Chapter 13
Overview of the causes and mechanisms
In this final part of the book, we move to the question of how to reduce suffering, or, ultimately, how to be
liberated from it. Applying the scientific theories of the previous chapters, we devise various methods to that end
in the following two chapters. But first, in this chapter, I will recapitulate the basic theory. I will use two
flowcharts to illustrate the basic mechanisms of suffering: the first one emphasizes adverse properties of the
world and general cognitive design principles, while the second flowchart focuses on the dynamics of
moment-to-moment cognition. The flowcharts also make some explicit connections to the basic concepts of
Buddhist philosophy. The connection of reward loss to the whole architecture of intelligence is
then succinctly summarized in one single “equation”, which directly suggests ways of reducing
suffering.
Why there is (so much) suffering
Let us start by looking at the difficulty of information-processing in a complex world. The fundamental
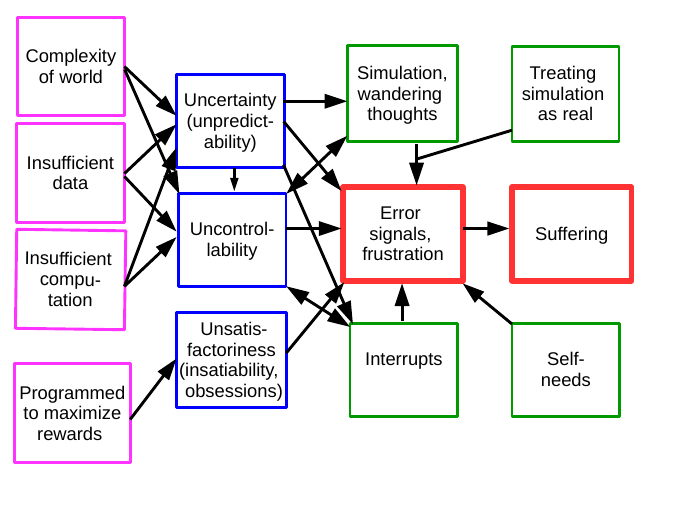
reasons of how suffering or mental pain is born are illustrated in Fig 13.1, which I will next go through in
detail.
Root causes of suffering
The starting point is that the agent finds itself in a world which is highly complex. In such a world, acting
optimally (in any reasonable sense of optimality) would require huge amounts of sufficiently detailed sensory
input, together with huge capacities of computation. Unfortunately, in the real world where we live in, an agent
cannot have any of those. These three root causes of suffering—complexity of the world, insufficient data, and
insufficient computation—are shown in the left-most column of the figure. Certainly, the agent’s limited physical
capabilities to act in the world and change it—catch any prey it wants, for example—create suffering as well, but
here we focus on limitations related to information-processing because it can be modified more
easily.
At the same time, the system is typically programmed to try to relentlessly maximize rewards which are
ultimately set by the “programmer”—which is evolution for humans, possibly complemented by some cultural
processes. The rewards are not designed to make the agent happy, but to fulfill some objectives of the
programmer, such as spreading your genes in the case of evolution. It is not possible for the agent itself to decide
that it wants to pursue some new objectives and re-define its own rewards; nor can it decide that it has had
enough rewards and does not need more. This is a fourth root cause of suffering, shown at the bottom of the
left-most column of the figure.
Three fundamental problems in information-processing
The four root causes just mentioned lead to a number of challenges for information-processing, which I here
condense into three: uncertainty (including unpredictability), uncontrollability, and unsatisfactoriness (consisting
of insatiability together with evolutionary obsessions).
First, the overwhelming complexity of the world leads to uncertainty: the agent is not able to accurately
understand what happens in the world. It is not even able to accurately perceive most phenomena
in the world. It will try to divide the perceptual inputs into categories, but such categories are
fuzzy, sometimes arbitrary, and categorization is often uncertain. Thus, there are various kinds of
uncertainty.
One important special case is uncertainty about the future, also called unpredictability. (It is closely
related to the Buddhist concept of impermanence, as will be discussed in Chapter 14.) On the one
hand, it is clear that it is difficult to predict the future if even the current state of the world is
uncertain, which is a consequence of uncertain perception. However, unpredictability is actually a
more general phenomenon than the uncertainty of perception: even if the perceptions were very
accurate and certain, it might not be possible to predict the future accurately due to the great
complexity of the world. It might be impossible to learn to model the world accurately enough, or using
such models might require overwhelming computational power. This is well-known in the natural
sciences, where even extremely accurate measurements of a natural phenomenon do not necessarily
mean you can predict it, because the prediction would require overwhelmingly advanced scientific
models.
Uncertainty and unpredictability necessarily lead to uncontrollability, lack of control of
the world: if the agent does not know what is actually happening in the world, or it does not
know how to predict what will happen in the future, it cannot possibly control the world.
In fact, control requires the capability to predict the results of your actions, which requires not
only a good model for prediction, but also an accurate perception of the current state of the
world.
Uncontrollability is increased by other factors in addition to uncertainty. Even if the world could be perfectly
perceived and predicted, there would still be uncontrollability due to at least two reasons. First, the agent has
limited physical capacities to influence the world. Second, limitations of computation reduce controllability in
many ways: the computational complexity of the search tree precludes finding perfect solutions to the planning
problem, while the parallel and distributed nature of the agent’s cognitive system precludes proper control of the
agent’s internal functioning. All these reasons make sure that the world is uncontrollable for humans. But it can
be rather uncontrollable even for a thermostat, since the temperature of most environments obeys extremely
complex natural laws that are beyond the understanding of the thermostat, and errors cannot be
avoided.
Meanwhile, the programming of the agent to maximize rewards means that the agent finds that no amount
of rewards is enough: it is insatiable (see ). In fact, the very raison d’être of the agent is to maximize the
rewards set by its programmer or evolution. But it will never be satisfied, and the desires will never be satiated.
A related property is what I called evolutionary obsessions (see ), which means that humans are
compelled to seek various rewards which they might, if they thought about it rationally, prefer not to
seek—such as unhealthy food and excessive competition for status. Seeking those unnecessary rewards
increases the chances for frustration, thus leading to more suffering, and may even lead to less
reward in the long run (by ruining your health, for example). Yet, it is difficult for humans to change
what they find rewarding. I group these two properties under the umbrella term unsatisfactoriness,
expressing the general idea that even if the world were completely known and controllable, there
would still be suffering due to the fact that the system is never satiated and strives at questionable
goals.
The three fundamental problems of uncertainty, uncontrollability, and unsatisfactoriness are shown as blue boxes in Figure 13.1,
the second column.
Error signals and suffering
Because of uncontrollability and uncertainty, the agent will have error signals. Often, things do not go as
planned or as expected, thus predictions have errors and expected reward will not be obtained, which generates
error signals. Such error signals are particularly frequent because the agent is never satisfied and is
always looking for more reward. Error signalling is the central red box in the third column in the
figure.
Our fundamental hypothesis in this book is that such error signals are what produce the feeling, and
ultimately the conscious experience, of suffering. The suffering due to error signals is especially strong if the
error is frustration, i.e. the agent is trying to reach the goal (or a reward) but it fails. Thus, error signals finally
lead into the red box of suffering, on the right-hand side in the figure.
Optional processes that increase suffering
Several further processes may further be activated, depending on how sophisticated the agent is. If its cognitive
architecture uses wandering thoughts, we get another box in the flowchart (top row, third column). It is a type of
information processing that takes place only in highly sophisticated agents, which is indicated by drawing the
box in green. In general, highly intelligent agents may engage in simulation of the world in terms of
planning and replay, which in humans often happens in the form of wandering thoughts. These
increase error signalling by repeating or anticipating experienced errors; this is depicted as the green
simulation box on the top row feeding into error signals. Since the goal of simulation and wandering
thoughts is to gain more control and reduce uncertainty on the world by better learning its dynamics,
there is an arrow from the uncontrollability and uncertainty boxes to the simulation box. On the
other hand, since wandering thoughts increase uncontrollability in their own way, that arrow is
bidirectional.
Furthermore, the agent may react in different ways towards the contents being replayed or simulated. If the
simulated contents are processed almost as if they were real, and the various frustrations in the simulations
are processed in the same way as real frustrations, this will greatly increase suffering. Otherwise,
simulated error signals might not lead to suffering. This is indicated in the flowchart as the green
box on the top right-hand corner which feeds into the connection between the simulation box and
the error signal box, modulating the connection between simulation and error signalling as just
described.
A related design principle is interrupts, which are useful for handling uncertainty due to unpredictability
as well as uncontrollability and are seen as one aspect of emotions as well as desire in this book.
Interrupts create more frustration since by interrupting behaviour they increase uncontrollability; they
also impose new goals on the agent, which obviously can lead to frustration. Interrupts may also
produce specific error signals not related to frustration as they use the pain signalling pathway to
grab attention. Interrupts are depicted as another green box on the bottom row, feeding into error
signals.
Sufficiently developed agents have various intrinsic rewards, which may be frustrated as well. The very
strongest suffering actually tends to come from the frustration of self-related goals, such as survival or the
self-evaluation. Such self-needs create new kinds of frustration and errors, such as the agent “not being good
enough” in the sense of not obtaining enough rewards on a longer time scale. This is the box at the bottom
right-hand corner, again in green since it is a sophisticated module, which the programmer may include in the
system or not.
This flowchart explains the conditions leading to suffering on a rather abstract
level. If
we consider it from the viewpoint of interventions, e.g. practices that would decrease suffering, it clearly points
out that we could reduce suffering by reducing wandering thoughts, self-needs, and other processing in the
green boxes. Such ideas will be considered in detail in the next chapters. The next chapters will
also consider how to deal with the blue boxes (uncertainty, uncontrollability, unsatisfactoriness).
In the remainder of this chapter, however, we look at the process of suffering from two different
angles.
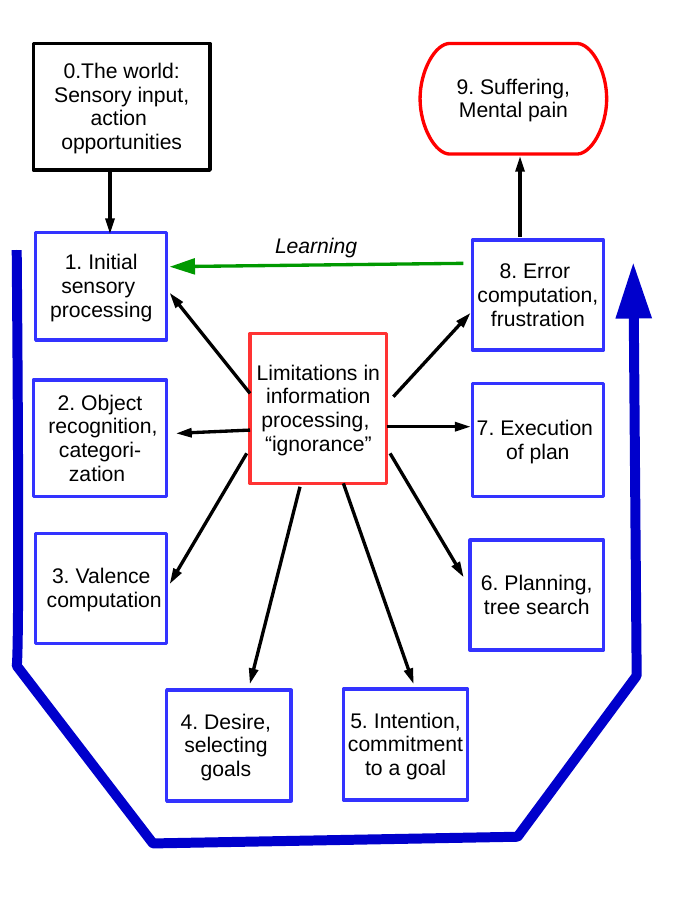
Cognitive dynamics leading to suffering
A complementary viewpoint is provided by cognitive dynamics, i.e. how the different cognitive processes work
and influence each other in real-time. In some sense, this is about zooming into the part of the mechanism in
Figure 13.1 that leads from the blue boxes in the second column (uncertainty, uncontrollability,
unsatisfactoriness) to errors and suffering. This reveals further quantities that can be intervened on to reduce
suffering.
In previous chapters, we have seen a number of steps in an information-processing procedure that translates
sensory input into action decisions and possibly suffering. Such steps are recapitulated and illustrated in our
second flowchart in Figure 13.2. To begin with, sensory input is received from the external world; see the upper
left-hand corner of the flowchart. As the black arrow in the flowchart indicates, at the next step, the agent
engages in initial sensory processing. This typically leads to recognition and categorization of objects in the
world as the next step, which in our basic formalism includes recognition of the state in which the agent is. (For
better visualization, the order of processing is now indicated by a single long blue arrow in the
flowchart.) Recognition of the state is immediately followed by computation of the valences of the
near-by objects or states. (Valence means here the prediction of the reward associated with an object,
or more generally the prediction of the value of a state.) Based on those valences, a number of
candidate goals are chosen, which is the process of desire in its hot, interrupting form. Next, the agent
may choose one single goal and commit to it, which is also called intention. Then the agent starts
planning how to reach the committed goal, possibly by some kind of tree search, and executes the plan
obtained.
After finishing the execution of the plan, the agent observes the outcome, and based on it, an error such
as reward loss is computed. Any such error, especially frustration, may lead to suffering. Finally,
the computed error will be used in a learning process to guide future actions, which in a sense
closes the loop, as indicated by the green arrow. (Only an arrow from error computation to sensory
processing is drawn in the figure for simplicity, but actually the error is broadcast widely.) The
flowchart shows the prototypical sequence, but in reality there is, of course, more variability.
In the middle of the flowchart, we have “limitations of information-processing”, which influences all
the steps in the processing. While that has been the main theme of the whole book, here it also
provides an analogy to Buddhist philosophy which uses the term ignorance in connection with similar
conceptual schemes. Ignorance describes the fundamental underlying reason why the agent’s cognitive
apparatus creates so much suffering—thus adding to the adverse properties of the external world, as
shown in the previous flowchart. We have already seen various kinds of information processing
which might be called ignorant in the sense that they can be seen as faulty or lacking, and they
increase suffering. Thus, limitations of information processing could be seen as one definition of
“ignorance”. However, this Buddhist term could also be interpreted more literally in the sense of
our being ignorant of those limitations; a “meta-ignorance” so to say. We can thus consider such
forms of ignorance as 1) ignorance of the arbitrariness and even harmfulness of our rewards and
goals, 2) ignorance of the uncertainty and fuzziness of perceptions and concepts, 3) ignorance of
uncontrollability, and finally 4) ignorance that the simulation is not real—but this list is not meant to be
exhaustive.
In all these cases, we can claim, inspired by Buddhist philosophers, that there is some kind of a “mistake” in
our ordinary thinking and functioning of the brain. In particular, the mistake, or flaw, is about
misunderstanding where suffering comes from and how it can be reduced. Importantly, in contrast to
fundamental limitations of information processing, this “meta-ignorance” could be corrected. Most of this
book has actually been devoted to explaining what such ignorance consists of and how its different
forms lead to suffering or amplify it. So, in Figure 13.2, ignorance is naturally placed in the very
middle.
It should be noted that this series of processing steps is not only started by external stimuli (the sight
of something good) but also by internal simulation, which is another reason why the processing
constitutes something more like a cycle or a loop. For example, wandering thoughts, or almost
any kind of thoughts, trigger memories or predictions of sensory stimuli, and the cycle is launched
almost as if those stimuli were real. This is, however, not shown in the flowchart for the sake of
brevity.
An equation to compute frustration
While the flowcharts above help us understand the mechanisms behind suffering and even design interventions,
the real strength of a computational approach as taken in this book is that we can quantify things, at
least in principle. I don’t mean that we would necessarily be able to give a number measuring the
strength of suffering, but we can understand the connections between different quantities more
explicitly than with flowcharts. As the most powerful recapitulation of the theories of preceding
chapters, I next propose a simple equation that describes the amount of suffering experienced by
the agent. This will be the central approach in the next chapters, where we attempt to reduce
suffering.
The starting point for the equation is Chapter 5 (), where we defined suffering as reward loss,
that is, the difference between the expected reward and the obtained reward. (More generally, the
reward prediction error might be used.) This theory provides a quantitative basis for modelling
suffering. Reward loss is based on a simple mathematical formula, so we can look at the different
terms it contains. We can analyse how they influence reward loss, and how they could eventually be
manipulated. The equation we had in Chapter 5 was, however, very basic and did not take into
account any of the complexities of a real cognitive system that we have seen in later chapters. So, we
need to look at the different factors influencing reward loss in more detail and reformulate the
equation.
The first point to consider is that any quantities affecting reward loss need to be perceived by the agent.
While the difference between expected reward and the reward actually obtained is, in principle, the basis of
suffering, the difference cannot of course cause suffering by itself. It has to be computed—that is, perceived—by
the agent. So, we need to make a connection between limitations in perception and categorization on the one
hand, and frustration on the other. Due to such limitations, the perception of the actual reward is uncertain and
subjective, as explained in Chapter 10. Obviously, our expectations are subjective and may be overblown as
well. Yet, the agent can only compute the reward loss based on its own perceptions, on the information at its
disposal.
The second point is that as with any perception, the level of certainty of the error computation should also
be taken into account: If the perception of reward loss is particularly uncertain (say, because it is dark and you
cannot see what you get), this should reduce the effect of reward loss. It is common sense that if the agent is not
at all certain about what happened, it should not make any strong or far-reaching conclusions, and the error
signal should not be strong.
Furthermore, again following general rules governing perception outlined in Chapter 10, the intensity of the
perception of reward loss is modulated by the attention paid to it. Reward loss causes less suffering if little
attention is paid to it, for example, when one is distracted by something else—simply because you might not
even notice reward loss occurring. Paying attention to something may also be necessary for becoming conscious
of it.
Thus, the amount of attention paid to the reward loss must be included in the equation. There are also further
related phenomena which change the amount of frustration experienced: we may take the contents of such
simulation more or less seriously (Chapter 12), and we may find errors acceptable if we are deliberately trying to
learn something new. For simplicity, we include these aspects in the term called “amount of attention” being
paid to the reward loss, since not taking simulation seriously is related to not paying a lot of attention to
it.
The final important point is that error computation can happen many times, in particular in the case of
replay or planning, which means we perceive, or rather simulate, the same (possibly imaginary) reward loss
again and again (Chapter 9). If you replay an event just once in your head, the suffering is multiplied by two,
almost.
Taking all these aspects into account, we arrive at the following which I call the frustration
equation:
frustration =
perception of (the difference of expected and obtained reward)
× level of certainty attributed to that perception
× amount of attention paid to it
× how many times it is perceived or simulated
In this equation, we have four terms on the right-hand side, i.e. after the equality sign, multiplied by each other.
First, there is the basic formula of reward loss in parentheses. Thus it includes the amount of expected reward
and the amount of obtained reward, whose difference is computed. As with reward loss, if this difference
is negative, it is set to zero—if the obtained reward is greater than the expected, there is zero
frustration. But crucially, the reward loss here is modulated based on how it is perceived by the
agent.
Then, this perceived reward loss is multiplied by three modulating factors. We use here multiplication to
emphasize how the perceived reward loss may actually lead to no suffering at all if just one of
these modulating factors is zero. The modulating factors are: the level of certainty that the agent
attributes to the perception of reward loss (zero meaning absolute uncertainty, one meaning complete
certainty), the amount of attention paid to reward loss (including how seriously the contents of the
consciousness are taken), and finally the number of times the event is perceived (taking account
of the fact that it may be replayed or simulated in planning so that it is “perceived” more than
once).
It should be emphasized that such frustration happens on different time scales: from milliseconds to even years,
perhaps. In the smallest timescales, the suffering is likely to be much weaker than on longer time scales; see Chapter 7
() for discussion on this topic. The equation above is intended to be applied separately on different time
scales.
Another point that is useful to recall here is how we reformulated action selection as based on rewards only
in Chapter 5. While we often talk about goals and planning, for example in the flowchart in Figure 13.2, the
goals are now seen as something that the agent itself sets in order to maximize rewards. In particular,
Chapters 7 and 8 explained how an agent would predict that a certain state gives a big reward, then set it as a
goal state, and start planning for it—the same logic underlies Figure 13.2. Thus, goals are not something
inherent in the world, but rather a computational device used by the agent in order to maximize rewards. That
is why this equation uses the formalism of reward loss, instead of the basic formalism of frustration
of goals initially used in Chapter 3. Still, goals are implicitly present in this equation since the
expected reward is often the reward that reaching a certain goal would give (according to the agent’s
prediction).
Now, the essential point here is that all the terms on the right-hand side of the equation are
something that can be influenced or intervened on, at least to some extent. It is possible to develop
methods that change the terms on the right-hand side, thus changing the amount of frustration and
suffering. The next two chapters are largely an explanation and application of this equation from that
viewpoint.
In fact, so far, it might actually seem that the book has been just one big complaint. Suffering seems
unavoidable, a necessary consequence of intelligent information processing. However, in the following
final chapters, we will see a way forward: what an intelligent agent can do to actually reduce its
suffering.