Tietorakenne tarkoittaa ohjelman käsittelemän tiedon säilytystapaa.
Tähän mennessä olemme käyttäneet kaikkialla tietorakennetta
ArrayList. Periaatteessa kaikki ohjelmat voi tehdä pelkän
ArrayList-rakenteen avulla. Kuitenkin jos ohjelman käsittelemän
tiedon määrä on suuri, ArrayList voi osoittautua liian hitaaksi
tietorakenteeksi.
Jokaisella tietorakenteella on omat vahvuutensa ja heikkoutensa. Tärkeä ohjelmoijan taito onkin valita oikea tietorakenne käyttötilanteen mukaan. Ohjelmoinnin peruskursseilla tietorakenteet ovat sivuosassa, mutta niistä on silti hyvä tietää jotain. Aiheeseen tutustutaan syvällisemmin erillisellä Tietorakenteet-kurssilla.
Tietorakenteen soveltuvuutta tiettyyn tarkoitukseen voi tutkia laatimalla suuren testiaineiston ja mittaamalla, kuinka paljon sen käsittelyyn menee aikaa.
Tarkastellaan tässä esimerkkiä, jossa ohjelman käytössä ovat seuraavat aineistot:
Tehtävänä on etsiä kaikki sanat, jotka esiintyvät molemmissa sanalistoissa.
Seuraava ohjelma etsii yhteiset sanat ArrayList-rakenteen
avulla. Se tallentaa ensin kaikki suomen kielen sanat
ArrayList-rakenteeseen ja tulostaa sitten kaikki siinä esiintyvät
englannin kielen sanat.
Ohjelman koodi on seuraava:
// aloitusaika millisekunteina
long alkuaika = System.currentTimeMillis();
// suomen kielen sanojen lukeminen
ArrayList<String> suomenSanat = new ArrayList<String>();
Scanner tiedosto1 = new Scanner(new File("suomi.txt"));
while (tiedosto1.hasNextLine()) {
String suomenSana = tiedosto1.nextLine();
suomenSanat.add(suomenSana);
}
// englannin kielen sanojen tarkistaminen
Scanner tiedosto2 = new Scanner(new File("englanti.txt"));
while (tiedosto2.hasNextLine()) {
String englanninSana = tiedosto2.nextLine();
if (suomenSanat.contains(englanninSana)) {
System.out.println(englanninSana);
}
}
//lopetusaika millisekunteina
long loppuaika = System.currentTimeMillis();
// suorituksen kesto
double kesto = (double)(loppuaika - alkuaika) / 1000;
System.out.println("Aika: " + kesto + " s");
Huomaa ajanmittaukseen liittyvät komennot koodin alussa ja lopussa. Metodi
System.currentTimeMillis palauttaa tietokoneen sisäisen ajan
millisekunteina, joten ohjelman suoritusajan voi laskea vähentämällä
lopetusajan aloitusajasta.
Ohjelman tulostus voi olla seuraava:
abo adagio adonis (paljon sanoja välissä) zombie zucchini zulu Aika: 139.669 s
Ohjelma löytää onnistuneesti kaikki yhteiset sanat, ja aikaa kuluu 140 sekuntia eli 2 minuuttia ja 20 sekuntia.
Tämä ei ehkä tunnu huomattavan hitaalta ohjelmalta: onhan sanojen määrä sentään suuri. Mutta valitsemalla tietorakenteen paremmin ohjelman saa toimimaan silmänräpäyksessä!
Yllä olevan ohjelman pullonkaula on seuraava koodirivi:
if (suomenSanat.contains(englanninSana)) {
Tässä metodi contains toimii käytännössä niin, että se käy
ArrayList-rakenteen läpi alusta loppuun ja tarkistaa, onko
jossakin kohdassa haettu arvo. Nyt jos sana on listan loppuosassa tai sitä ei
esiinny listalla, ohjelma joutuu käymään koko listan läpi. Kun ohjelma
joutuu tarkastamaan suuren määrän sanoja, tässä kestää kauan.
Tehdään yllä olevaan ohjelmaan pieni muutos. Korvataan rivi
ArrayList<String> suomenSanat = new ArrayList<String>();
rivillä
TreeSet<String> suomenSanat = new TreeSet<String>();
Tässä otettiin käyttöön tietorakenne TreeSet. Se tuntee samat
metodit add ja contains kuin ArrayList,
eli muu koodi voi säilyä ennallaan. Mutta onko muutoksesta hyötyä?
Muutoksesta on hyötyä:
abo adagio adonis (paljon sanoja välissä) zombie zucchini zulu Aika: 0.731 s
Nyt ohjelman suoritus vie aikaa alle sekunnin, joten se nopeutui lähes 200-kertaisesti.
TreeSet on nimensä mukaisesti puumainen tietorakenne, jonka
vahvuutena on, että molemmat metodit add ja contains
toimivat nopeasti.
Käytännössä TreeSet pitää sanoja muistissa seuraavaan
tapaan:
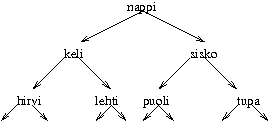
Jokaisessa puun haarassa on yksi sanalistan sana. Kaikki sanat, jotka ovat ennen tätä sanaa aakkosissa, ovat vasemmassa haarassa, kun taas kaikki sanat, jotka ovat tämän sanan jälkeen aakkosissa, ovat oikeassa haarassa. Tämän ansiosta puusta voi tarkistaa hyvin nopeasti, onko siinä tiettyä sanaa.
TreeMap on hyödyllinen tietorakenne, johon tallennetaan
tietopareja. Pari muodostuu kahdesta jäsenestä: ensimmäinen jäsen on avain ja
toinen jäsen on arvo. Myös TreeMap on toteutettu puurakenteen
avulla, minkä ansiosta siitä pystyy etsimään nopeasti parin arvoa sen avaimen
perusteella.
Seuraavassa esimerkissä TreeMap-rakenteen avulla tehdään
sanakirja:
TreeMap<String, String> sanakirja = new TreeMap<String, String>();
sanakirja.put("apina", "monkey");
sanakirja.put("banaani", "banana");
sanakirja.put("cembalo", "harpsichord");
System.out.println("Anna sana: ");
String sana = input.nextLine();
if (sanakirja.containsKey(sana)) {
System.out.println("Käännös: " + sanakirja.get(sana));
} else {
System.out.println("Tuntematon sana!");
}
Ohjelman toiminta on seuraava:
Anna sana: banaani Käännös: banana
Anna sana: selleri Tuntematon sana!
Tässä käytettiin seuraavia TreeMap-rakenteen metodeita:
put lisää tietoparin rakenteeseen.
containsKey tarkistaa, onko parin avainta rakenteessa.
get hakee parin arvon avaimen perusteella.
TreeMap-rakenteen avulla voi myös pitää kirjaa lukumääristä.
Seuraava ohjelma laskee, montako kertaa käyttäjä antaa eri merkkijonoja.
TreeMap<String, Integer> lukumaarat = new TreeMap<String, Integer>();
System.out.println("Anna sanoja (tyhjä lopettaa):");
while (true) {
String sana = input.nextLine();
if (sana.equals("")) {
break;
}
if (lukumaarat.containsKey(sana)) {
int vanhaMaara = lukumaarat.get(sana);
int uusiMaara = vanhaMaara + 1;
lukumaarat.put(sana, uusiMaara);
} else {
lukumaarat.put(sana, 1);
}
}
for (String sana : lukumaarat.keySet()) {
System.out.println(sana + ": " + lukumaarat.get(sana) + " kpl");
}
Ohjelman suoritus voi olla seuraava:
Anna sanoja (tyhjä lopettaa): apina apina banaani apina cembalo banaani apina apina: 4 kpl banaani: 2 kpl cembalo: 1 kpl