohtia, joista WWW:kin tukee mm.
elektronisia kirjanmerkkejä ja historialistoja. Uuden
tutkimuksen aiheena ovat nykyään graafiset kartat ja muut tavat
visualisoida verkon rakennetta sekä kokonaisuutena, että
kuljettujen linkkien osalta. Webin hajautetun rakenteen vuoksi
siihen ei voida soveltaa kaikkia samoja tiedonhakutapoja kuin
keskitettyihin hypertekstijärjestelmiin. Esimerkiksi cd-romilla
toimitettaviin tietosanakirjoihin on niiden rajallisuuden ja
muuttumattomuuden vuoksi helppo suorittaa täydellinen
tekstihaku, mutta Internetin laajuuden sekä verkkoyhteyksien
hitauden ja epävarmuuden johdosta WWW:ssä tieto ehtii muuttua
olennaisesti ennen vastaavan haun vastausten saantia.
Hypertekstin sisäiset linkit helpottavat myös eri artikkelien
välisten yhtäläisyyksien etsimistä.
2.1 Tiedonhaku
Ennen tietokoneitten tuomaa automaatiota tiedonhaku perustui
alan ammattilaisten ylläpitämiin hakemistoihin [Bär85].
Ongelmana oli esimerkiksi kirjastoissa, että hakuja pystyi
tekemään vain yhden hakusanan perusteella kerrallaan. Koska
synonyymeihin ja toisiinsa liittyviin termeihin perustuvia
hakuja ei voinut tehdä, niin haut eivät tuottaneet parasta
mahdollista tulosta, vaikka tietoa olisikin ollut saatavilla.
Tiedon määrän kasvu vain suurensi näitä ongelmia.
Tietokoneistettu tiedonhaku helpotti täsmällisempää tiedon
löytämistä, mutta kun WWW on tehnyt kaikista Internetin
käyttäjistä tiedontuottajia, niin informaatiotulva on saanut
aivan uudet mittasuhteet. Tarvitaan tehokkaita hakumenetelmiä ja
-järjestelmiä, jotta tämä tietomäärä pystytään hyödyntämään.
Bärtschin [Bär85] mukaan tiedonhaun tutkimus jakautuu neljään
keskeiseen alueeseen:
-
Sisällön tutkimus on kiinnostunut dokumentin sisällön
luonnehtimisesta, automaattisesta indeksoinnista ja siitä kuinka
tietokoneet saadaan ymmärtämään luonnollista kieltä
-
Tiedon rakenteiden tutkimus etsii suhteita tietosolmujen
kuvaajien (esim. avainsanojen) välillä. Alalla mallinnetaan
sanastojen ja luokitusten käyttöä
-
Kyselyn muodostamisessa ollaan kiinnostuneita siitä, kuinka
tiedontarve parhaiten ilmaistaan, kuinka tiedon rakenne tulisi
esittää sekä siitä, millaisia kyselytermejä tulisi käyttää ja
millaisin operaatioin niitä voisi yhdistellä. Lisäksi
vertaillaan aloittelijoiden ja kokeneempien käyttäjien tekemiä
kyselyitä.
-
Kyselyn arviointi etsii parhaita tapoja vastata kyselyyn. Miten
löydetään kyselyn perusteella kysyjälle tarpeelliset ja vain
tarpeelliset tiedot?
2.2 Käyttöliittymäsuunnittelun periaatteet
Tiedonhaussa, kuten kaikissa muissakin sovelluksissa, täytyy
esitystapaan ja ulkoasuun kiinnittää erityistä huomiota [Erk95].
Oleellista on, että tieto ja järjestelmän omat ominaisuudet
kuten WWW:ssä linkit esitetään koko ajan yhdenmukaisesti.
Käyttäjän mentaalinen kuormitus on minimoitava. Hänen silmilleen
ei saa kerralla työntää liian suurta informaatiotulvaa ja
turhien tehosteiden käyttöä pitäisi välttää. On tärkeää, että
informaatio tarjotaan käyttäjälle valmiiksi jäsenneltynä,
mahdollisimman selkeässä, helposti omaksuttavassa ja
visuaalisesti todenmukaisessa muodossa. Käyttöliittymän on
oltava joustava ja otettava huomioon erilaisten käyttäjien
tarpeet. Esimerkiksi kokeneille käyttäjille tulisi tarjota
erilaisia oikoteitä tehtävien suoritukseen. Aloittelijoille taas
tulisi antaa tarvittavaa opastusta. Joustavuus ilmenee mm.
mahdollisuutena säätää käyttäjäkohtaisia asetuksia.
Käyttöliittymän tulisi käyttää hyväkseen erilaisia metaforia
todellisuudesta, tuttuja termejä ja mieluiten käyttäjän
äidinkieltä. Tehtävien suorituksen tulisi tapahtua
luonnollisessa järjestyksessä jonkin todellisen mallin mukaan.
2.3 Sijainnin ilmaiseminen
Olennainen osa käyttöliittymää on, että järjestelmä ilmaisee
selkeästi missä tilassa se on ja antaa palautetta jokaisen
toiminnon jälkeen [Erk95]. Käyttäjälle pitäisi olla joka
tilanteessa selvää sekä se mitä kohtaa artikkelista hän on
lukemassa että myös mitä artikkelia hän tutkii; mikä on hänen
sijaintinsa artikkelien muodostamassa hyperavaruudessa.
WWW-selainohjelmat ilmaisevat nämä tiedot liukupalkkien tai
sivunumeroiden ja osoitekenttien avulla. Samoin järjestelmän
tulee aina ilmoittaa käyttäjälle mihin artikkeliin mahdollisesti
aktivoitava linkki johtaa. Eksymisen välttämiseksi näiden
tietojen tulisi olla koko ajan esillä ja niissä tapahtuvat
muutokset tulisi esittää visuaalisesti selkeässä ja
ymmärrettävässä muodossa. Useat WWW-selaimet esimerkiksi
käyttävät värikoodia erottamaan jo kerran aktivoituja linkkejä
muista.
2.4 Eri linkkityypit
De Bra [Deb96] toteaa, että mikäli linkkejä ei oteta huomioon,
niin haku hypertekstistä on suoraan verrattavissa tavalliseen
tekstitietokantahakuun. Linkit siis tarjoavat hypertekstille sen
ilmaisuvoiman. Hakemistolinkit tarjoavat suoran pääsyn
hakusanoista artikkeleihin. Luonnollisesti käyttäjälle voidaan -
ja onkin eri käyttäjäryhmien huomioimisen kannalta tärkeää -
tarjota useita eri hakemistoja aiheen, aakkostettujen
hakusanojen tai erilaisten lukemisen järjestyssuositusten
mukaan. Viitelinkkiä seuraamalla päästään artikkelista toiseen,
esimerkiksi suoraan lähdeviitteenä olevaan artikkeliin. Tämä
nopeuttaa laajan kuvan muodostamista kokonaisuudesta, jota
tutkitaan. Määritelmälinkki antaa jollekin termille lyhyen
määritelmän - mieluiten omassa ikkunassaan tai kentässään.
WWW:ssä tällä hetkellä kaikki linkit ovat upotettuja
viitelinkkejä. Niiden avulla on toteutettu myös hakemistoja ja
määritelmiä, mutta esimerkiksi kokonaisen WWW-sivun lataaminen
jonkin termin määrittelemiseksi on turhaa työtä. Vakinaisen
määritelmäkentän varaaminen taas olisi resurssien tuhlaamista.
Määritelmät tulisikin toteuttaa jonkinlaisina
ponnahdusikkunoina. Andrews [And96] pitää upotettujen linkkien
hyvänä puolena helppoa toteutusta ja huonoina puolina
yksisuuntaisuutta, automaattisen linkkien ylläpidon puuttumista
ja vaikeutta linkittää muusta tiedosta kuin tekstistä.
Ratkaisuksi hän ehdottaa ulkoista linkkitietokantaa.
WWW:ssä käyttäjä voi valmiitten linkkien lisäksi itse määritellä
omia kirjanmerkkejään, suoria saantikohtia aikaisemmin
mielenkointoiseksi havaituista tietosolmuista. Järjestelmä pitää
yllä tietoa kuljetusta linkkipolusta sekä tutkituista
artikkeleista. Historialistojen avulla aikaisemmin esillä
olleeseen tietoon voidaan palata aina helposti.
2.5 Samankaltaisten artikkelien etsiminen
Yhden mielenkiintoisen tai etsittävän tiedon kannalta
merkittävän artikkelin löydettyään käyttäjä usein haluaa lukea
samasta aiheesta uusia samantyyppisiä artikkeleita.
Perinteisissä tekstitietokannoissa artikkelien samankaltaisuuden
selvittäminen perustuu erilaisiin merkkijonojen ja niiden
yhdistelmien vertailufunktioihin, kuten sanaston
päällekkäisyyden tai sanojen lähekkäisyyden tarkasteluun.
Hyperteksti tuo tähän lisänä linkkien avulla lasketut
painoarvot. Nielsenin [Nie95] mukaan voidaan tehdä perusoletus,
että toisiinsa linkitetyt artikkelit ovat jollain tavoin
samankaltaisia. Esimerkissä artikkeleille lasketaan arvoja sen
mukaan kuinka hyvin ne vastaavat kyselyyn. Artikkelille
lasketaan sisäinen painoarvo sen sisällön mukaan ja siihen
lisätään puolet niiden artikkelien sisäisistä painoarvoista,
joihin arvioitavasta artikkelista on linkkejä. Näin kuvassa 1
keskimmäisen solmun kokonaispainoksi tulisi 1+ (4+6+6)/2=9, eli
suurempi kuin minkään muun tietosolmun, vaikka solmun sisäinen
painoarvo onkin pienempi kuin muitten.
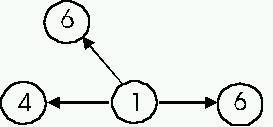
kuva 1, tietosolmujen sisäiset painoarvot
3 Selaus ja erilaiset käyttäjät
Käyttäjille, jotka eivät hallitse tiedonhausta edes alkeita, on
usein jo hakemiseen ryhtyminen suuri kynnys ylitettäväksi. Tämän
kynnyksen madaltamiseksi aloittaminen on tehtävä mahdollisimman
helpoksi. Selaaminen on usein luonnollisin tapa aloitteleville
käyttäjille tutustua järjestelmään ja sen sisältöön.
Selaamistapoja on useita ja niiden käyttöön vaikuttaa mm. se
kuinka hyvin käyttäjä tuntee haun kohteena olevan aiheen.
3.1 Selaus tiedonhakumenetelmänä
Tiedonhaun tehtävänä on löytää suurista tietokannoista ja
järjestelmistä tehtävän kannalta olennaista tietoa. Selaus on
hyvin epämuodollinen ja sisältökeskeinen tiedonhakustrategia.
Ilman ennakkosuunnittelua käyttäjä seuraa niitä linkkejä, joista
intuitio kertoo löytyvän tarvittavaa tietoa, tai jotka muuten
vain tuntuvat mielenkiintoisilta. Etsintä siis perustuu
pelkästään käyttäjän tekemille valinnoille, eikä kone suosittele
mitään artikkeleita. Hyvässä selaukseen rohkaisevassa
järjestelmässä tieto on kuitenkin järjestetty jonkin selvän
hierarkian mukaan löytämisen helpottamiseksi. Carmel et al.
[CCC92] esittävät selaukselle seuraavia syitä:
- käyttäjä ei pysty tai ei halua ilmaista haulle tarkkoja
parametrejä
- selaus on helpompaa kuin analyyttinen etsintä, mutta myös
toiminnallisempaa kuin ennakkosuunnittelua vaativa etsintä
- järjestelmä rohkaisee selaamaan tai ei kertakaikkiaan tue
analyyttistä hakua
- haku liittyy käyttäjän pitempiaikaisiin kiinnostuksen kohteisiin
ja hän toivoo löytävänsä selatessaan "kaupan päälle" jotain
myöhemmin tarpeellista tietoa.
Koska selaus on WWW:n pääasiallinen käyttömetodi, niin kaksi
ensimmäistä syytä auttavat ymmärtämään, miksi WWW palveluna on
kasvanut niin nopeasti ja saavuttanut niin monen uuden käyttäjän
suosion. Web itsessään ei oikeastaan tue muita hakutapoja kuin
selausta, joten kolmaskin syy soveltuu WWW:hen hyvin.
Selauksen motivaationa toimii usein yleinen mielenkiinto jotain
aihepiiriä kohtaan. Carmel et al. esittelevät vielä useiden
tutkijoiden malleja, joissa selaus jaotellaan:
-
Etsivään selaukseen, jossa etsitään jotain tiettyä tietoa. Tämä
haun kohde on siis tiedossa jo selauksen alkaessa
-
Yleiseen selaukseen, jossa tutkitaan lähteitä, jotka tunnetusti
sisältävät käyttäjän mielenkiinnon kohteita. Haun tarkempi kohde
päätetään vasta selauksen aikana
-
Satunnaiseen selaukseen, jossa käyttäjä ilman varsinaista
päämäärää tutustuu useisiin artikkeleihin.
Viimeisin selaustapa sopii hyvin ajatukseen, jonka mukaan
ihmiset selaavat myös viihdytystarkoituksessa. Tämä tuntuukin
olevan yksi WWW:n suosion perusteista.
3.2 Aloittelevat tiedonhakijat
Kokemattomat tiedonhakijat ovat usein kykenemättömiä
suorittamaan tarkkoja ja täsmällisiä kyselyitä; loogisten
operaatioiden käyttö saattaa olla ongelmallista. Esimerkiksi
Marchioninin ja Schneidermanin [Mas88] tutkimuksessa useat
koehenkilöt eivät ymmärtäneet, että AND- operaation käyttö
pienentää haun tuloksen artikkelimäärää. Tällaisille käyttäjille
selaus soveltuu yksinkertaisuutensa vuoksi erittäin hyvin.
Käyttäjän ei tarvitse tuntea mekaanisia tiedonhakutekniikoita
vaan hän voi rauhassa selata mielenkiintoisia linkkejä. Selaus
soveltuu tiedonhaun aloittamiseen myös koska se aiheuttaa
vähemmän kognitiivista rasitetta kuin tarkkojen ehtojen
määrittely kyselylle. Mikäli järjestelmä samalla tarjoaa hyvän
hierarkisen hakemiston tietoon ja jonkin yksinkertaisen
hakujärjestelmän voi käyttäjä vähitellen opetella tehokkaampia
hakukeinoja.
3.3 Tietosisältöä tuntemattomat käyttäjät
Toinen kokemattomien käyttäjien ryhmä on tutkittavaa aihetta
heikosti tai ei lainkaan tuntevat käyttäjät. Heillekin selaus
tarjoaa houkuttelevia ominaisuuksia. Tutkimuksissa [CCC92] on
todettu, että aiheeseen perehtymättömät käyttäjät usein
valitsevat useampia linkkejä kuin kokeneemmat ja harvemmin
lukevat artikkeleita loppuun asti. Vilkuiltuaan artikkelia he
siirtyvät nopeasti viitelinkkien kautta toisiin. Tällaiseen
yleiskuvan muodostamiseen selaus onkin ihanteellinen menetelmä.
Samassa tutkimuksessa havaittiin, että mikäli mahdollista,
aihetta tuntemattomat käyttäjät yrittävät lähestyä aihetta
jonkin itselleen tutun erikoisalan kautta. Tämän
huomioonottamiseksi hypertekstijärjestelmät tulisi organisoida
sellaisten hakemistojen tai valmiitten lukupolkujen avulla,
jotka tukevat asteittaista oppimista. Yleisluontoisemmista
artikkeleista johtaa linkkejä enemmän erikoistuneisiin
artikkeleihin.
3.4 Tietosisällön hyvin tuntevat käyttäjät
Käyttäjät, jotka ovat eksperttejä haettavan tiedon alueella
tietävät usein tarkkaan mitä tietoa he tarvitsevat, esimerkiksi
haluavat tarkistaa jonkin faktan. Carmelin et al. [CCC92] mukaan
he seuraavat harvempia linkkejä ja lukevat vähemmän
artikkeleita, mutta yleensä sitten lukevat nämä artikkelit
huolella läpi. He myös pystyvät paremmin ja useimmiten myös
haluavat arvioida artikkelin sisältöä ja sen lähestymistapaa
aiheeseen. Eksperteille selaaminen on usein tärkeä tapa pitää
tietonsa ajan tasalla.
4 Analyyttinen tiedonhaku ja kokeneet tiedonhakijat
Kokeneille tiedonhakijoille ei välttämättä riitä pelkkä
selaaminen vaan he kaipaavat tehokkaampaa ja täsmällisempää
hakujärjestelmää. Tällaiset analyyttiset hakujärjestelmät
perustuvat sille, että kone hakee tiedon käyttäjän antamien
kyselyehtojen perusteella.
4.1 Analyyttisen haun menetelmät
De Bra [Deb96] määrittelee tiedonhaun vaiheet seuraavasti:
-
Dokumenttien löytäminen: hajautetuissa järjestelmissä kuten
Internetissä kaikkien haun kannalta mielenkiintoisten
artikkelien löytäminen on hankalaa.
-
Kyselyjen muodostaminen: käyttäjän pitäisi osata ilmaista
täsmällisesti mitä tietoa hän etsii.
-
Käyttökelpoisuuden arviointi: järjestelmän on jotenkin
pääteltävä sisältääkö artikkeli tietoa, jota käyttäjä hakee.
Analyyttinen tiedonhaku perustuu tarkasti etukäteen
suunniteltuihin formaaleihin kyselyihin ja niiden
järjestelmälliseen iterointiin. Haun täsmentämisessä voidaan
käyttää apuna mm. loogisia operaatioita sekä synonyymi- ja
semanttisia sanastoja. Marchioninin ja Schneidermanin [Mas88]
mukaan tiedonhaun tehokkuuteen vaikuttavat tietokannan
tietosisällön soveltuvuus tehtävään, tiedon organisaatio
tietokannassa ja käyttöliittymän tarjoamat hakumenetelmät.
Ensimmäinen tekijä on luonnollinen, lähes triviaali vaatimus:
lienee turha hakea lintukirjasta tietoa Quentin Tarantinon
elokuvista. Jälkimmäiset tekijät liittyvät siihen millaisia
kyselyitä tietokantaan on yleensä mahdollista tehdä.
4.2 Kyselyt
Bärtschin [Bär85] mukaan kyselyjä voidaan muotoilla
luonnollisella kielellä, joukkona kyselynkuvaajia (query
descriptors) tai operaattorien (esim. loogisten) yhdistäminä
kuvaajina. Kyselyn arvioinnissa pyritään mahdollisimman hyvään
tarkkuuteen (precision) etsimällä todellisista tietosolmuista
sellaiset, jotka mahdollisimman hyvin vastaavat kyselytermejä
sekä samalla hyvään kattavuuteen (recall) eli etsitään
mahdollisimman suuri osa koko tietokannan näistä solmuista.
4.2.1 Perinteiset kyselyt
Perinteiset kyselyt perustuvat loogisten operaatioiden AND
(leikkaus), OR (yhdiste) ja NOT (negaatio) käyttöön
kyselytermien yhdistelyssä. Tämä yksinkertainen malli on
kuitenkin ilmaisuvoimaltaan sangen rajoittunut. Bärtschi [Bär85]
esittää tätä valottavan esimerkin. Jos kyselyyn syötetään 10
termiä AND-operaattorilla yhdistettynä, vain ja ainoastaan
kaikkia termejä vastaavat tietosolmut haetaan. Tuloksista jäävät
pois nekin solmut, jotka olisivat sopineet 9 termiin 10:stä ja
näin ollen sisältäneet oleellista tietoa. Jos taas termit
yhdistetään OR-operaattorilla, niin tulokseen otetaan mukaan
kaikki solmut, joissa yksikin termeistä esiintyy, eli
luultavasti saadaan aivan liian paljon turhaa tietoa. Termien
satunnaisesta yhdistämisestä AND- ja OR-operaattoreilla ei ole
hyötyä: tulokset ovat yhtä satunnaisia kuin kysely. Kaikkien eri
kombinaatioiden mukaisen kyselyn rakentaminen olisi liian
työlästä. Eikä tämä kysely kuten muutkaan pelkästään loogisiin
operaatioihin perustuvat kyselyt lajittelisi tuloksen
tietosolmuja mitenkään.
Tämän lajitteluongelman ratkaisemiseksi on kehitetty painotus.
Tietosolmuissa esiintyville termeille ja kyselyn termeille
lasketaan painoarvot sen mukaan kuinka oleellisia termit ovat
tietosolmun kuvaamisessa tai kyselyssä. Näiden painoarvojen
avulla lasketaan jokaiselle noudetulle tietosolmulle arvo, jonka
mukaan solmut järjestetään - kyselyyn parhaiten vastaavat
ensimmäisiksi.
4.2.2 Sumeat kyselyt ja kynnysmalli
Tavallista painotusta tehostamaan on kehitetty muutamia malleja,
joista tärkein Bärtschin [Bär85] mukaan on sumean haun (fuzzy
retrieval) malli, jolla on tausta sumeassa joukko-opissa.
AND-operaation tulos lasketaan osatulosten minimiarvona,
OR-operaation osatulosten maksimiarvona ja NOT-operaation tulos
saadaan vähentämällä termin tulos tulos (väliltä [0,1])
ykkösestä. Jos esimerkiksi termi X tuottaa tuloksen 0.9 ja termi
Y tuloksen 0.6, niin X AND Y = min(0.9 , 0.6) = 0.6 ja X OR
Y = max(0.9 , 0.6) = 0.9. NOT Y antaisi tulokseksi 1 - 0.6 = 0.4.
Edellisissä malleissa kyselyn kannalta paras tietosolmu on
suurimman tuloksen tuottava. Kynnysmallissa (treshold model)
paras solmu on tulokseltaan mahdollisimman lähelle annettua
kynnysarvoa osuva. Sekä kynnysarvoa suuremmat ja pienemmät
tulokset katsotaan huonommiksi. Koko kyselyn kynnysarvo
määritellään kyselytermeille annetuista kynnysarvoista.
4.2.3 Vektoriavaruus- ja todennäköisyysmallit
Vektoriavaruusmallissa (vector space model) ei käytetä lainkaan
loogisia operaatioita vaan tietosolmun kuvaajatermien ajatellaan
muodostavan vektoriavaruuden, jossa kyselyt ja tietosolmut ovat
vektoreita. Kyselyn tulos lasketaan näiden vektorien sisätulona.
Todennäköisyysmallissa (probabilistic retrieval) pyritään
optimoimaan haettujen tietosolmujen oleellisuutta kyselylle.
Laskennan takana oleva matemaattinen malli on kuitenkin niin
monimutkainen, että kyselytermien määrää jouduttaisiin
rajoittamaan muutamaan, jotta malliin perustuvat hakuohjelmat
olisivat käyttökelpoisia.
4.3 Kokeneet tiedonhakijat
Kokeneet käyttäjät ovat usein tiedonhaun ammattilaisia ja
haluavat hakea tietokannasta mahdollisimman nopeasti ja
tehokkaasti tietoa, joka vastaa tarkasti annettuihin
kysymyksiin. He eivät niinkään välitä itse tiedon muusta
sisällöstä. He tuntevat etukäteen hakujärjestelmän ominaisuudet
ja tietävät kuinka sitä voi hyväksikäyttää parhaiten
kulloiseenkin hakuun. Kokeneet käyttäjät hallitsevat loogisten
operaatioiden tehokkaan käytön ja tuntevat etukäteissuunnittelun
merkityksen - he harvemmin ajautuvat turhaan selailuun.
Kokeneille käyttäjille on yleensä erittäin tärkeää
hakujärjestelmän ilmaisuvoima: kyselyt tulee voida esittää
täsmällisesti. Myös joustavuus on suuri vaikutin, tehokäyttäjät
haluavat järjestelmän mukautuvan omiin tarpeisiinsa.
Käyttöliittymältä he vaativat nopeutta ja tehokkuutta lisääviä
oikopolkuja sekä muita helpotteita.
5 Menetelmien vertailu
Hakustrategian valitsemiseen vaikuttaa Marchioninin ja
Schneidermanin [Mas88] mukaan tärkeänä tekijänä tilanne, joka
koostuu sekä fyysisistä että henkisistä olosuhteista. Tiedonhaku
julkisessa paikassa, kuten kirjastossa aiheuttaa aivan erilaiset
rajoitteet haulle kuin oman työhuoneen rauha. Samoin motivaatio
voi vaihdella sen mukaan liittyykö haku työtehtävään tai
esimerkiksi harrastuksiin. Selaus soveltuu analyyttisiä
menetelmiä paremmin satunnaiseen tiedonhakuun, jossa ei edes ole
pyrkimyksenä löytää tarkkaa tietoa jostain etukäteen määrätystä
asiasta. Mikäli haun tarkoituksena on vastata johonkin tiettyyn
ongelmaan on täsmälliseen kyselyyn perustuva haku tehokkaampi
menetelmä. Koska aloittelevien tiedonhakijoiden on hankalampi
käyttää hakujärjestelmiä kuin kokeneitten, niin järjestelmän
tulisi olla mukautettavissa tai mukautua automaattisesti
käyttäjän tarpeisiin. Aloittelijalle tulisi tarjota helppo tapa
oppia järjestelmän käyttö ja kokeneelle käyttäjälle tarpeeksi
tehokkaat hakuominaisuudet. Marchioninin ja Schneidermanin
[Mas88] tutkimuksissa tiedonhaun ammattilaiset ylivoimaisesti
useammin pitäytyivät perinteisessä hakemistoihin perustuvassa
haussa, vaikka järjestelmä olisi tarjonnut helppokäyttöisemmät
upotetut valikotkin. Pitempiaikaisessa tutkimuksessa museoissa
taas todettiin suurimman osan hausta tapahtuvat upotettujen
valikkojen kautta. Järjestelmän tulisi tukea asteittaista
oppimista, jolloin tietosisältöä tuntemattomat käyttäjät
voisivat helposti muodostaa kokonaiskuvan aiheesta, mutta
samalla eksperteille tulisi taata pääsy pitemmälle
erikoistuneisiin artikkeleihin.
6 Malli tiedonhaulle WWW:stä
World Wide Webin suuren sivumäärän vuoksi oleellisen tiedon
löytäminen saattaa olla vaikea ja monimutkainen tehtävä.
Käyttäjällä on WWW:stä tietoa hakiessaan neljä etenemistapaa:
Käyttäjä tietää tarkan osoitteen etsimälleen tiedolle. Tämä on
kaikkein helpoin tapa, eikä vaadi varsinaista tiedonhakua.
Käyttäjä tietää jonkin hyvän aloitussivun osoitteen. Hyvä
aloitussivu voi olla jonkun aiheesta kiinnostuneen henkilön
kotisivu tai jokin aiheesta koottu linkkisivu. Tältä sivulta
käyttäjä etenee selaamalla.
Käyttäjä käyttää hyväkseen jotain hierarkista hakujärjestelmää
(esimerkiksi Yahoo). Tällä tavoin voidaan saada esille haluttu
tieto tai edellisen kohdan hyvä aloitussivu.
Käyttäjä antaa haun suoritettavaksi jollekin hakurobotille
(esimerkiksi Alta Vista, Infoseek, Lycos). Käyttäjä muotoilee
ohjelmalle kyselyn ja käyttää tuloksia aloitussivuina mikäli ne
eivät tuota haluttua tietoa suoraan.
6.1 Hierarkiset hakujärjestelmät - Yahoo
Hierarkinen hakujärjestelmä on joukko linkkejä, jotka
järjestelmän ylläpitäjä on koonnut puumaiseksi rakenteeksi
aiheen mukaan. Hierarkisten järjestelmien linkkitietokannat ovat
huomattavasti pienempiä kuin hakurobotteja käyttävien
järjestelmien, mutta niitten etuna on jonkinlainen
laadunvalvonta. Koska linkit kerää ihminen eikä ohjelma, niin
voidaan tarkistaa, ettei kyseessä ole saman sivun vanha versio
sekä varmistaa, että sivu todellakin käsittelee aihetta, jonka
mukaan sitä ollaan luokittamassa.
Kuva 2, Yahoon pääsivu
WWW:n hierarkisista hakujärjestelmistä suosituin lienee Yahoo
(kuva 2 - http://www.yahoo.com/), joka on ollut aivan
ensimmäisten joukossa sekä palvelun rakentajana, että sen
kaupallistamisessa. Yahoo jakaa sivut 14 pääryhmään (taiteet,
kauppa ja talous, tietokoneet ja Internet, koulutus, viihde,
hallinto, terveys, uutiset, harrasteet, viitteet, alueet,
tieteet, yhteiskuntatieteet sekä yhteiskunta ja kulttuuri) ja
näiden alla on useita alaluokkia ja niiden alaluokkia. Aiheiden
päällekäisyydestä Yahoo selviää puurakenteessa olevien
sivuttaislinkkien (merkitty @-merkillä) avulla. Esimerkiksi
tiedonhausta tietoa etsivä aloittaa tieteistä ja
tietojenkäsittelystä (Science:Computer science). Täältä on
sivuttaislinkki informaatiotieteisiin, joiden kautta tiedonhaku
löytyy aivan eri kategorian alta kuin mistä etsiminen alkoi.
Lista (Reference:Libraries:Information science:Information
retrieval) sisältää 7 sivun osoitteet. Yahoon valttina on
tiedon tarkka erittely ja listattujen sivujen laatu. Esimerkiksi
Quentin Tarantinon Reservoir Dogs -elokuvaa käsitteleviä sivuja
on listattu 11 kappaletta kategoriassa
Entertainment:Movies:Genres:Action/Adventure:Titles:Reservoir
Dogs. Hakurobotti antaisi elokuvan nimeen perustuvalla haulla
useita tuhansia sivuja, joilla ei olisi välttämättä mitään
tekemistä elokuvan kanssa. Yahoossa on itsessään mukana myös
pieni hakurobotti, joka esittää Yahoon hierarkiaan luokitellut
sivut erikseen.
6.2 Hakurobotit - Alta Vista
Hakurobotit ovat ohjelmia, jotka seuraavat mekaanisesti
WWW-sivuilla olevia linkkejä ja kirjaavat ne tietokantaan.
Varsinainen hakuohjelma sitten etsii tästä tietokannasta
käyttäjän kyselyyn soveltuvat sivut. Kyselyt ovat yleensä
tekstikyselyitä, joiden avulla löydetään ne sivut, joissa
kyselyn sanat ovat esiintyneet. Toiset robotit indeksoivat koko
sivun, jotkut vain esimerkiksi sivun sata ensimmäistä sanaa.
Hakurobottien tietokannat ovat valtavia, jotkut mainostavat
käsittävänsä jopa 90% kaikista Webin sivuista. Tässä piileekin
niiden suurin vahvuus ja samalla myös suurin heikkous.
Hakurobottia käyttämällä saa varmastikin kattavan osuuden Webin
sisällöstä aiheesta kuin aiheesta, mutta samalla saa suuren
määrän vanhentunutta ja asiaan varsinaisesti liittymätöntä
aineistoa.
kuva 3, Alta Vistan tehokysely
Hakuroboteista tällä hetkellä kattavin, tehokkain ja käytetyin
on Digitalin kehittämä Alta Vista (kuva 3 -
http://altavista.digital.com/), joka mainostaa (15.4.96)
sisältävänsä 11 miljardia sanaa 22 miljoonalta Web-sivulta.
Webin valtaisaa kasvua kuvastaa hyvin se, että vajaa neljä
kuukautta aiemmin (24.12.95) Alta Vista sisälsi 8 miljardia
sanaa 16 miljoonalla sivulla; 37,5% kasvu noin sadassa päivässä.
Alta Vista indeksoi sisältämistään sivuista kaikki sanat.
Lisäksi se ottaa huomioon erikseen, jos sanat kuuluvat johonkin
html-tagiin (esimerkiksi image, title). Alta Vista arvostaa
kyselyn tuottamaa sivua sitä enemmän mitä aikaisemmin ja mitä
useammin sana sivulla esiintyy. Alta Vistan tehokysely (advanced
query) käyttää hyväkseen loogisia operaatioita. Niiden lisäksi
sanojen läheisyyttä voi käyttää hyväksi: NEAR-operaattorin
yhdistämien sanojen täytyy sijaita tekstissä korkeintaan 10
sanan etäisyydellä. Niinpä Richard NEAR Nixon löytäisi
esiintymät: Richard Nixon ja Nixon, Richard sekä jopa Richard M.
Nixon. Loogisista operaatioista voi rakentaa tarkkoja ja
monimutkaisia kyselyitä sulkujen avulla. Sanayhdistelmät voi
rajata lainausmerkeillä, jolloin haku etsii näitä täsmällisiä
sanoja juuri annetussa järjestyksessä. Results ranking criteria
-kenttään voi määritellä, mitä sanoja painotetaan lopullisessa
lajittelussa eniten.
Alta Vista pyöristää kyselyn tuottamien sivujen määrän, mutta
seuraavat esimerkit antavat viitettä millaisista määristä on
kyse. Samalla käy ilmi miten loogiset operaatiot vaikuttavat
kyselyyn.
| Kysely | Sivujen määrä
|
| information AND retrieval | 100000
|
| information OR retrieval | 7000000
|
| information NEAR retrieval | 60000
|
| information AND NOT retrieval | 7000000
|
| retrieval AND NOT information | 30000
|
| "information retrieval" | 40000
|
| Kysely | Sivujen määrä
|
| reservoir AND dogs | 5000
|
| reservoir OR dogs | 100000
|
| reservoir NEAR dogs | 4000
|
| reservoir AND NOT dogs | 40000
|
| dogs AND NOT reservoir | 100000
|
| "reservoir dogs" | 4000
|
6.3 Vertailu
Hierarkisen hakujärjestelmän etu on sen antaman tiedon laatu,
hakurobotin taas sen antaman tiedon laajuus. Etsittäessä tärkeää
tietoa lienee syytä turvautua molempiin: ensin tarkistetaan
löytyykö aiheesta hyviä sivuja hierarkisesta hakemistosta ja
tutkitaan ne. Mikäli tarpeellinen tieto ei löytynyt, niin
käytetään hakurobottia sen etsimiseen. Hakurobotti löytää myös
kaikki viitteet aiheeseen sivuilta, joiden pääaihe ei ole
etsinnän kohteena oleva aihe. Jos sivu käsittelee useampia eri
aiheita, se todennäköisesti löytyy paremmin hakurobotilla.
Hakemistojen rasitteena on myös kategorioiden rajallisuus:
mikäli etsittävä tieto ei ole kovin tarkkaan rajattua, niin
kannattanee turvautua hakurobottiin.
7 Yhteenveto
World Wide Webin kaltaiset hypertekstijärjestelmät tehostavat
tiedonhakua monilla eri tavoilla. Toisaalta ne tuovat tiedonhaun
aloittelijoidenkin ulottuville. Järjestelmä ikäänkuin korvaa
käyttäjän puutteet. Selaaminen, WWW:n pääasiallinen
käyttömetodi, soveltuu tutkimusten mukaan parhaiten
epämuodolliseen etsimiseen. Tämän epämuodollisuuden syynä voi
olla joko käyttäjän kykenemättömyys ongelman täsmälliseen
määrittämiseen tai tarkkaan määritetyn ongelman puuttuminen.
Jälkimmäistä syytä edustaa esimerkiksi uuden tiedon etsiminen
joltain tietyltä alalta. Selausta on kolmentyyppistä: etsivä
selaus, jossa haetaan jotain tiettyä tietoa, yleinen selaus,
jossa selataan kiinnostuksen kohteita ja päätetään vasta
selatessa mitä tietoa haetaan sekä satunnainen selaus, jossa
silmäillään tietoa päämäärättä. Analyyttinen haku perustuu
formaaleihin, etukäteen suunniteltuihin kyselyihin. Yleisin
kyselytapa on vielä loogisten operaatioiden käyttöön perustuva,
jota arvioidaan sumeaan joukko-oppiin perustuvilla menetelmillä,
mutta vektoriavaruus- ja todennäköisyysmallit ovat
varteenotetavia vaihtoehtoja mikäli niiden käyttö onnistutaan
optimoimaan.
Yleisesti ottaen järjestelmien tulisi tarjota kokeneelle
käyttäjille tarpeeksi tehokkaat analyyttiset hakumenetelmät ja
aloittelijoille helppo oppimisympäristö. Käyttäjän tulisi voida
itse vähitellen siirtyä järjestelmän tehokkaampaan käyttöön.
Tietosisältöä tuntemattomat käyttäjät pyrkivät viitelinkkejä
seuraamalla saamaan nopeasti selkeän yleiskäsityksen aiheesta.
Tiedon hyvin hallitsevat käyttäjät taas tutustuvat mieluummin
perinpohjaisesti artikkeleihin ja arvioivat niitä tarkemmin.
Hyvä järjestelmä rakennetaan siirtymään yleisistä aiheista
vähitellen erikoisaiheisiin.
World Wide Webistä tapahtuvalle tiedonhaulle on neljä tapaa:
tarkan osoitteen tietäminen, hyvän aloitussivun tietäminen,
hierarkisen hakemiston käyttäminen ja hakurobotin käyttäminen.
Mikäli ensimmäisistä tavoista ei ole apua kannattaa ensin
tarkistaa löytyykö aihetta käsitteleviä sivuja Yahoosta ja sen
jälkeen täydentää etsintää Alta Vistan avulla. Tulevaisuudessa
suurimmat haasteet WWW-tiedonhaussa ovat tiedonhaun eri
vaiheitten visualisointi, kuviin ja ääneen perustuva tiedonhaku
sekä tekoälyn integroiminen hakujärjestelmiin.
8 Lähteet
- And96
- Andrews, K., Applying Hypermedia Research to the World
Wide Web,
http://hyperg.iicm.tu-graz.ac.at/apphrweb, 1996.
-
Bär85
- Bärtschi, M., An Overview of Information Retrieval
Subjects, Computer 18,5(1985), s.67-84.
-
CCC92
- Carmel, E., Crawford, S., Chen, H., Browsing in
Hypertext: A Cognitive Study, IEEE Transactions On Systems,
Man And Cybernetics vol. 22,5(1992), s. 865-884.
- Deb96
- De Bra, P., Information Retrieval In
Hypertext,
http://wwwis.win.tue.nl/~debra/cursus/static/retrieval.html,
1996 (osa laajempaa hypertekstikurssia).
-
Erk95
- Erkiö, H., Käyttöliittymät - luentomateriaalia, kevät
1995 osa1, Helsingin
yliopisto, 1995, s. 37-38 (lainattu Info94-monisteesta).
- MaS88
- Marchionini, G., Schneiderman, B., Finding Facts vs.
Browsing Knowledge in
Hypertext Systems, Computer 21,1(1988), s. 70-80.
-
Nie95
- Nielsen, J., Multimedia and Hypertext - Internet and
Beyond, Academic Press, Inc., 1995, s. 224-234.