Chapter 3
Frustration due to failed plan
In this chapter, I propose a first model where frustration is a fundamental mechanism for suffering. It is assumed
that an agent, whether a human or an AI, engages in planning of action sequences in order to get to a desired
goal state. A state is here an abstraction of the properties such as location, context, and possessions of the agent.
Frustration happens when the goal state is not reached in spite of the agent executing the planned sequence of
actions.
I start by emphasizing the great computational difficulty of such planning of action; it is one reason why
frustration happens. Another central concept here is wanting or desire, which is a complex phenomenon we will
return to several times in this book. As an initial definition, I consider desire as a computational process that
suggests goals for the planning system. Finally, I discuss the importance of committing to a single plan, even in
the presence of conflicting desires, based on Bratman’s concept of intention. This chapter lays out the
framework in simple, largely intuitive terms; the main terms and concepts will be greatly refined in later
chapters.
Agents, states, and goals
One may be tempted to think of an artificial intelligence as a system which just takes input, and processes
information. However, information-processing in itself will actually be rather pointless unless it
leads to some kind of visible output or action regarding the external world. In the very simplest
case, action can just mean printing some text on a computer screen, so this is not necessarily a big
leap.
In AI, the basic unit of analysis is often what is called an intelligent agent, i.e. a system which not only
processes information but also takes actions. In fact, the word “agent” literally means “one that acts”. An
intelligent agent can be artificial, such as a robot or an AI program, but the term also encompasses biological
agents, that is, animals. In one extreme, an artificial agent could be just a program inside a computer, working
in a virtual world with no physical body; actions would essentially consist of sending messages inside
an information network. In the other extreme of human-like artificial agents, it could be a robot
having a body with arms and legs; actions would include walking and grasping objects. In this
book, we will see examples of both extremes—in addition to agents that actually are animals or
humans.
Such an agent needs at least two things: perception and action selection. Perception is actually a tremendously
difficult task but we defer its discussion to Chapter 4 and especially Chapter 10. To begin with, we assume
perception is somehow satisfactorily performed, and consider the question of how the agent is to choose its
actions.
Perhaps the simplest and most intuitive approach to action selection is to think in terms of goals. This is an
introspectively compelling approach: We usually think of ourselves as acting because there are
certain goals that we try to reach. That may be why it has also been a dominant approach in the
history of AI, starting from around 1960. For example, a very simple thermostat has the goal of
keeping room temperature constant; a cleaning robot has the goal of removing dust and dirt from the
room.
The goals of humans are fundamentally determined by evolution, complemented by societal
and cultural influences. In this book, I simply use the word “evolution” for brevity to describe the
joint effect of biological evolution, culture and society. The assumption here is that the latter two
are ultimately derived from biological evolution, although this is of course a controversial point.
Fortunately, for the purposes of this book, the exact relationship between biology and culture is
irrelevant: What matters is that the goals that humans strive for are largely, even if sometimes very
indirectly, determined by some outside forces. Humans can set some intermediate goals, such as
getting a job, but those are usually in the service of final biological or societal goals, such as being
nourished or raising one’s social status. In the case of AI, in contrast, the goals are usually supplied
by its human designers. This may seem to be a fundamental difference between AI agents and
humans, but we will see in later chapters that it may not matter very much; the human designer
plays a role similar to evolution in terms of being an outside force. In any case, regardless of where
the goals come from, the way they are translated into action may still be rather similar in both
cases.
Modelling the world as states
In order to choose its actions, the agent should have some kind of a model of how the world works, where the
agent itself is seen as a part of the “world” modelled. The model expresses the agent’s beliefs of what the world
is typically like, and how the world changes from one moment to another, in particular as a function of the
actions the agent takes.
AI research uses a very abstract kind of a world model based on the concept of a state, where each possible
configuration of the world is one state. For example, if a cleaning robot is in the corner of a room, facing south,
and there is only a single speck of dust in the room, at exactly two meters east from the robot, that is one state,
we can call it state #1. If the agent finds itself 10 cm further to the west, it is in another state, say state #2;
likewise, if another speck of dust appears in the room, that means the agent is in state #3 (and if the speck of
dust appears and the agent is 10 cm further to the west, that is yet another state). In the simplest case,
such a world model has states which are categorical, or discrete; in other words, there is a finite
number of possible states. This is a very classical AI approach, but we will see alternatives in later
chapters.
Any effects of the agent’s actions can now be described in terms of moving from one state to another, called
state transitions. Indeed, in addition to knowing what the states of the world are like, the agent should know
something about the transitions between the states caused by its actions. If it finds itself in state #1 and decides
to move forward, does it find itself in state #2, or #47, or something else? If the agent’s world model can predict
the effects of its actions in terms of transitions from one state to another, it is ready to start taking
actions.
Using this formalism of states, the basic approach to action selection is that one of the states is
designated as the goal state, by some mechanisms to be specified. The agent then uses its
capabilities to reach the goal state, starting from its current state. That is surprisingly difficult,
usually requiring complicated computation called planning, which is a central concept we consider
next.
Planning action sequences, and its great difficulty
The fundamental problem in action selection is that you must actually select sequences of short actions. For
example, if the agent in question is you, and you decide to get something from the fridge in the kitchen, you
need to take a step with your left foot, take a step with your right foot, repeatedly, until you finally can open the
fridge door—which consists of several actions such as: raise your arm, grab the handle, pull it down,
pull the door, and so on. In some cases, you may easily know how to choose the right sequence,
but it is not easy at all in many cases. For programming AI, this has turned out to be quite a
challenge.
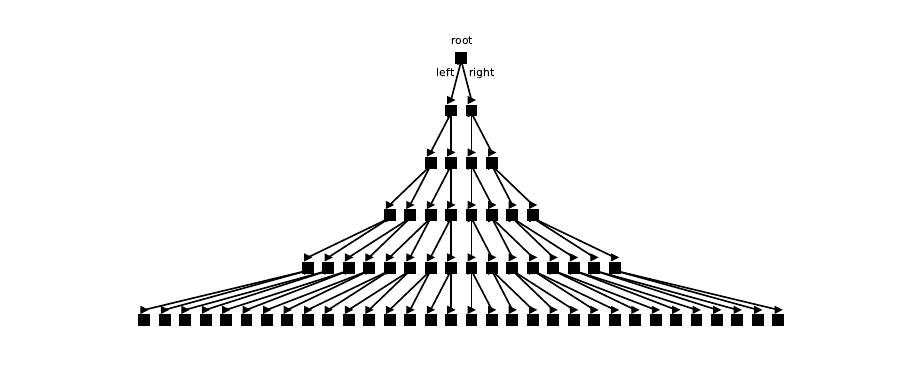
This is known as the problem of planning in AI. Using the formalism of world states, action sequences can be
represented graphically as what is called a tree (Figure 3.1). The “root” of the tree represents the state you’re in
at the moment. Any action leads to a branching of the tree, and depending on the action, you will find yourself
on any of the new branches. (In this figure, taking an action means moving down in the tree, and we
assume for simplicity that there are just two actions you can take at any time point). At the end of a
given number of actions, or levels in the tree, you find yourselves at one of those states which are
depicted at the outer “leaves” of the tree. Of course, the tree continues almost forever since you
can take new actions all the time, but to keep things manageable, we consider a tree of a limited
depth.
Let’s now assume that the agent has been given a goal state by the programmer. It would be one of
the states at the lowest level of the tree. The central concept here is tree search; many classical
AI theories see intelligence as a search for paths, or action sequences, among a huge number of
possible paths in the action tree. In particular, the planning system finds a path which leads from
the current state to the goal state. Such search may look simple, but the problem is that with
such paths or action sequences, the number of possibilities grows exponentially. If you have, at
any one time point, just two different actions to choose from, then after 30 such time points you
have more than a billion (more exactly 2 to the power of 30) possible action sequences to choose
from. What’s worse is that typically an AI would have many more than just two possible courses
of action at any one point. The computations involved easily go beyond the capacity of even the
biggest computers or brains. So, it may be impossible to “look ahead” more than a couple of steps in
time.
The difficulty of such planning may be difficult for humans to understand since evolution has provided
various tricks and algorithms that solve the problem quite well, as we will see below. We may only be able to
grasp the difficulty of planning in some slightly artificial examples such as the search tree above. One of the
more realistic examples would be planning a route between two points. Say you find yourself in a
random location in Paris and want to go to the Eiffel Tower using public transportation. Even if
you remembered every detail of the metro map as well as the geography of Paris itself, you would
still need quite a lot of computation, in the form we would usually call “thinking”. Which metro
station should I walk to, or should I perhaps use the bus? What is the best itinerary once inside
the metro station? It is not surprising that people tend to use mobile phone apps to solve this
problem.
Board games are an extreme example of the difficulty of planning. Humans playing chess have great
difficulties in thinking more than one or two moves ahead. The search tree has a lot of branches at every move
because there are so many moves you can take. Even worse, your opponent can do many different things. (The
uncertainty regarding what your opponent will do further adds to the complexity, but that is another
story.)
A lot of the activity we would casually call thinking is actually some kind of planning. If you are thinking
about where to go shopping for a new electronic gizmo, or how to reply to a difficult message from your friend,
you are considering different courses of action. Basically, you’re going through some of the paths in the search
tree. Often, such thinking or planning happens quite involuntarily, even when you’re supposed to be doing
something else, a topic to which we will return in Chapter 9.
Frustration as not reaching planned goal
Equipped with this basic framework for action selection, we are ready to define frustration in its most basic
form. We start by considering one part of the Buddha’s definition of suffering mentioned above: “not to
get what one wants”: This is in fact a typical dictionary definition of frustration. To achieve a
deeper computational understanding of the phenomenon, we integrate this with the framework of
planning.
Just like AI, complex organisms such as humans engage in planning: Based on their perception of the current
environment, they try to achieve various goals by some kind of tree seach. For such organisms, it is vital to know
if a plan failed, so that they can re-plan their behaviour, and even learn to plan better in the future, as will be
considered in detail in the following chapters.
We thus formulate the basic case of frustration as not reaching a goal that one had planned for, and the ensuing
error signal. Sometimes frustration rather refers to the resulting unpleasant mental state; that is, frustration
refers to the actual suffering instead of the cause for suffering. I use frustration in both meanings in this
book.
This initial definition will be refined and generalized in later chapters. In later chapters, we will see how
central error signals are to any kind of learning. For example, a neural network that learns to classify inputs, or
predict the future, is essentially minimizing an objective function which gives the error in such
classification or prediction. Frustration can be seen as a special case of such error signalling: It signals
that an action plan failed. In complex organisms like humans, which are constantly engaged in
planning, frustration is an extremely important learning signal, and the basis of a large part of the
suffering.
Defining desire as a goal-suggesting mechanism
However, there is a slight inconsistency here: Frustration was actually defined as not getting what one wants in
Chapter 2. How is this related to our computational formulation based on planning above? In other words, what
exactly is wanting, or desire, in a computational framework like ours?
In everyday intuitive thinking, action selection is indeed supposed to be based on wanting, or desires: An
agent takes an action because it wants something, and it thinks it is reasonably likely to achieve or
obtain it by that action. I choose to go to the fridge because I want orange juice. However, the
account earlier in this chapter made no reference to the concepts of desire or wanting. In AI, the term
“desire”, which I consider synonymous with “wanting”, can actually be used in a couple of different
meanings.
In the very simplest definition, if the agent has a goal to plan for, one could simply say the agent “wants” to
reach the goal state; desires would essentially be the same as goals. In such a meaning, desire is a kind of purely
rational, “cold” evaluation of states and objects. However, the word has many more connotations in everyday
language. Desire also has an affective aspect we could call “hot”, in which we are “burning with desire”, unable
to resist it.
A definition that is a bit more in the direction of “hot” can be obtained by considering desire
as a specific computational process inside the agent. To begin with, desire has been defined as a
“psychological state of motivation for a specific stimulus or experience that is anticipated to be
rewarding”.
While a “psychological state” may mean different things, here we consider a state as something where a particular
kind of information processing is performed—another meaning would be related to conscious experience which we
treat in Chapter 12. In practical terms, desire is often triggered by the perception of something that is rewarding to
possess.
Such perception of an object often means that the agent should be able to get the object after a
rather short and uncomplicated action sequence: If you see something, it is likely to be within
reach.
From the viewpoint of information-processing, we thus define desire as: A computational process
suggesting as the goal a state that is anticipated to be rewarding and seems sufficiently easily attainable
from the current state. I want to emphasize that I am considering desire as a particular form of
information-processing: Desire is not simply about preferring chocolate to beetroot, nor is it merely an abstract
explanation of the behaviour where I grab a chocolate bar. It is sophisticated computation that is
one step in the highly complex process that translates preferences into planning and, finally, into
action.
The starting point for that processing is that your perceptual system, together with further computations,
estimates that from the current state, you can relatively easily get into a state of high reward—the exact
formalism for “rewards” will be introduced in Chapter 5. This realization will trigger, if you are properly
programmed, further computational processes that will try to get you in that desired state by suggesting it as
the goal for your planning system. When all this happens, you want the new state, or have a desire for that new
state, according to the definition just given. For example, if chocolate appears in your visual field, your brain will
compute that the state where you possess the chocolate is relatively easy to reach, and produces high reward;
so it will choose the chocolate-possessing state as a possible goal and input that to the planning
system.
Therefore, the definition of desire just given shows how the intuitive definition of frustration as not getting
what one wants and the computational definition of not reaching the goal are essentially the same thing. This
definition also solves a question which many readers must have asked while reading this chapter: Where
do the goals for planning come from? In a very simple AI, there might be just a single goal, or
a small set, defined by the programmer. But for a sophisticated agent, that is certainly not the
case: The number of possible goals for a human agent is almost infinite. Here, we define desire as a
computational process that suggests new goals to the planning system, and thus this is where the goals
come from. (More details on how the desire system could actually choose goals will be given in
Chapter 7, which also considers a different aspect of desire related to its interrupting and irresistible
quality.)
A closely related concept is aversion, which is in a sense the opposite of desire. However, from a
mathematical viewpoint, aversion is very similar to desire: The agent wants to avoid a certain state (or states)
and wants to be in some other state. For example, the agent wants to be in a state in which some
unpleasant object is not present. Thus, it is really a case of wanting and desire, just framed in a more
negative way. I do not use the term aversion very much in this book since it is mathematically
contained in the concept of desire. Whenever I use the word “desire”, aversion is understood to be
included.
Intention as commitment to a goal
We have seen that a desire is something that suggests the goal of the agent. Note that I’m not saying that desire
sets the goal, but it suggests a goal to the planning system. This difference is important because there
might be conflicting goals; you don’t grab the chocolate every time you have desire for it. The
agent needs to choose between different possible objects of desire. This is particularly important
because attaining the desired goal state often takes time: The whole plan has to be executed from
beginning till end, and new temptations—activations of the desire system which suggests new states
as possible goals—may arise meanwhile. Some method of arbitrating between different desires is
necessary.
Suppose the desired state for a monkey is one where the monkey has eaten a banana. The banana is
currently high up the tree which is in front of the monkey, so the monkey needs to perform a series of actions to
reach that desired state: it must climb up the tree, take the banana, peel it, and eat it. The monkey must thus
figure out the right sequence of actions to reach the desired state— this is just the planning problem discussed
above—and launch its execution.
But, suppose the monkey suddenly notices another banana in another tree near-by. Its desire
system may suggest that the new banana looks like an interesting goal. The monkey now faces a new
problem: Continue with the current banana plan, or set the new banana as a new goal? It may be
common sense that after the monkey has launched the first banana plan, the monkey should, in
most cases, persist with that plan until the end. The monkey should not start pondering, halfway
up the first tree, whether it actually prefers to get the other banana in the other tree, even if it
looks a bit sweeter. The key idea here is commitment to the current plan, and thus to a specific
goal.
The reason why commitment is important comes fundamentally from computational considerations. Since
computing a plan for a given goal takes a lot of computational resources, it would be wasteful to abandon it too
easily in favour of a new goal. It might be wasteful even to just consider alternative goals seriously,
because that would entail computing possible plans to achieve all those goals. The agent must
settle on one goal and one plan and execute it without spending energy thinking about competing
goals.
Another utility of commitment is that the agent has a better idea of what will happen in the future, and it
can start planning further actions, e.g. a plan on what to do after reaching the goal of the current plan. So,
while the monkey is climbing up the tree, it is a good idea to start thinking about the best way of getting the
banana in the other tree after having grabbed the first banana. That would be planning the long-term future
after completing the execution of the current plan; perhaps the monkey can directly jump to the other
tree from the location of the first banana. Such long-term plans would obviously collapse if the
monkey didn’t first get the first banana due to lack of commitment, being distracted by yet another
thing.
Commitment to a goal is also called intention in AI, and leads to an influential AI framework called
belief-desire-intention (BDI) theory. Belief refers to the results of perception, which give rise to desires. BDI
theory argues for the importance of intentions, as commitment to specific goals, on top of beliefs and
desires.
Of course, there must be some limits to such commitment: If something unexpected happens, the goal may need
to be changed. If a tiger appears, the monkey cannot persist with the goal of just eating a banana. Chapter 8
will consider the importance of emotions such as the fear aroused by the tiger as one computational
solution.
The concept of intentions has important implications for suffering, as will be discussed in detail in later
chapters. To put it simply, I will propose that frustration and suffering are stronger if an intention is frustrated,
as opposed to frustration of a simple desire as in the basic definition.
Heuristics can help in planning
Still, we have not yet solved the central problem regarding the planning system. We saw above
that because of the huge number of possible paths in planning, a complete tree search is quite
impossible in most cases. Is planning then impossible? Fortunately, there are a couple of tricks and
approximations that can be used to find reasonable solutions to the planning problem. Here we first consider
what is called heuristics, while a more sophisticated solution is given in the next two chapters.
These solutions also have important implications for the definition of frustration, and understanding
suffering.
A heuristic means some kind of method for evaluating each state in the search tree, usually
by giving a number that approximately quantifies how good it is, i.e. how close to the goal it is.
The point is that a heuristic does not need to be exact—if it were, we would have already solved
the problem. It just gives a useful estimate, or at least an educated guess, of how “good” a state
is.
Sometimes, it is quite simple to program some heuristics in an AI agent. Consider a robot whose goal is to
get some orange juice from the fridge and deliver it to its human master. Clearly, when the robot
has orange juice in its hand, it is rather close to the goal; we could express that by a numerical
value of, say, 8. If it is, in addition, close to its master, it is very close to its goal, say a value of
9. The most important thing is, however, to assist the robot at the beginning of the search, and
that is where the heuristic is the most powerful. So, we could say that when the robot is close to
the fridge, the heuristic gives a value of 2. When it has opened the fridge, the value is 3, and so
on.
With such heuristics, the search task would not require that much computation. The robot just has to figure
out how to get to some easily reachable state with a higher heuristic than the current state. Assuming the robot
starts at an initial state with heuristic value 0, it would quickly compute that what it can achieve
rather easily is a state of heuristic value of 2, by going to the fridge. The length of the tree to be
searched for is thus much shorter, i.e. much fewer actions steps need to be taken in that subproblem.
Once there, it only has to figure out how to open the door to get to the state with heuristic value
of 3. Thus, the heuristic essentially divides a long complex search task into smaller parts. Each
of these parts is quite short, so the exponential growth of the number of branches is much less
severe.
There is one famous success of AI where such tree search with heuristics was hugely successful: The Deep Blue chess-playing
machine,
which beat the chess world champion, for the first time, in 1997. Its main strength was the huge number of
sequences of moves (i.e. paths in a search tree) it was able to consider, largely because it was based on
purpose-built, highly parallel hardware that was particularly good in such search computations on the
chessboard. But its success was also due to clever heuristics, the main one being called “piece placement”,
computed as the sum of the predetermined piece values with adjustments for location, telling how good a certain
position is. (In chess, the state is the configuration of all the pieces on the board, and called a “position” in their
jargon.)
Evolution has also programmed a multitude of heuristics in animals. Think about the smell of cheese for a
rat. The stronger the smell, the closer the rat is to the cheese. The rat just needs to maximize the smell, as it
were, and it will find the cheese. No complex planning is needed—unless there are obstacles in the
way.
However, the crucial problem is how to find such heuristics for a given planning problem. In fact, this is a
very difficult problem, and there is no general method for designing them. Nevertheless, there is a general
principle which has been found tremendously useful in modern AI, and can be used here as well: learning.
Modern AI is very much about using learning from data as an approach to solving the problem of programming
intelligence. In the case of planning, it turns out that a general approach for solving the planning problem is to
learn to rate the states, i.e. learn to associate some kind of heuristic to each world state. This is why in the next
two chapters, we delve into the theory of machine learning. Its specific application to solving the planning
problem will be considered in Chapter 5, where we also consider a different approach to defining
frustration.